作者丨羅凌
學校丨大連理工大學資訊檢索研究室
研究方向丨深度學習,文字分類,物體識別
近年來,註意力(Attention)機制被廣泛應用到基於深度學習的自然語言處理各個任務中,之前我對早期註意力機制進行過一些學習總結 [1]。
隨著註意力機制的深入研究,各式各樣的 Attention 被研究者們提出。在 2017年 6 月 Google 機器翻譯團隊在 arXiv 上放出的 Attention is All You Need [2] 論文受到了大家廣泛關註,自註意力(self-attention)機制開始成為神經網路 Attention 的研究熱點,在各個任務上也取得了不錯的效果。
本人就這篇論文中的 Self-Attention 以及一些相關工作進行了學習總結,其中也參考借鑒了張俊林博士的部落格深度學習中的註意力機制(2017版)[3]“和蘇劍林的一文讀懂「Attention is All You Need」| 附程式碼實現,和大家一起分享。
背景知識
Attention 機制最早是在視覺影象領域提出來的,應該是在九幾年思想就提出來了,但是真正火起來應該算是 2014 年 Google Mind 團隊的這篇論文 Recurrent Models of Visual Attention [4],他們在 RNN 模型上使用了 Attention機制來進行影象分類。
隨後,Bahdanau 等人在論文 Neural Machine Translation by Jointly Learning to Align and Translate [5] 中,使用類似 Attention 的機制在機器翻譯任務上將翻譯和對齊同時進行,他們的工作算是第一個將 Attention 機制應用到 NLP 領域中。
接著 Attention 機制被廣泛應用在基於 RNN/CNN 等神經網路模型的各種 NLP 任務中。2017 年,Google 機器翻譯團隊發表的 Attention is All You Need 中大量使用了自註意力(self-attention)機制來學習文字表示。自註意力機制也成為了大家近期的研究熱點,併在各種 NLP 任務上進行探索。
下圖為 Attention 研究進展的大概趨勢:

Attention 機制的本質來自於人類視覺註意力機制。人們視覺在感知東西的時候一般不會是一個場景從到頭看到尾每次全部都看,而往往是根據需求觀察註意特定的一部分。而且當人們發現一個場景經常在某部分出現自己想觀察的東西時,人們會進行學習在將來再出現類似場景時把註意力放到該部分上。

下麵我先介紹一下在 NLP 中常用 Attention 的計算方法,裡面借鑒了張俊林博士深度學習中的註意力機制(2017版)裡的一些圖。
Attention 函式的本質可以被描述為一個查詢(query)到一系列(鍵key-值value)對的對映,如下圖:

在計算 Attention 時主要分為三步,第一步是將 query 和每個 key 進行相似度計算得到權重,常用的相似度函式有點積,拼接,感知機等;然後第二步一般是使用一個 softmax 函式對這些權重進行歸一化;最後將權重和相應的鍵值 value 進行加權求和得到最後的 Attention。
目前在 NLP 研究中,key 和 value 常常都是同一個,即 key=value。

Attention is All You Need
接下來我將介紹 Attention is All You Need 這篇論文。這篇論文是 Google 機器翻譯團隊在 2017 年 6 月放在 arXiv 上,最後發表在 2017 年 NIPS 上,到目前為止 Google 學術顯示取用量為 119,可見也是受到了大家廣泛關註和應用。
這篇論文主要亮點在於:
1. 不同於以往主流機器翻譯使用基於 RNN 的 Seq2Seq 模型框架,該論文用 Attention 機制代替了 RNN 搭建了整個模型框架。
2. 提出了多頭註意力(Multi-headed Attention)機制方法,在編碼器和解碼器中大量的使用了多頭自註意力機制(Multi-headed self-attention)。
3. 在 WMT2014 語料中的英德和英法任務上取得了先進結果,並且訓練速度比主流模型更快。
該論文模型的整體結構如下圖,還是由編碼器和解碼器組成,在編碼器的一個網路塊中,由一個多頭 Attention 子層和一個前饋神經網路子層組成,整個編碼器棧式搭建了 N 個塊。類似於編碼器,只是解碼器的一個網路塊中多了一個多頭 Attention 層。
為了更好的最佳化深度網路,整個網路使用了殘差連線和對層進行了規範化(Add & Norm)。

下麵我們重點關註一下這篇論文中的 Attention。在介紹多頭 Attention 之前,我們先看一下論文中提到的放縮點積 Attention (Scaled Dot-Product attention)。
對比我在前面背景知識裡提到的 Attention 的一般形式,其實 Scaled Dot-Product Attention 就是我們常用的使用點積進行相似度計算的 Attention,只是多除了一個(為 K 的維度)起到調節作用,使得內積不至於太大。
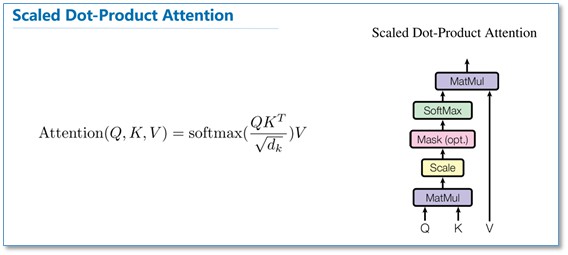
多頭 Attention(Multi-head Attention)結構如下圖,Query,Key,Value 首先進過一個線性變換,然後輸入到放縮點積 Attention,註意這裡要做 h 次,其實也就是所謂的多頭,每一次算一個頭。而且每次 Q,K,V 進行線性變換的引數 W 是不一樣的。然後將 h 次的放縮點積 Attention 結果進行拼接,再進行一次線性變換得到的值作為多頭 Attention 的結果。
可以看到,Google 提出來的多頭 Attention 的不同之處在於進行了 h 次計算而不僅僅算一次,論文中說到這樣的好處是可以允許模型在不同的表示子空間裡學習到相關的資訊,後面還會根據 Attention 視覺化來驗證。

那麼在整個模型中,是如何使用 Attention 的呢?如下圖,首先在編碼器到解碼器的地方使用了多頭 Attention 進行連線,K,V,Q 分別是編碼器的層輸出(這裡 K=V)和解碼器中都頭 Attention 的輸入。
其實就和主流的機器翻譯模型中的 Attention 一樣,利用解碼器和編碼器 Attention 來進行翻譯對齊。然後在編碼器和解碼器中都使用了多頭自註意力 Self-Attention 來學習文字的表示。
Self-Attention 即 K=V=Q,例如輸入一個句子,那麼裡面的每個詞都要和該句子中的所有詞進行 Attention 計算。目的是學習句子內部的詞依賴關係,捕獲句子的內部結構。

對於使用自註意力機制的原因,論文中提到主要從三個方面考慮(每一層的複雜度,是否可以並行,長距離依賴學習),並給出了和 RNN,CNN 計算複雜度的比較。
可以看到,如果輸入序列 n 小於表示維度 d 的話,每一層的時間複雜度 Self-Attention 是比較有優勢的。
當 n 比較大時,作者也給出了一種解決方案 Self-Attention(restricted)即每個詞不是和所有詞計算 Attention,而是隻與限制的 r 個詞去計算 Attention。
在並行方面,多頭 Attention 和 CNN 一樣不依賴於前一時刻的計算,可以很好的並行,優於 RNN。
在長距離依賴上,由於 Self-Attention 是每個詞和所有詞都要計算 Attention,所以不管他們中間有多長距離,最大的路徑長度也都只是 1。可以捕獲長距離依賴關係。

最後我們看一下實驗結果,在 WMT2014 的英德和英法機器翻譯任務上,都取得了先進的結果,且訓練速度優於其他模型。
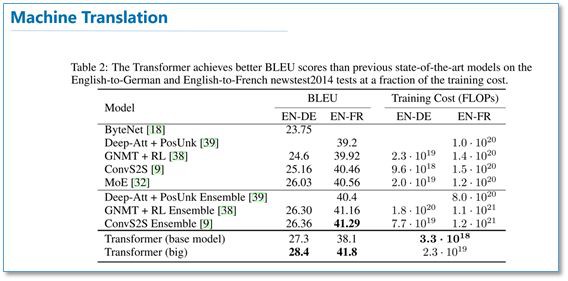
在模型的超參實驗中可以看到,多頭 Attention 的超參 h 太小也不好,太大也會下降。整體更大的模型比小模型要好,使用 dropout 可以幫助過擬合。
作者還將這個模型應用到了句法分析任務上也取得了不錯的結果。

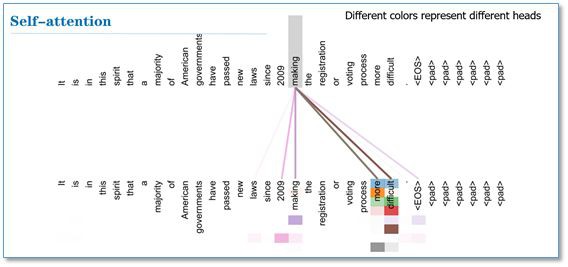
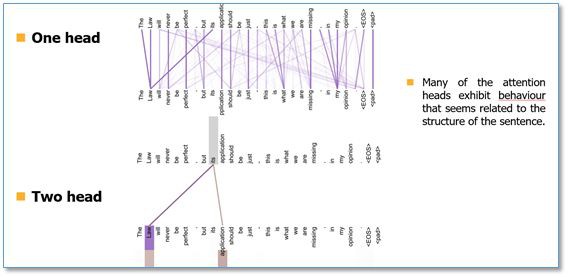
最後我們看一下 Attention 視覺化的效果(這裡不同顏色代表 Attention 不同頭的結果,顏色越深 Attention 值越大)。可以看到 Self-Attention 在這裡可以學習到句子內部長距離依賴”making…….more difficult”這個短語。
在兩個頭和單頭的比較中,可以看到單頭”its”這個詞只能學習到”law”的依賴關係,而兩個頭”its”不僅學習到了”law”還學習到了”application”依賴關係。多頭能夠從不同的表示子空間裡學習相關資訊。
Self-Attention in NLP
■ 論文 | Deep Semantic Role Labeling with Self-Attention
■ 連結 | https://www.paperweekly.site/papers/1786
■ 原始碼 | https://github.com/XMUNLP/Tagger
這篇論文來自 AAAI2018,廈門大學 Tan 等人的工作。他們將 Self-Attention 應用到了語意角色標註任務(SRL)上,並取得了先進的結果。
這篇論文中,作者將 SRL 作為一個序列標註問題,使用 BIO 標簽進行標註。然後提出使用深度註意力網路(Deep Attentional Neural Network)進行標註,網路結構如下:
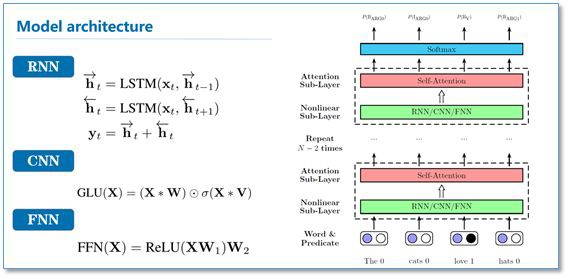
在每一個網路塊中,有一個 RNN/CNN/FNN 子層和一個 Self-Attention 子層組成。最後直接利用 softmax 當成標簽分類進行序列標註。
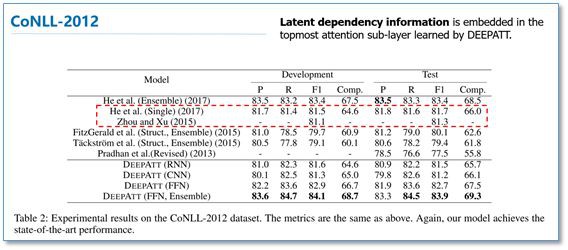
該模型在 CoNLL-2005 和 CoNll-2012 的 SRL 資料集上都取得了先進結果。我們知道序列標註問題中,標簽之間是有依賴關係的,比如標簽 I,應該是出現在標簽 B 之後,而不應該出現在 O 之後。
目前主流的序列標註模型是 BiLSTM-CRF 模型,利用 CRF 進行全域性標簽最佳化。在對比實驗中,He et al 和 Zhou and Xu 的模型分別使用了 CRF 和 constrained decoding 來處理這個問題。
可以看到本論文僅使用 Self-Attention,作者認為在模型的頂層的 Attention 層能夠學習到標簽潛在的依賴資訊。

■ 論文 | Simultaneously Self-Attending to All Mentions for Full-Abstract Biological Relation Extraction
■ 連結 | https://www.paperweekly.site/papers/1787
■ 作者 | Patrick Verga / Emma Strubell / Andrew McCallum
這篇論文是 Andrew McCallum 團隊應用 Self-Attention 在生物醫學關係抽取任務上的一個工作,應該是已經被 NAACL 2018 接收。這篇論文作者提出了一個檔案級別的生物關係抽取模型,裡面做了不少工作,感興趣的讀者可以更深入閱讀原文。
我們這裡只簡單提一下他們 Self-Attention 的應用部分。論文模型的整體結構如下圖,他們也是使用 Google 提出包含 Self-Attention 的 transformer 來對輸入文字進行表示學習,和原始的 transformer 略有不同在於他們使用了視窗大小為 5 的 CNN 代替了原始 FNN。

我們關註一下 Attention 這部分的實驗結果。他們在生物醫學藥物致病資料集上(Chemical Disease Relations,CDR)取得了先進結果。去掉 Self-Attention 這層以後可以看到結果大幅度下降,而且使用視窗大小為 5 的 CNN 比原始的 FNN 在這個資料集上有更突出的表現。

總結
最後進行一下總結,Self-Attention 可以是一般 Attention 的一種特殊情況,在 Self-Attention 中,Q=K=V 每個序列中的單元和該序列中所有單元進行 Attention 計算。
Google 提出的多頭 Attention 透過計算多次來捕獲不同子空間上的相關資訊。Self-Attention 的特點在於無視詞之間的距離直接計算依賴關係,能夠學習一個句子的內部結構,實現也較為簡單並行可以平行計算。
從一些論文中看到,Self-Attention 可以當成一個層和 RNN,CNN,FNN 等配合使用,成功應用於其他 NLP 任務。

除了 Google 提出的自註意力機制,目前也有不少其他相關工作,感興趣的讀者可以繼續閱讀。

相關連結
[1] 註意力機制在自然語言處理中的應用
http://www.cnblogs.com/robert-dlut/p/5952032.html
[2] Attention is All You Need
https://www.paperweekly.site/papers/224
[3] 深度學習中的註意力機制(2017版)
https://blog.csdn.net/malefactor/article/details/78767781
[4] Recurrent Models of Visual Attention
https://www.paperweekly.site/papers/1788
[5] Neural Machine Translation by Jointly Learning to Align and Translate
https://www.paperweekly.site/papers/434
參考文獻
[1] Romain Paulus, Caiming Xiong, and Richard Socher. A deep reinforced model for abstractive summarization. arXiv preprint arXiv:1705.04304, 2017.
[2] Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. A structured self-attentive sentence embedding. arXiv preprint arXiv:1703.03130, 2017.
[3] Jianpeng Cheng, Li Dong, and Mirella Lapata. Long short-term memory-networks for machine reading. arXiv preprint arXiv:1601.06733, 2016.
[4] Shen, T.; Zhou, T.; Long, G.; Jiang, J.; Pan, S.; and Zhang, C. Disan: Directional self-attention network for rnn/cnn-free language understanding. arXiv preprint arXiv:1709.04696, 2017.
[5] Im, Jinbae, and Sungzoon Cho. Distance-based Self-Attention Network for Natural Language Inference. arXiv preprint arXiv:1712.02047, 2017.
[6] Shaw, Peter, Jakob Uszkoreit, and Ashish Vaswani. Self-Attention with Relative Position Representations. arXiv preprint arXiv:1803.02155 ,2018.

點選以下標題檢視相關內容:

 #作 者 招 募#
#作 者 招 募#
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot02)進行諮詢
長按識別二維碼,使用小程式
*點選閱讀原文即可註冊

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 加入社群一起刷論文
