1 什麼是文字挖掘?
文字挖掘是資訊挖掘的一個研究分支,用於基於文字資訊的知識發現。文字挖掘的準備工作由文字收集、文字分析和特徵修剪三個步驟組成。目前研究和應用最多的幾種文字挖掘技術有:檔案聚類、檔案分類和摘要抽取。
2 什麼是自然語言處理?
自然語言處理是電腦科學領域與人工智慧領域中的一個重要方向。它研究人與計算機之間用自然語言進行有效通訊的理論和方法。融語言學、電腦科學、數學等於一體的科學。
自然語言處理原理:形式化描述-數學模型演演算法化-程式化-實用化
語音的自動合成與識別、機器翻譯、自然語言理解、人機對話、資訊檢索、文字分類、自動文摘等。

3 常用中文分詞?
中文文字詞與詞之間沒有像英文那樣有空格分隔,因此很多時候中文文字操作都涉及切詞,這裡整理了一些中文分詞工具。
StanfordNLP(直接使用CRF 的方法,特徵視窗為5。)漢語分詞工具(個人推薦)
哈工大語言雲
庖丁解牛分詞
盤古分詞 ICTCLAS(中科院)漢語詞法分析系統
IKAnalyzer(Luence專案下,基於java的)
FudanNLP(復旦大學)
4 詞性標註方法?句法分析方法?
原理描述:標註一篇文章中的句子,即陳述句標註,使用標註方法BIO標註。則觀察序列X就是一個語料庫(此處假設一篇文章,x代表文章中的每一句,X是x的集合),標識序列Y是BIO,即對應X序列的識別,從而可以根據條件機率P(標註|句子),推測出正確的句子標註。
顯然,這裡針對的是序列狀態,即CRF是用來標註或劃分序列結構資料的機率化結構模型,CRF可以看作無向圖模型或者馬爾科夫隨機場。 用過CRF的都知道,CRF是一個序列標註模型,指的是把一個詞序列的每個詞打上一個標記。一般透過,在詞的左右開一個小視窗,根據視窗裡面的詞,和待標註詞語來實現特徵模板的提取。最後透過特徵的組合決定需要打的tag是什麼。
5 命名物體識別?三種主流演演算法,CRF,字典法和混合方法
1 CRF:在CRF for Chinese NER這個任務中,提取的特徵大多是該詞是否為中國人名姓氏用字,該詞是否為中國人名名字用字之類的,True or false的特徵。所以一個可靠的百家姓的表就十分重要啦~在國內學者做的諸多實驗中,效果最好的人名可以F1測度達到90%,最差的機構名達到85%。
2 字典法:在NER中就是把每個字都當開頭的字放到trie-tree中查一遍,查到了就是NE。中文的trie-tree需要進行雜湊,因為中文字元太多了,不像英文就26個。
3 對六類不同的命名物體採取不一樣的手段進行處理,例如對於人名,進行字級別的條件機率計算。 中文:哈工大(語言雲)上海交大 英文:stanfordNER等
6 基於主動學習的中醫文獻句法識別研究
6.1 語料庫知識?
語料庫作為一個或者多個應用標的而專門收集的,有一定結構的、有代表的、可被計算機程式檢索的、具有一定規模的語料的集合。
語料庫劃分:① 時間劃分② 加工深度劃分:標註語料庫和非標註語料庫③ 結構劃分⑤ 語種劃分⑥ 動態更新程度劃分:參考語料庫和監控語料庫
語料庫構建原則:① 代表性② 結構性③ 平衡性④ 規模性⑤ 元資料:元資料對
語料標註的優缺點
① 優點: 研究方便。可重用、功能多樣性、分析清晰。
② 缺點: 語料不客觀(手工標註準確率高而一致性差,自動或者半自動標註一致性高而準確率差)、標註不一致、準確率低
6.2 條件隨機場解決標註問題?
條件隨機場用於序列標註,中文分詞、中文人名識別和歧義消解等自然語言處理中,表現出很好的效果。原理是:對給定的觀察序列和標註序列,建立條件機率模型。條件隨機場可用於不同預測問題,其學習方法通常是極大似然估計。
我愛中國,進行序列標註案例講解條件隨機場。(規則模型和統計模型問題)
條件隨機場模型也需要解決三個基本問題:特徵的選擇(表示第i個觀察值為“愛”時,相對yi,yi-1的標記分別是B,I),引數訓練和解碼。
6.3 隱馬爾可夫模型
應用:詞類標註、語音識別、區域性句法剖析、語塊分析、命名物體識別、資訊抽取等。應用於自然科學、工程技術、生物科技、公用事業、通道編碼等多個領域。
馬爾可夫鏈:在隨機過程中,每個語言符號的出現機率不相互獨立,每個隨機試驗的當前狀態依賴於此前狀態,這種鏈就是馬爾可夫鏈。
多元馬爾科夫鏈:考慮前一個語言符號對後一個語言符號出現機率的影響,這樣得出的語言成分的鏈叫做一重馬爾可夫鏈,也是二元語法。二重馬爾可夫鏈,也是三元語法,三重馬爾可夫鏈,也是四元語法
隱馬爾可夫模型思想的三個問題
問題1(似然度問題):給一個HMM λ=(A,B) 和一個觀察序列O,確定觀察序列的似然度問題 P(O|λ) 。(向前演演算法解決)
問題2(解碼問題):給定一個觀察序列O和一個HMM λ=(A,B),找出最好的隱藏狀態序列Q。(維特比演演算法解決)
問題3(學習問題):給定一個觀察序列O和一個HMM中的狀態集合,自動學習HMM的引數A和B。(向前向後演演算法解決)
6.4 Viterbi演演算法解碼
思路:
1 計算時間步1的維特比機率
2 計算時間步2的維特比機率,在(1) 基礎計算
3 計算時間步3的維特比機率,在(2) 基礎計算
4 維特比反向追蹤路徑
維特比演演算法與向前演演算法的區別:
(1)維特比演演算法要在前面路徑的機率中選擇最大值,而向前演演算法則計算其總和,除此之外,維特比演演算法和向前演演算法一樣。
(2)維特比演演算法有反向指標,尋找隱藏狀態路徑,而向前演演算法沒有反向指標。
HMM和維特比演演算法解決隨機詞類標註問題,利用Viterbi演演算法的中文句法標註
6.5 序列標註方法 參照上面詞性標註
6.6 模型評價方法
模型:方法=模型+策略+演演算法
模型問題涉及:訓練誤差、測試誤差、過擬合等問題。通常將學習方法對未知資料的預測能力稱為泛化能力。
模型評價引數:
準確率P=識別正確的數量/全部識別出的數量
錯誤率 =識別錯誤的數量/全部識別出的數量
精度=識別正確正的數量/識別正確的數量
召回率R=識別正確的數量/全部正確的總量(識別出+識別不出的)
F度量=2PR/(P+R)
資料正負均衡適合準確率 資料不均適合召回率,精度,F度量
幾種模型評估的方法:
K-折交叉驗證、隨機二次抽樣評估等 ROC曲線評價兩個模型好壞
7 基於文字處理技術的研究生英語等級考試詞彙表構建系統
完成對2002–2010年17套GET真題的核心單詞抽取。其中包括資料清洗,停用詞處理,分詞,詞頻統計,排序等常用方法。真題算是結構化資料,有一定規則,比較容易處理。此過程其實就是資料清洗過程)最後把所有單詞集中彙總,再去除如:a/an/of/on/frist等停用詞(中文文字處理也需要對停用詞處理,諸如:的,地,是等)。處理好的單詞進行去重和詞頻統計,最後再利用網路工具對英語翻譯。然後根據詞頻排序。
7.1 Apache Tika?
Apache Tika內容抽取工具,其強大之處在於可以處理各種檔案,另外節約您更多的時間用來做重要的事情。
Tika是一個內容分析工具,自帶全面的parser工具類,能解析基本所有常見格式的檔案
Tika的功能:•檔案型別檢測 •內容提取 •元資料提取 •語言檢測
7.2 文字詞頻統計?詞頻排序方法?
演演算法思想:
1 歷年(2002—2010年)GET考試真題,檔案格式不一。網上收集
2 對所有格式不一的檔案進行統計處理成txt檔案,格式化(去除漢字/標點/空格等非英文單詞)和去除停用詞(去除891個停用詞)處理。
3 對清洗後的單詞進行去重和詞頻統計,透過Map統計詞頻,物體儲存:單詞-詞頻。(陣列也可以,只是面對特別大的資料,陣列存在越界問題)。排序:根據詞頻或者字母
4 提取核心詞彙,大於5的和小於25次的資料,可以自己制定閾值。遍歷list串列時候,透過獲取物體的詞頻屬性控制選取詞彙表尺寸。
5 最後一步,中英文翻譯。
8 樸素貝葉斯模型的文字分類器的設計與實現
8.1 樸素貝葉斯公式
0:喜悅 1:憤怒 2:厭惡 3:低落
8.2 樸素貝葉斯原理
–>訓練文字預處理,構造分類器。(即對貝葉斯公式實現文字分類引數值的求解,暫時不理解沒關係,下文詳解)
–>構造預測分類函式
–>對測試資料預處理
–>使用分類器分類
對於一個新的訓練檔案d,究竟屬於如上四個類別的哪個類別?我們可以根據貝葉斯公式,只是此刻變化成具體的物件。
> P( Category | Document):測試檔案屬於某類的機率
> P( Category)):從檔案空間中隨機抽取一個檔案d,它屬於類別c的機率。(某類檔案數目/總檔案數目)
> (P ( Document | Category ):檔案d對於給定類c的機率(某類下檔案中單詞數/某類中總的單詞數)
> P(Document):從檔案空間中隨機抽取一個檔案d的機率(對於每個類別都一樣,可以忽略不計算。此時為求最大似然機率)
> C(d)=argmax {P(C_i)*P(d|c_i)}:求出近似的貝葉斯每個類別的機率,比較獲取最大的機率,此時檔案歸為最大機率的一類,分類成功。
綜述
1. 事先收集處理資料集(涉及網路爬蟲和中文切詞,特徵選取)
2. 預處理:(去掉停用詞,移除頻數過小的詞彙【根據具體情況】)
3. 實驗過程:
資料集分兩部分(3:7):30%作為測試集,70%作為訓練集
增加置信度:10-折交叉驗證(整個資料集分為10等份,9份合併為訓練集,餘下1份作為測試集。一共執行10遍,取平均值作為分類結果)優缺點對比分析
4. 評價標準:
宏評價&微評價
平滑因子
8.3 生產模型與判別模型區別
1)生產式模型:直接對聯合分佈進行建模,如:隱馬爾科夫模型、馬爾科夫隨機場等
2)判別式模型:對條件分佈進行建模,如:條件隨機場、支援向量機、邏輯回歸等。
生成模型優點:1)由聯合分佈2)收斂速度比較快。3)能夠應付隱變數。 缺點:為了估算準確,樣本量和計算量大,樣本數目較多時候不建議使用。
判別模型優點:1)計算和樣本數量少。2)準確率高。缺點:收斂慢,不能針對隱變數。
8.4
ROC曲線
ROC曲線又叫接受者操作特徵曲線,比較學習器模型好壞視覺化工具,橫坐標引數假正例率,縱坐標引數是真正例率。曲線越靠近對角線(隨機猜測線)模型越不好。
好的模型,真正比例比較多,曲線應是陡峭的從0開始上升,後來遇到真正比例越來越少,假正比例元組越來越多,曲線平緩變的更加水平。完全正確的模型面積為1
9 統計學知識
資訊圖形化(餅圖,線形圖等)
集中趨勢度量(平均值 中位數 眾數 方差等)
機率
排列組合
分佈(幾何二項泊松正態卡方)
統計抽樣
樣本估計
假設檢驗
回歸
10 stanfordNLP
句子理解、自動問答系統、機器翻譯、句法分析、標註、情感分析、文字和視覺場景和模型, 以及自然語言處理數字人文社會科學中的應用和計算。
11 APache OpenNLP
Apache的OpenNLP庫是自然語言文字的處理基於機器學習的工具包。它支援最常見的NLP任務,如斷詞,句子切分,部分詞性標註,命名物體提取,分塊,解析和指代消解。
句子探測器:句子檢測器是用於檢測句子邊界
標記生成器:該OpenNLP斷詞段輸入字元序列為標記。常是這是由空格分隔的單詞,但也有例外。
名稱搜尋:名稱查詢器可檢測文字命名物體和數字。
POS標註器:該OpenNLP POS標註器使用的機率模型來預測正確的POS標記出了標簽組。
細節化:文字分塊由除以單詞句法相關部分,如名詞基,動詞基的文字,但沒有指定其內部結構,也沒有其在主句作用。
分析器:嘗試解析器最簡單的方法是在命令列工具。該工具僅用於演示和測試。請從我們網站上的英文分塊
12 Lucene
Lucene是一個基於Java的全文資訊檢索工具包,它不是一個完整的搜尋應用程式,而是為你的應用程式提供索引和搜尋功能。Lucene 目前是 Apache Jakarta(雅加達) 家族中的一個 開源專案。也是目前最為流行的基於Java開源全文檢索工具包。
目前已經有很多應用程式的搜尋功能是基於 Lucene ,比如Eclipse 幫助系統的搜尋功能。Lucene能夠為文字型別的數 據建立索引,所以你只要把你要索引的資料格式轉化的文字格式,Lucene 就能對你的檔案進行索引和搜尋。
13 Apache Solr
Solr它是一種開放原始碼的、基於 Lucene Java 的搜尋伺服器。Solr 提供了層面搜尋(就是統計)、命中醒目顯示並且支援多種輸出格式。它易於安裝和配置, 而且附帶了一個基於HTTP 的管理介面。可以使用 Solr 的表現優異的基本搜尋功能,也可以對它進行擴充套件從而滿足企業的需要。
Solr的特性包括:
•高階的全文搜尋功能
•專為高通量的網路流量進行的最佳化
•基於開放介面(XML和HTTP)的標準
•綜合的HTML管理介面
•可伸縮性-能夠有效地複製到另外一個Solr搜尋伺服器
•使用XML配置達到靈活性和適配性
•可擴充套件的外掛體系 solr中文分詞
14 機器學習降維
主要特徵選取、隨機森林、主成分分析、線性降維
15 領域本體構建方法
1 確定領域本體的專業領域和範疇
2 考慮復用現有的本體
3 列出本體涉及領域中的重要術語
4 定義分類概念和概念分類層次
5 定義概念之間的關係
16 構建領域本體的知識工程方法:
主要特點:本體更強調共享、重用,可以為不同系統提供一種統一的語言,因此本體構建的工程性更為明顯。
方法:目前為止,本體工程中比較有名的幾種方法包括TOVE 法、Methontology方法、骨架法、IDEF-5法和七步法等。(大多是手工構建領域本體)
現狀: 由於本體工程到目前為止仍處於相對不成熟的階段,領域本體的建設還處於探索期,因此構建過程中還存在著很多問題。
方法成熟度: 以上常用方法的依次為:七步法、Methontology方法、IDEF-5法、TOVE法、骨架法。
17 特徵工程
1 特徵工程是什麼?
資料和特徵決定了機器學習的上限,而模型和演演算法只是逼近這個上限而已。特徵工程本質是一項工程活動,目的是最大限度地從原始資料中提取特徵以供演演算法和模型使用。透過總結和歸納,人們認為特徵工程包括以下方面:
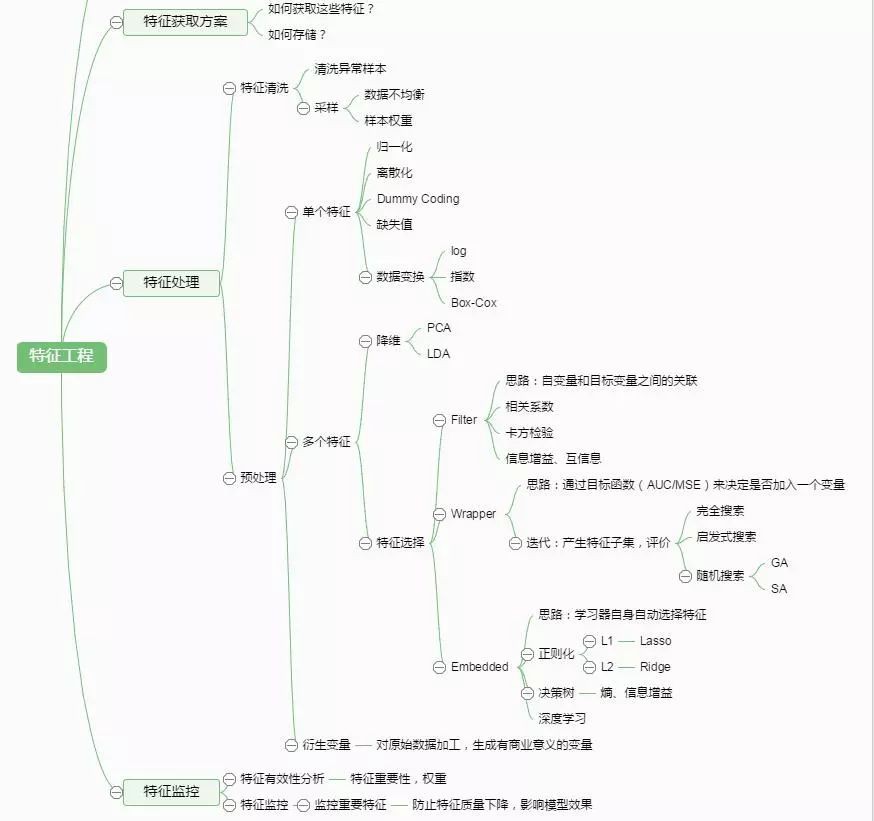
特徵處理是特徵工程的核心部分,特徵處理方法包括資料預處理,特徵選擇,降維等。
2 特徵提取:特徵提取是指將機器學習演演算法不能識別的原始資料轉化為演演算法可以識別的特徵的過程。
實體解析:文字是由一系列文字組成的,這些文字在經過分詞後會形成一個詞語集合,對於這些詞語集合(原始資料),機器學習演演算法是不能直接使用的,我們需要將它們轉化成機器學習演演算法可以識別的數值特徵(固定長度的向量表示),然後再交給機器學習的演演算法進行操作。再比如說,圖片是由一系列畫素點構(原始資料)成的,這些畫素點本身無法被機器學習演演算法直接使用,但是如果將這些畫素點轉化成矩陣的形式(數值特徵),那麼機器學習演演算法就可以使用了。特徵提取實際上是把原始資料轉化為機器學習演演算法可以識別的數值特徵的過程,不存在降維的概念,特徵提取不需要理會這些特徵是否是有用的;而特徵選擇是在提取出來的特徵中選擇最優的一個特徵子集。
文字分類特徵提取步驟:
假設一個語料庫裡包含了很多文章,在對每篇文章作了分詞之後,可以把每篇文章看作詞語的集合。然後將每篇文章作為資料來訓練分類模型,但是這些原始資料是一些詞語並且每篇文章詞語個數不一樣,無法直接被機器學習演演算法所使用,機器學習演演算法需要的是定長的數值化的特徵。因此,我們要做的就是把這些原始資料數值化,這就對應了特徵提取。如何做呢?
-
對訓練資料集的每篇文章,我們進行詞語的統計,以形成一個詞典向量。詞典向量裡包含了訓練資料裡的所有詞語(假設停用詞已去除),且每個詞語代表詞典向量中的一個元素。
-
在經過第一步的處理後,每篇文章都可以用詞典向量來表示。這樣一來,每篇文章都可以被看作是元素相同且長度相同的向量,不同的文章具有不同的向量值。這也就是表示文字的詞袋模型(bag of words)。
-
針對於特定的文章,如何給表示它的向量的每一個元素賦值呢?最簡單直接的辦法就是0-1法了。簡單來說,對於每一篇文章,我們掃描它的詞語集合,如果某一個詞語出現在了詞典中,那麼該詞語在詞典向量中對應的元素置為1,否則為0。
在經過上面三步之後,特徵提取就完成了。對於每一篇文章,其中必然包含了大量無關的特徵,而如何去除這些無關的特徵,就是特徵選擇要做的事情了。
3 資料預處理:未經處理的特徵,這時的特徵可能有以下問題:(標準化的前提是特徵值服從正態分佈,標準化後,其轉換成標準正態分佈)
-
特徵的規格不一樣。無量綱化可以解決。
-
資訊冗餘:對於某些定量特徵,其包含的有效資訊為區間劃分,例如學習成績,假若只關心“及格”或不“及格”,那麼需要將定量的考分,轉換成“1”和“0”表示及格和未及格。二值化可以解決這一問題。
-
定性特徵不能直接使用:某些機器學習演演算法和模型只能接受定量特徵的輸入,那麼需要將定性特徵轉換為定量特徵。假設有N種定性值,則將這一個特徵擴充套件為N種特徵,當原始特徵值為第i種定性值時,第i個擴充套件特徵賦值為1,其他擴充套件特徵賦值為0。
-
存在缺失值:缺失值需要補充。
-
資訊利用率低:不同的機器學習演演算法和模型對資料中資訊的利用是不同的。
使用sklearn中的preproccessing庫來進行資料預處理,可以改寫以上問題的解決方案。
4 特徵選擇:當資料預處理完成後,我們需要選擇有意義的特徵輸入機器學習的演演算法和模型進行訓練。特徵選擇是指去掉無關特徵,保留相關特徵的過程,也可以認為是從所有的特徵中選擇一個最好的特徵子集。特徵選擇本質上可以認為是降維的過程。
1)Filter(過濾法):按照發散性或者相關性對各個特徵進行評分,設定閾值或者待選擇閾值的個數,選擇特徵。如:方差選擇法、相關係數法、卡方檢驗法、互資訊法
方差選擇法:使用方差選擇法,先要計算各個特徵的方差,然後根據閾值,選擇方差大於閾值的特徵。
相關係數法:使用相關係數法,先要計算各個特徵對標的值的相關係數以及相關係數的P值。
卡方檢驗法:經典的卡方檢驗是檢驗定性自變數對定性因變數的相關性。假設自變數有N種取值,因變數有M種取值,考慮自變數等於i且因變數等於j的樣本頻數的觀察值與期望的差距,構建統計量。
互資訊法: 經典的互資訊也是評價定性自變數對定性因變數的相關性的。
2)Wrapper(包裝法):根據標的函式(通常是預測效果評分),每次選擇若干特徵,或者排除若干特徵。如:遞迴特徵消除法
遞迴特徵消除法:遞迴消除特徵法使用一個基模型來進行多輪訓練,每輪訓練後,消除若干權值繫數的特徵,再基於新的特徵集進行下一輪訓練。
3)Embedded(嵌入法):先使用某些機器學習的演演算法和模型進行訓練,得到各個特徵的權值繫數,根據繫數從大到小選擇特徵。類似於Filter方法,但是是透過訓練來確定特徵的優劣。
基於懲罰項的特徵選擇法:使用帶懲罰項的基模型,除了篩選出特徵外,同時也進行了降維。使用feature_selection庫的SelectFromModel類結合帶L1懲罰項的邏輯回歸模型。如:基於懲罰項的特徵選擇法、基於樹模型的特徵選擇法
基於樹模型的特徵選擇法:樹模型中GBDT也可用來作為基模型進行特徵選擇,使用feature_selection庫的SelectFromModel類結合GBDT模型。
4)深度學習方法:從深度學習模型中選擇某一神經層的特徵後就可以用來進行最終標的模型的訓練了。
5 降維:當特徵選擇完成後,可以直接訓練模型了,但是可能由於特徵矩陣過大,導致計算量大,訓練時間長的問題,因此降低特徵矩陣維度也是必不可少的。常見的降維方法:L1懲罰項的模型、主成分分析法(PCA)、線性判別分析(LDA)。PCA和LDA有很多的相似點,其本質是要將原始的樣本對映到維度更低的樣本空間中。所以說PCA是一種無監督的降維方法,而LDA是一種有監督的降維方法。
1)主成分分析法(PCA):使用decomposition庫的PCA類選擇特徵。
2)線性判別分析法(LDA):使用lda庫的LDA類選擇特徵。
18 模型評估之交叉驗證
k折交叉驗證(k-fold cross-validation)用一部分資料來訓練模型,然後用另一部分資料來測試模型的泛化誤差。該演演算法的具體步驟如下:
-
隨機將訓練樣本等分成k份。
-
對於每一份驗證資料Sj,演演算法在S1, …, SJ-1, SJ+1, …, Sk上進行特徵選擇,並且構造文字分類器。把得到的文字分類器在驗證集Sj上求泛化誤差。
-
把k個泛化誤差求平均,得到最後的泛化誤差。
19 EM演演算法
EM演演算法:當模型裡含有隱變數的時候,直接求解引數的極大似然估計就會失效。這時就需要用到來對引數進行迭代求解。EM演演算法說白了也是求含有隱變數的引數的極大似然估計。常用於混合模型(高斯混合模型,伯努利混合模型),訓練推理主題模型(topic model)時的pSLA等等。
EM演演算法步驟:給定可觀測變數的集合為X,隱藏變數的集合為Z,模型引數用W的聯合機率分佈,即,p(X,Z|W),標的是要最大化似然函式p(X|W),也就是要求出W使得p(X|W)最大。
-
選擇引數W的初始值,Wold即隱變數Z的後驗機率,即p(Z|X,Wold)
-
E步:利用初始值Wold計算隱變數Z的後驗機率分佈,p(Z|X,Wold),進而找出logp(X,Z|W)在Z的後驗機率下的期望Q(W,Wold)。
-
M步:極大化Q(W,Wold),以求出W。
-
檢查收斂條件,如果滿足收斂條件則停止;否則,令Wold= Wnew,然後跳轉到第2步,繼續迭代執行。
連結:http://www.cnblogs.com/baiboy/p/learnnlp.html
親愛的讀者朋友們,您們有什麼想法,請點選【寫留言】按鈕,寫下您的留言。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
公眾號推薦:
360區塊鏈,專註於360度分享區塊鏈內容。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
