
在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @Cratial。本文提出構建一個關係網路(Relation Network)來讓其學習如何比較(Learning to Compare),從而實現少樣本學習(Few-Shot Learning)。
如果你對本文工作感興趣,點選底部閱讀原文即可檢視原論文。
關於作者:吳仕超,東北大學碩士生,研究方向為腦機介面、駕駛疲勞檢測和機器學習。
■ 論文 | Learning to Compare: Relation Network for Few-Shot Learning
■ 連結 | https://www.paperweekly.site/papers/1817
■ 原始碼 | http://suo.im/4W4mdD
引出主題
近年來,深度學習之所以取得如此大的成功,主要在於目前擁有的海量資料和強大計算資源,尤其是在影象識別方面。因此,如何實現深度學習的快速學習,是深度學習研究的一大難題。
對於人而言,在識別物體的時候,僅需要少量影象或不需要影象,而根據對物體的描述就能基於以往的經驗知識實現對物體的識別,這是為什麼呢?因為我們有先驗知識,我們會利用自己的先驗知識來進行學習。例如,經常使用老式諾基亞手機的人也能很快地學會如何使用智慧機。
如何實現這種快速學習呢?元學習就是實現方法之一。元學習,英文名叫 Meta Learning,也叫做 Learning to Learn,即學會學習。如何讓神經網路實現元學習?這裡提供了元學習的相關知識 [1]。
本文利用對比關係來實現元學習,作者認為人在識別影象時是透過比較影象與影象之間的特徵來實現識別的,即少樣本學習。
如對於剛出生沒多久的小孩子來說,他們也能很快地識別出什麼是“鴨”和“鵝”,即使他們並沒有見過幾次,因為我們的視覺細胞可以自動地提取影象的特徵(如輪廓、光照等),然後對比我們以往的經驗就能對影象進行識別了。這篇論文的 Relation Network(RN)就是根據這種思想設計的。
系統結構與方法
資料處理
本文將資料分為 training set、support set 和 testing set 三部分,其中 support set 作為對比學習的樣例,它擁有和測試資料一樣的標簽,在測試過程中,可以透過與測試資料的對比來實現對測試資料的識別。
對於包含 C 個不同的類別,每個類別有 K 個樣本的 support set,本文稱其為 C-way,K-shot。為了實現對網路的訓練,本文將 training set 分成和 support set 及 testing set,文中將其分別稱為 sample set 與 query set。
模型
one-hot
本文提出的 RN 包含兩部分,一部分為嵌入單元 fφ,用來提取影象的特徵,另一部分為關聯單元,用來計算兩個影象的相似度,如圖 1 所示。
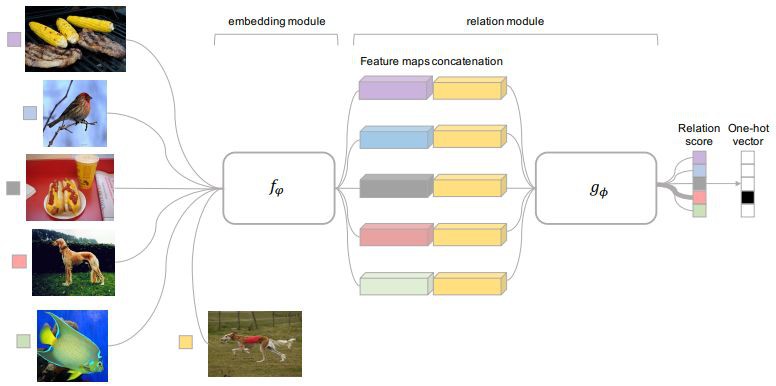
▲ 圖1
這是一個明顯的 5-way,1-shot 模型。在訓練時,利用 training set 來對網路進行元學習,用 sample set 中的資料與 query set 中的資料做對比。在嵌入單元分別獲得兩者的特徵、然後對特徵進行連線後送入到關聯單元計算關聯絡數,如公式 1 所示。

其中,fφ 代表嵌入單元,C(fφ(xi),fφ(xj)) 代表將特徵連線一起,gϕ 代表連線單元。
K-shot
對於各類資料,如果僅有 K(K>1) 個樣本,則將同一類的 feature_map 相加,few-shot 的網路模型下圖所示。

▲ 圖2
Zero-shot
zero-shot 和 one-shot 類似,只不過這裡將 support set 中的影象換成了語意向量,嵌入單元也做了修改。zero-shot 的網路結構如圖 3 所示,DNN 表示訓練好的模型,如 VGG、Inception 等。

▲ 圖3
實驗結果與分析
作者分別在 Omniglot 和 miniImageNet 資料集上測試了 few-shot,在 Animals with Attributes (AwA) 和 Caltech-UCSD Birds-200-2011 (CUB) 上測試了 zero-shot。所有的程式都是基於 PyTorch 實現的。
Few-shot
Omniglot
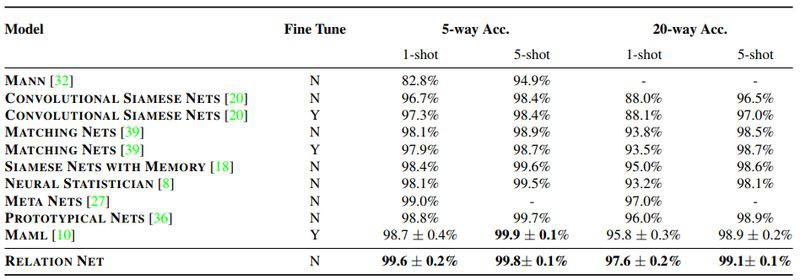
Omniglot 包含 50 個不同的字母,共計 1623 類字元,每一類由 20 個不同的人創作。為了增加資料量,本文還對影象進行了旋轉變換,分別對 5-way 1-shot、5-way 5-shot、20-way 1-shot 和 20-way 5-shot 集中情況展開了實驗,實驗結果如下表所示。
miniImageNet
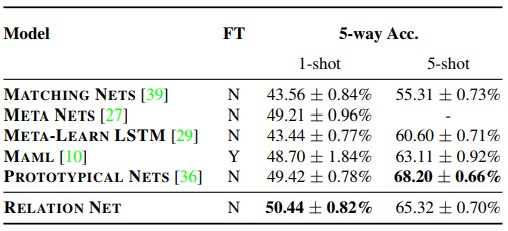
miniImageNet是從 ImageNet 分割得到的,具體分割方法參照 [2]。本文在 miniImageNet 上進行了 5 way 1-shot 及 5 way 5-shot 的實驗,實驗結果如下表所示。
Zero-shot
RN 在 AwA 及 CUB 上的準確率和其他方法的對比如下表所示。
0-way 1-shot 和 20-way 5-shot 集中情況展開了實驗,實驗結果如下表所示。

RN為什麼能工作
這部分為本論文最核心的內容,論文指出,之前的 few-shot 工作都是預先指定好度量方式的,如歐式距離或餘弦距離,學習部分主要體現在特徵嵌入方面。
但是該論文同時學習了特徵的嵌入及非線性度量矩陣(相似度函式),這些都是端到端的調整。透過學習到的相似性矩陣比人為選定的矩陣更具有靈活性,更能捕獲到特徵之間的相似性。
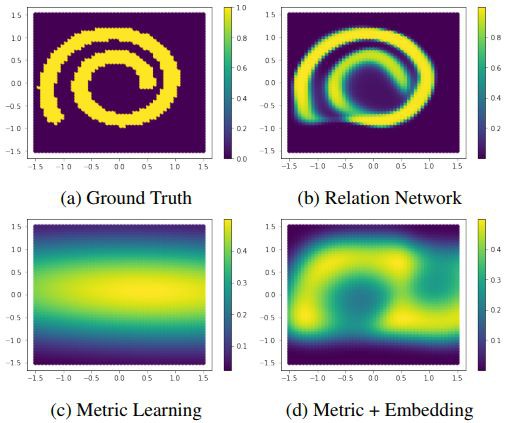
為了證明 RN 的有效性,作者分別使用馬哈拉諾比斯度量矩陣方法 4(c)、馬哈拉諾比斯度量矩陣 + 多層感知機 4(d) 及 RN4(b) 對 query set 的匹配情況,透過和 4(a) 相對比可以看出,RN 的匹配效果最好。
▲ 圖4
圖 5 左邊是原始情況下 Omniglot 中圖的關係,其中青色是和樣例點(黃色)相匹配的影象,紫色是和樣本點不匹配的影象。

▲ 圖5
從圖中可以看出,使用歐式距離或餘弦距離都不能實現對樣例點的正常匹配。但透過對 RN 的倒數第二層進行 PCA 降維,得到的分佈圖如圖 5(右)所示,可以看出匹配的與無法匹配的兩類樣本變成線性可分的。
相關連結
[1] 百家爭鳴的Meta Learning/Learning to learn
https://zhuanlan.zhihu.com/p/28639662
[2] Matching Networks for One Shot Learning
https://papers.nips.cc/paper/6385-matching-networks-for-one-shot-learning
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:

▲ 戳我檢視招聘詳情
 #崗 位 推 薦#
#崗 位 推 薦#
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視原論文