筆者邀請您,先思考:
1 您怎麼理解LSTM演演算法?
2 LSTM演演算法有什麼應用?
LSTM(Long Short-Term Memory)演演算法作為深度學習方法的一種,在介紹LSTM演演算法之前,有必要介紹一下深度學習(Deep Learning)的一些基本背景。
目前在機器學習領域,最大的熱點毫無疑問是深度學習,從谷歌大腦(Google Brain)的貓臉識別,到ImageNet比賽中深度摺積神經網路的獲勝,再到Alphago大勝李世石,深度學習受到媒體、學者以及相關研究人員越來越多的熱捧。這背後的原因無非是深度學習方法的效果確實超越了傳統機器學習方法許多。
從2012年Geoffrey E. Hinton的團隊在ImageNet比賽(影象識別中規模最大影響最大的比賽之一)中使用深度學習方法獲勝之後,關於深度學習的研究就呈井噴之勢;在2012年以前,該比賽結果的準確率一直處於緩慢提升的狀態,這一年突然有質的飛越,而從此之後深度學習方法也成為了ImageNet比賽中的不二選擇。
同時,深度學習的影響卻不僅侷限於影象識別比賽,也深刻影響了學術界和工業界,頂級的學術會議中關於深度學習的研究越來越多,如CVPR、ICML等等,而工業級也為深度學習立下了汗馬功勞,貢獻了越來越多的計算支援或者框架,如Nivdia的cuda、cuDnn,Google的tensorflow,Facebook的torch和微軟的DMTK等等。
深度學習技術發展的背後是廣大研究人員的付出,目前該領域內最著名的研究人員莫過於Yoshua Bengio,Geoffrey E. Hinton,Yann LeCun以及Andrew Ng。最近Yoshua Bengio等出版了《Deep Learning》一書,其中對深度學習的歷史發展以及該領域內的主要技術做了很系統的論述,其關於深度學習歷史發展趨勢的總結非常精闢,書中總結的深度學習歷史發展趨勢的幾個關鍵點分別:
a)深度學習本身具有豐富悠久的歷史,但是從不同的角度出發有很多不同得名,所以歷史上其流行有過衰減趨勢。
b)隨著可以使用的訓練資料量逐漸增加,深度學習的應用空間必將越來越大。
c)隨著計算機硬體和深度學習軟體基礎架構的改善,深度學習模型的規模必將越來越大。
d)隨著時間的推移,深度學習解決複雜應用的精度必將越來越高。
而深度學習的歷史大體可以分為三個階段。一是在20世紀40年代至60年代,當時深度學習被稱為控制論;二是在上世紀80年代至90年代,此期間深度學習被譽為聯結學習;三是從2006年開始才以深度學習這個名字開始複蘇(起點是2006年,Geoffrey Hinton發現深度置信網可以透過逐層貪心預訓練的策略有效地訓練)。
總而言之,深度學習作為機器學習的一種方法,在過去幾十年中有了長足的發展。隨著基礎計算架構效能的提升,更大的資料集和更好的最佳化訓練技術,可以預見深度學習在不遠的未來一定會取得更多的成果。

LSTM演演算法全稱為Long short-term memory,最早由 Sepp Hochreiter和Jürgen Schmidhuber於1997年提出[6],是一種特定形式的RNN(Recurrent neural network,迴圈神經網路),而RNN是一系列能夠處理序列資料的神經網路的總稱。這裡要註意迴圈神經網路和遞迴神經網路(Recursive neural network)的區別。
一般地,RNN包含如下三個特性:
a)迴圈神經網路能夠在每個時間節點產生一個輸出,且隱單元間的連線是迴圈的;
b)迴圈神經網路能夠在每個時間節點產生一個輸出,且該時間節點上的輸出僅與下一時間節點的隱單元有迴圈連線;
c)迴圈神經網路包含帶有迴圈連線的隱單元,且能夠處理序列資料並輸出單一的預測。
RNN還有許多變形,例如雙向RNN(Bidirectional RNN)等。然而,RNN在處理長期依賴(時間序列上距離較遠的節點)時會遇到巨大的困難,因為計算距離較遠的節點之間的聯絡時會涉及雅可比矩陣的多次相乘,這會帶來梯度消失(經常發生)或者梯度膨脹(較少發生)的問題,這樣的現象被許多學者觀察到並獨立研究。
為瞭解決該問題,研究人員提出了許多解決辦法,例如ESN(Echo State Network),增加有漏單元(Leaky Units)等等。其中最成功應用最廣泛的就是門限RNN(Gated RNN),而LSTM就是門限RNN中最著名的一種。有漏單元透過設計連線間的權重繫數,從而允許RNN累積距離較遠節點間的長期聯絡;而門限RNN則泛化了這樣的思想,允許在不同時刻改變該繫數,且允許網路忘記當前已經累積的資訊。
LSTM就是這樣的門限RNN,其單一節點的結構如下圖1所示。LSTM的巧妙之處在於透過增加輸入門限,遺忘門限和輸出門限,使得自迴圈的權重是變化的,這樣一來在模型引數固定的情況下,不同時刻的積分尺度可以動態改變,從而避免了梯度消失或者梯度膨脹的問題。
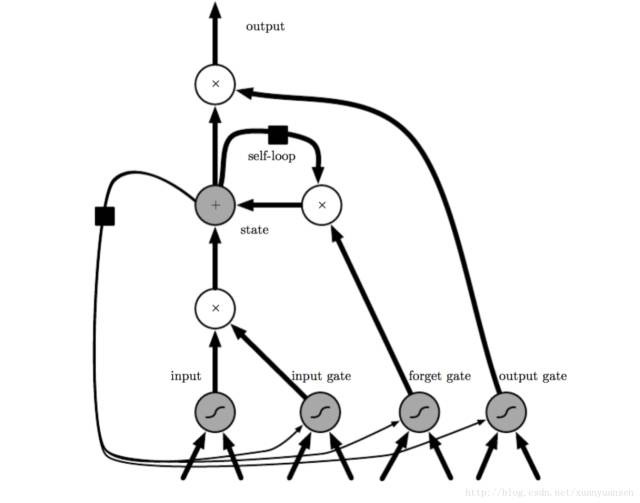
圖1 LSTM的CELL示意圖
根據LSTM網路的結構,每個LSTM單元的計算公式如下圖2所示,其中Ft表示遺忘門限,It表示輸入門限, ̃Ct表示前一時刻cell狀態、Ct表示cell狀態(這裡就是迴圈發生的地方),Ot表示輸出門限,Ht表示當前單元的輸出,Ht-1表示前一時刻單元的輸出。

圖2 LSTM計算公式
介紹完LSTM演演算法的原理之後,自然要瞭解如何訓練LSTM網路。與前饋神經網路類似,LSTM網路的訓練同樣採用的是誤差的反向傳播演演算法(BP),不過因為LSTM處理的是序列資料,所以在使用BP的時候需要將整個時間序列上的誤差傳播回來。LSTM本身又可以表示為帶有迴圈的圖結構,也就是說在這個帶有迴圈的圖上使用反向傳播時我們稱之為BPTT(back-propagation through time)。
下麵我們透過圖3和圖4來解釋BPTT的計算過程。從圖3中LSTM的結構可以看到,當前cell的狀態會受到前一個cell狀態的影響,這體現了LSTM的recurrent特性。同時在誤差反向傳播計算時,可以發現h(t)的誤差不僅僅包含當前時刻T的誤差,也包括T時刻之後所有時刻的誤差,即back-propagation through time的含義,這樣每個時刻的誤差都可以經由h(t)和c(t+1)迭代計算。

圖3 LSTM網路示意圖
為了直觀地表示整個計算過程,在參考神經網路計算圖的基礎上,LSTM的計算圖如圖4所示,從計算圖上面可以清晰地看出LSTM的forward propagation和back propagation過程。如圖,H(t-1)的誤差由H(t)決定,且要對所有的gate layer傳播回來的梯度求和,c(t-1)由c(t)決定,而c(t)的誤差由兩部分,一部分是h(t),另一部分是c(t+1)。所以在計算c(t)反向傳播誤差的時候,需要傳入h(t)和c(t+1),而h(t)在更新的時候需要加上h(t+1)。這樣就可以從時刻T向後計算任一時刻的梯度,利用隨機梯度下降完成權重繫數的更新。
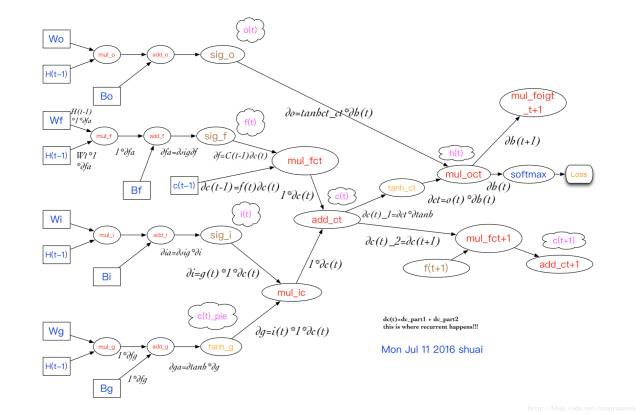
圖4 BPTT示意圖
LSTM演演算法的變形有很多,最主要的有兩種,分別如下:
a)GRU
LSTM演演算法的變形裡面GRU(Gated Recurrent Unit)是使用最為廣泛的一種,最早由Cho等人於2014年提出[7]。GRU與LSTM的區別在於使用同一個門限來代替輸入門限和遺忘門限,即透過一個“更新”門限來控制cell的狀態,該做法的好處是計算得以簡化,同時模型的表達能力也很強,所以GRU也因此越來越流行。
b)Peephole LSTM
Peephole LSTM由Gers和Schmidhuber在2000年提出[8],Peephole的含義是指允許當前時刻的門限Gate“看到”前一時刻cell的狀態,這樣在計算輸入門限,遺忘門限和輸出門限時需要加入表示前一時刻cell狀態的變數。同時,另外一些Peephole LSTM的變種會允許不同的門限“看到”前一時刻cell的狀態。
不同的研究者提出了許多LSTM的改進,然而並沒有特定型別的LSTM在任何任務上都能夠由於其他變種,僅能在部分特定任務上取得最佳的效果。更多LSTM演演算法的改進可以參考《Deep Learning》一書中的第10.10章節。
本文回顧了LSTM演演算法誕生的背景與原因,詳細分析了LSTM網路訓練過程中使用BPTT的細節,並介紹了LSTM演演算法在*中的應用。從目前模型上線後的表現效果看來,LSTM演演算法的表現超過了傳統演演算法(SVM,RF,GBDT等等),也從側面印證了深度學習的強大之處,值得演演算法同學更多的探索。誠然,深度學習這一新興的機器學習領域內包羅永珍,上述的理解僅是個人的一些涉獵和體會,如有紕漏在所難免,歡迎對深度學習感興趣的同學一起探討,共同提高。
本文主要參考瞭如下資料,深表感謝:
a)Understanding LSTM Networks,http://colah.github.io/posts/2015-08-Understanding-LSTMs/;
b)Deep Learning,Ian Goodfellow Yoshua Bengio and Aaron Courville,Book in preparation for MIT Press,2016;
c)Simple LSTM,http://nicodjimenez.github.io/2014/08/08/lstm.html。
GIHUB地址:https://github.com/xuanyuansen/scalaLSTM
【1】https://googleblog.blogspot.com/2012/06/using-large-scale-brain-simulations-for.html;
【2】http://image-net.org/challenges/LSVRC/2012/supervision.pdf;
【3】https://en.wikipedia.org/wiki/AlphaGo;https://deepmind.com/research/alphago/;http://sports.sina.com.cn/go/2016-09-13/doc-ifxvukhx4979709.shtml;
【4】https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf;
【5】http://www.deeplearningbook.org/;
【6】http://www.mitpressjournals.org/doi/abs/10.1162/neco.1997.9.8.1735#.V9fMNZN95TY;
【7】http://arxiv.org/pdf/1406.1078v3.pdf;【8】ftp://ftp.idsia.ch/pub/juergen/TimeCount-IJCNN2000.pdf.
原文連結:http://blog.csdn.net/xuanyuansen/article/details/61913886
您有什麼見解,請留言。
文章推薦
加入資料人圈子或者商務合作,請新增筆者微信。

資料人網是資料人學習、交流和分享的平臺http://shujuren.org 。專註於從資料中學習到有用知識。
平臺的理念:人人投稿,知識共享;人人分析,洞見驅動;智慧聚合,普惠人人。
您在資料人網平臺,可以1)學習資料知識;2)建立資料部落格;3)認識資料朋友;4)尋找資料工作;5)找到其它與資料相關的乾貨。
我們努力堅持做原創,聚合和分享優質的省時的資料知識!
我們都是資料人,資料是有價值的,堅定不移地實現從資料到商業價值的轉換!
點選閱讀原文,進入資料人網,獲取資料知識。
公眾號推薦:
區塊鏈傳達,專註於分享區塊鏈內容。

腳印英語,專註於分享英語口語內容。

