
筆者邀請您,先思考:
1 您在面試資料的工作,遇到什麼資料科學面試題?
-
1 您將在時間序列資料集上使用什麼交叉驗證技術?
-
2 什麼是邏輯回歸? 或者在最近使用邏輯回歸時說明一個例子。
-
3 您怎麼理解“正態分佈”?
-
4 什麼是Box Cox轉換?
-
5 您將如何確定聚類演演算法中的聚類數量?
-
6 什麼是深度學習?
-
7 什麼是迴圈神經網路(RNN)?
-
8 機器學習與深度學習有什麼區別?
-
9 什麼是強化學習?
-
10 什麼是選擇偏差?
-
11 解釋正規化是什麼以及它為什麼有用。
-
12 什麼是TF / IDF向量化?
-
13 什麼是推薦系統?
-
14 回歸和分類ML技術有什麼區別?
-
15 如果你的機器有4GB記憶體,而你想在10GB資料集上訓練模型。 你會如何解決這個問題。 到目前為止,您在機器學習/資料科學體驗中是否遇到過這種問題?
1 您將在時間序列資料集上使用什麼交叉驗證技術?
您應該意識到時間序列不是隨機分佈資料這一事實,它本質上是按照時間順序排序的,因而不使用K-折交叉驗證。
在時間序列資料的情況下,您應該使用像前向鏈接這樣的技術 – 您將在過去的資料模型中檢視前向資料。
摺疊1:訓練[1],測試[2]
摺疊1:訓練[1 2],測試[3]
摺疊1:訓練[1 2 3],測試[4]
摺疊1:訓練[1 2 3 4],測試[5]
2 什麼是邏輯回歸? 或者在最近使用邏輯回歸時說明一個例子。
Logistic回歸通常被稱為logit模型,它是一種從預測變數的線性組合預測二元結果的技術。 例如,如果你想預測一個特定的政治領導人是否會贏得選舉。 在這種情況下,預測的結果是二元的,即0或1(贏/輸)。 這裡的預測變數將是特定候選人競選活動花費的金額,競選活動花費的時間等。
3 您怎麼理解“正態分佈”?

資料通常以不同的方式分佈,偏向左側或右側,或者全部混亂。 然而,有可能資料圍繞一個中心值分佈,沒有任何左偏或右偏,並以鐘形曲線的形式達到正態分佈。 隨機變數以對稱鐘形曲線的形式分佈。
4 什麼是Box Cox轉換?
回歸分析的因變數可能不滿足普通最小二乘的一個或多個回歸假設。殘差可能隨著預測的增加或隨偏態分佈而變化。 在這種情況下,有必要對響應變數進行變換,以使資料滿足所需的假設條件。 Box cox轉換是一種將非正態因變數轉換為正常形狀的統計技術。 如果給定的資料不滿足正態,但是大部分統計技術都假設正態化。 應用boxcox轉換意味著您可以執行更多的測試。
Box Cox變換是一種將非正態因變數轉換為正態形狀的方法。 對於許多統計技術來說,正態性是一個重要的假設,如果您的資料不滿足正態分佈,應用Box-Cox意味著您可以執行更多的測試。 Box Cox轉型以統計學家George Box和David Roxbee Cox爵士的名字命名,他們在1964年的論文中合作並開發了這項技術。
5 您將如何確定聚類演演算法中的聚類數量?
雖然聚類演演算法沒有指定,但是這個問題通常會參考K-Means聚類,其中“K”定義聚類的數量。 例如,下圖顯示了三個不同的組。
在簇內平方和通常用於解釋群集內的同質性。 如果您根據聚類數量繪製WSS您將得到如下所示的圖。 該圖通常稱為Elbow Curve。
上圖中的紅色圓圈點數,即群集數量= 6是在WSS中沒有看到遞減的點。 這一點被稱為轉折點,在K-Means中被視為K.這是廣泛使用的方法,但很少資料科學家也首先使用分層聚類來建立樹狀圖並從中識別不同的組。
6 什麼是深度學習?
深度學習是受人腦神經網路結構和功能啟發的機器學習的子領域。 線上性回歸,支援向量機,神經網路等機器學習演演算法中,我們有很多演演算法,深度學習只是神經網路的擴充套件。 在神經網路中,我們考慮了少量的隱藏層,但是當涉及到深度學習演演算法時,我們會考慮大量隱藏latyers來更好地理解輸入輸出關係。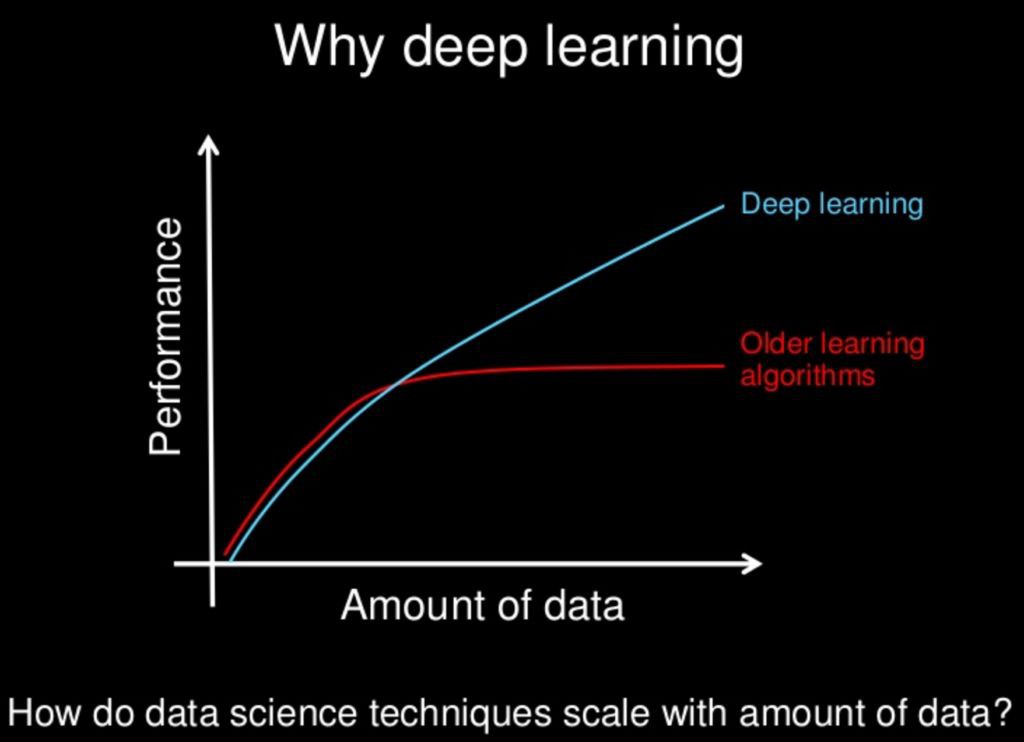
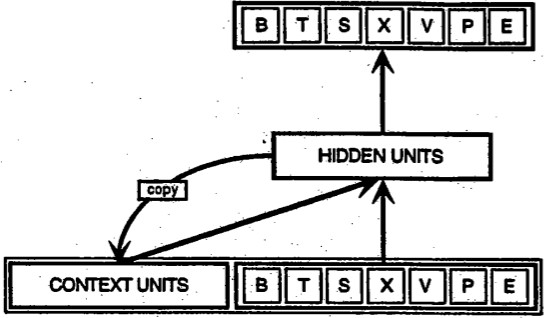
7 什麼是迴圈神經網路(RNN)?
迴圈神經網路是一類人工神經網路,用於識別時間序列,股票市場和政府機構等資料序列中的樣式。要理解迴圈神經網路,首先必須瞭解前饋網路的基本知識。RNN和前饋都是以它們傳遞資訊的方式命名的,這些資訊是在網路節點上執行的一系列數學運算。 一個節點直接提供資訊(從不接觸相同的節點兩次),而另一個節點則迴圈它,而後者被稱為迴圈性的。

另一方面,迴圈性網路不僅將他們所看到的當前輸入示例作為他們的輸入,而且還將他們以前所見的輸入示例作為輸入。圖底部的BTSXPE表示當前時刻的輸入示例,而背景關係單元表示前一時刻的輸出。在時間t-1達到的遞迴神經網路的決定會影響它在時間t達到的決定。所以迴圈性網路有兩個輸入源,現在和最近的過去,這兩個輸入源組合起來決定它們如何響應新資料,就像我們在生活中一樣。
它們產生的錯誤將透過反向傳播傳回並用於調整它們的權重,直到錯誤不能再降低。請記住,迴圈性網路的目的是準確分類順序輸入。我們依靠誤差和梯度下降的反向傳播來做到這一點。
前饋網路中的反向傳播從最終誤差向後移動,透過每個隱藏層的輸出,權重和輸入,透過計算它們的偏導數來指定這些權重對部分誤差的影響 – ∂E/∂w或它們的比率之間的關係的變化。那些衍生物然後被我們的學習規則,梯度下降,來調整權重向上或向下,無論哪個方向減少錯誤。
經常性網路依賴於透過時間反向傳播的擴充套件,即BPTT。在這種情況下,時間可以簡單地表達為一個明確的,有序的一系列計算,將一個時間步與下一個時間步連結起來,這是所有後向傳播都需要的。
8 機器學習與深度學習有什麼區別?
機器學習:
機器學習是電腦科學的一個領域,它使計算機無需明確程式設計即可學習。 機器學習可以分為以下三類。
監督機器學習,
無監督機器學習,
強化學習
深度學習:
深度學習是機器學習的一個子領域,涉及受大腦結構和功能(稱為人工神經網路)啟發的演演算法。
9 什麼是強化學習?
強化學習
強化學習正在學習如何做,以及如何將環境對映到行動。 最終結果是最大化數字獎勵訊號。 學習者沒有被告知要採取什麼行動,而是必鬚髮現哪種行為會產生最大的回報。強化學習的靈感來自人類的學習,它是基於獎勵/懲罰機制。
10 什麼是選擇偏差?
選擇偏差是透過選擇個體,群體或資料進行分析而引入的偏差,以便不會實現適當的隨機化,從而確保獲得的樣本不代表要分析的群體。 它有時被稱為選擇效應。 “選擇偏差”這個短語通常是指取樣方法導致的統計分析失真。 如果不考慮選擇偏差,那麼研究的一些結論可能不準確。
11 解釋正規化是什麼以及它為什麼有用。
正則化是為了防止過度擬合而向模型新增調整引數以引起平滑度的過程。 這通常是透過向現有的權重向量乘以常數來完成的。 這個常數通常是L1(Lasso)或L2(ridge)。 然後,模型預測應該使正則化訓練集上計算的損失函式最小化。
12 什麼是TF / IDF向量化?
tf-idf是詞頻 – 逆檔案頻率的縮寫,是一個數字統計量,旨在反映詞彙對集合或語料庫中檔案的重要程度。 它通常用作資訊檢索和文字挖掘的權重因子。 tf-idf值與單詞在檔案中出現的次數成比例地增加,但被語料庫中單詞的頻率所抵消,這有助於調整一些單詞通常出現頻率很高的事實。
13 什麼是推薦系統?
資訊過濾系統的一個子類,旨在預測使用者對產品的偏好或評級。 推薦系統廣泛應用於電影,新聞,研究文章,產品,社交標簽,音樂等。
14 回歸和分類ML技術有什麼區別?
回歸和分類機器學習技術都屬於監督機器學習演演算法。在有監督的機器學習演演算法中,我們必須使用帶標記的資料集來訓練模型,而訓練時我們必須明確地提供正確的標簽,演演算法試圖從輸入到輸出學習樣式。 如果我們的標簽是離散值,那麼它就會出現分類問題,例如A,B等,但是如果我們的標簽是連續值,那麼這將是一個回歸問題,例如1.23,1.333等。
15 如果你的機器有4GB記憶體,而你想在10GB資料集上訓練模型。 你會如何解決這個問題。 到目前為止,您在機器學習/資料科學體驗中是否遇到過這種問題?
首先,你必須問問你想訓練哪種ML模型。
對於神經網路:使用Numpy陣列的批次大小將起作用。
步驟:
-
將整個資料載入到Numpy陣列中。 Numpy陣列具有建立完整資料集對映的屬性,它不會將完整的資料集載入到記憶體中。
-
您可以將索引傳遞給Numpy陣列以獲取所需的資料。
-
使用這些資料傳遞給神經網路。
-
有小批次。
對於SVM:部分適合將起作用
步驟:
-
將一個大資料集劃分一些小資料集
-
使用SVM的partialfit方法,它需要完整資料集的子集。
-
對其他子集重覆步驟2。
您有什麼見解,請留言。
原文連結:
https://nitin-panwar.github.io/Top-100-Data-science-interview-questions/
版權宣告:作者保留權利,嚴禁修改,轉載請註明原文連結。
您有什麼見解,請留言。
加入資料人圈子或者商務合作,請新增筆者微信。

資料人網是資料人學習、交流和分享的平臺http://shujuren.org 。專註於從資料中學習到有用知識。
平臺的理念:人人投稿,知識共享;人人分析,洞見驅動;智慧聚合,普惠人人。
您在資料人網平臺,可以1)學習資料知識;2)建立資料部落格;3)認識資料朋友;4)尋找資料工作;5)找到其它與資料相關的乾貨。
我們努力堅持做原創,聚合和分享優質的省時的資料知識!
我們都是資料人,資料是有價值的,堅定不移地實現從資料到商業價值的轉換!
點選閱讀原文,進入資料人網,獲取資料知識。
公眾號推薦:
區塊鏈傳達,專註於分享區塊鏈內容。

腳印英語,專註於分享英語口語內容。
