
導讀:半個世紀以前,混沌理論的先驅發現了“蝴蝶效應”,即使是對複雜系統極小的幹擾(比如說天氣,經濟或其他事物)也會引發一連串相應的事件,最終形成完全不同的未來。但是現在機器可以幫忙,研究者稱:“機器學習的技術讓我們幾乎找到了混沌系統的真相!”
作者:Natalie Wolchover
本文授權自集智集智俱樂部(ID:swarma_org),轉載請聯絡授權。

▲機器學習演演算法可以準確模擬火焰在一定時間內的擴散
01 蝴蝶效應,機器學習可以解決?
在最新的計算機實驗中,人工智慧演演算法能很好的預測混沌系統的未來。
半個世紀以前,混沌理論的先驅發現了“蝴蝶效應”,使得長期的預測變得難上加難。即使是對複雜系統極小的幹擾(比如說天氣,經濟或其他事物)也會引發一連串相應的事件,最終形成完全不同的未來。如果我們不能更好更精確的理解這些系統的狀態,從而預見事件會發展成什麼樣,我們就會生活在不確定性中。

▲混沌理論的早期研究表明,對複雜系統極小的擾動會引發一連串事件,預測混沌系統很困難
但是現在機器可以幫忙。
在期刊《Physical Review Letters》和《Chaos》的新文章中,科學家使用了機器學習技術(這技術就是最近人工智慧盛行背後的技術)來預測混沌系統的演化,結果令人目瞪口獃。這種開創性的方法被專家盛贊,而且極有可能找到更廣闊的應用場景。
對此,來自德國不來梅Jacobs大學計算機系的教授Herbert Jaeger評價:機器學習在預測複雜系統的無序演化上的結果令人震驚。

▲Jaideep Pathak, Michelle Girvan, Brian Hunt 和 Edward Ott,他們的研究表明,機器學習是預測混沌系統的有力工具
這些發現來自於馬裡蘭大學的資深混沌理論學者 Edward Ott 和他的四個合作者。
02 用機器學習演演算法,成功預測火勢蔓延
Ott 等人使用了一種叫庫計算(Reservoir Computing)的機器學習演演算法來“學習”一種典型的、名叫Kuramoto-Sivashinsky方程的混沌系統。
這個方程的演化結果像是一個火焰鋒面,閃爍著就像是火焰穿過了易燃介質。這個方程也描述了等離子體和其他類似現象中的漂移波。Ott的學生,同時也是文章的第一作者的 Jaideep Pathak 認為,這可以作為時空混沌與幹擾研究的基礎。
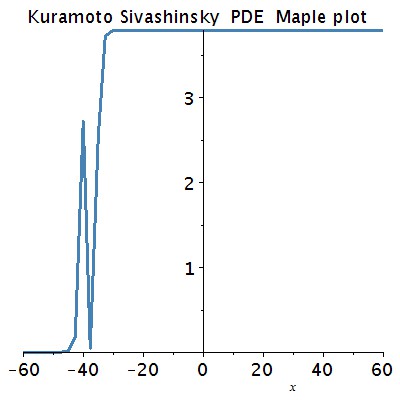
▲Kuramoto-Sivashinsky 系統的的動畫,“火焰鋒面”不是穩定變化的
在機器自主學習了 Kuramoto-Sivashinsky 系統演化的歷史資料後,計算機可以預測出這樣的類火焰系統,在未來8個 Lyapunov 時間內的演化。這種能力任何現有的手段都要強大8倍以上。
Lyapunov 時間是指一個動態系統出現混沌特性所需要的時間,是可預測性的的基準。在一個 Lyapunov 時間內,系統的變化是可以預測的,僅僅根據初始狀態,無法預測系統在一個 Lyapunov 時間之後的狀態。
德國馬普所的複雜系統研究專家 Holger Kantz,對“機器學習能預測8個 Lyapunov 時間的系統演化”的結果,贊嘆有加。
“機器學習的技術讓我們幾乎找到了混沌系統的真相!”
機器學習演演算法本身對 Kuramoto-Sivashinsky 方程一無所知,它只提取現有的關於方程解的資料。資料使得機器學習這種方法很強大,因為很多情況下,描述混沌系統的方程並不已知,這嚴重阻礙了流體動力學家透過研究模型來預測系統發展。

▲Kuramoto-Sivashinsky 方程和3D 示意圖
03 只要給我資料,無需氣象模型也能預測天氣
Ott和他同伴的研究結果顯示你不需要那些方程式,只需要資料。
Kantz說:“這篇文章顯示也許有一天我們可以用機器預測天氣,透過演演算法學習而不是透過研究複雜的大氣模型。”除了天氣預報,機器學習技術可以監控可能會引發心臟病的心律不齊,也可以檢測大腦中神經元的連線方式。進一步推斷,它還可以幫助預測可能危及船隻的巨浪,甚至預測地震。
Ott 特別希望新工具能提前給出太陽風暴的警告,像1859年噴出太陽錶面35000英里的那一次。地磁的巨變使得北極光在地球上隨處可見,感生電壓讓許多沒有通電的電線上產生了電流,直接斷掉了地球上的電報系統。如果今天地球受到這樣規模的太陽風暴襲擊,人類的電子設施會遭到嚴重破壞。
Ott說:“如果能預測太陽風暴的來襲,你只需要關停電源,之後再重啟就好了。”

▲太陽風暴會嚴重幹擾地球磁場,但是很難提前根據太陽的變化來預測太陽風暴的發生
04 核心技術:變數之間相互作用?神經元庫計算(reservoir of neurons)來解決
Ott、Pathak和他們的同事 Brian Hunt,Michelle Girvan 和 Zhixin Lu(現在在賓夕法尼亞大學)透過綜合利用現有的工具,取得了成果。
六七年前,名為”深度學習”的強大演演算法開始在像影象和語音識別這樣的人工智慧任務中大顯身手,這幾位科學家也開始學習機器學習,並思考如何將其應用到混沌系統中。
他們在深度學習革命之前就已經得到了一些有希望的結果。 其中最重要的一個是,在2000年代初,Jaeger 和另一位德國混沌理論家 Harald Haas,使用了一個神經元隨機連線形成的神經網路,這些神經元形成了庫計算的”庫”——稱之為“神經元庫”——來學習三個混沌系統協同變數的動力學法則。透過對三組數字的訓練,該網路可以預測這三個變數的未來值,且預測範圍之遠令人印象深刻。
然而,當變數之間有相互作用時,計算變得非常困難。
Ott和他的同事們需要一個更有效的方案,來實現與大型混沌系統相關的庫計算。這些系統有許多變數會相互影響。 例如,火焰前部邊緣的每一個位置,都對應著三個不同空間方向的速度分量,相鄰位置的速度不是獨立的。
他們花了幾年時間尋找直截了當的解決方案。 Pathak說:”我們利用的是空間擴充套件混沌系統中的相互作用的區域性性。 區域性性意味著一個地方的變數受到附近變數的影響,而不是遠處的其他變數。 Pathak解釋道,“透過使用神經元庫計算,我們基本上可以把問題分解成幾個大塊。” 也就是說,你可以並行處理這些問題,利用一個神經元庫來瞭解一個系統的一個塊,另一個來處理下一個塊,等等,並且用相鄰域的輕微重疊來解釋它們之間的相互作用。
並行化使得神經元庫計算方法幾乎可以處理任何尺尺度的混沌系統,只要分配相應的計算機資源專門用於這項任務。

▲機器學習的預測與混沌模型可以很好地吻合
05 三個步驟預測火勢蔓延
Ott 解釋說,神經元庫計算方法有三個步驟。 假設你想用它來預測火勢的蔓延。
首先,你測量火焰在火焰前部的五個不同點的高度。因為閃爍的火焰在一段時間內不斷產生,所以你繼續測量火焰前部這些點的高度,你將這些資料流輸入儲存庫中隨機選擇的人工神經元中。輸入資料會啟用神經元,依次觸發相連的神經元,併在整個網路傳送一系列訊號。
第二步是讓神經網路從輸入資料中學習火焰前部演化的動力學。為了做到這一點,當你輸入資料時,你也需要監視儲存器中幾個隨機選擇的神經元的訊號強度。 以五種不同的方式加權組合這些訊號,產生五個數字,作為輸出。我們的標的是調整計算輸出的各種訊號的權重,直到這些輸出始終與下一組輸入相匹配——下一組輸入就是下一時刻在火焰前部測量的五個新高度。Ott解釋說:“你想要的是,輸出應該和下一時刻的輸入相同”。
為了學習到正確的權重,演演算法只是簡單的將每一組輸出,或者說對五個點的火焰高度的預測,和下一組輸入,即下一時刻實際火焰高度做比較,以增加或減少各種訊號的權重的方式,使它們的組合對應五個正確的輸出值。從一個時間步到下一個時間步,隨著權重的調整,預測效果 逐漸變好,直到該演演算法能夠準確預測下一時刻的火焰狀態。
第三步,讓神經元庫做預測。在學到了這個系統的動力學法則之後,神經元庫計算方法可以揭示它將如何演化。在本質上,網路是在問自己即將會發生什麼。輸出以新輸入的形式反饋,接下來的輸出又將對應到下一時刻的輸入,周而複始,完成對火焰前部五個位置的高度如何演變的預測,並行的其他神經元庫也將預測出火焰中其他地方的高度演化。
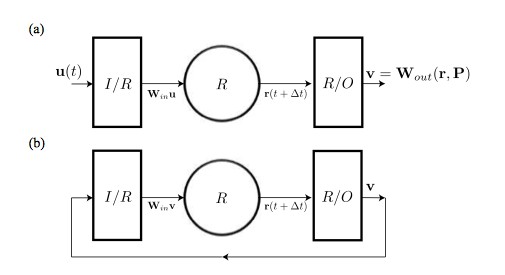
▲訓練階段和預測階段
06 預測混沌:引入機器學習、深度學習、LSTM
在1月份發表的 PRL (《Physical Review Letters》)論文中,研究人員發現,他們預測的火焰演化,與混沌系統的真實演化幾乎完全一致,直到第八個 Lyapunov 時間之後,預測才開始偏離實際情況。
通常,預測混沌系統的方法是,盡可能準確地測量一個混沌系統在某一時刻的狀態,同時利用資料來校準物理模型,然後將模型沿著時間慢慢向前擴充套件。由於是近似估計,必須將一個典型的系統的初始狀態測量100,000,000次(10的八次方),才能將初始狀態的資料用於更準確地預測混沌系統未來8個 Lyapunov 時間內的演化狀態。
相比之下,機器學習完全不需要測量這麼多的狀態。
這就是為什麼機器學習是“一種非常有用和強大的方法”,馬普所的Ulrich Parlitz表示。他和Jaeger(德國Jacobs大學計算科學教授)一樣,也在本世紀初將機器學習應用於低維混沌系統。“我認為機器學習不僅在他們發表的這個混沌系統的樣例預測中起作用,在某種意義上,機器學習具有普適性,可以應用於其他許多演化過程與系統。”
在即將發表在《Chaos》上的一篇論文中(鏈:http://www.bmp.ds.mpg.de/tl_files/bmp/preprints/Zimmermann_Parlitz_preprint.pdf),Parlitz和一位合作者應用了庫計算(Reservoir Computing,簡稱RC)模型來預測”易激發性介質”的動態,比如心臟組織。Parlitz認為,深度學習比庫計算模型框架更加複雜,計算更加密集,能很好地解決混沌問題,其他機器學習演演算法也將會是有效的方法。
最近,MIT和ETH Zurich的研究人員取得了類似的結果,Ott 團隊使用了一個“長短期記憶”(LSTM)神經網路,這種神經網路反覆迴圈能夠長時間儲存臨時資訊。
07 預測氣象資料,天有可測風雲
在PRL發表論文之後,Ott,Pathak,Girvan,Lu等人繼續推進他們的研究,現在他們距離理想的預測實驗更近了一步。
Ott 團隊在《Chaos》雜誌發表的新研究中表明,透過將資料驅動、機器學習方法、傳統的模型預測,可以進一步改進對像 Kuramoto-Sivashinsky 方程這樣的混沌系統的預測。
Ott認為,這是改善天氣預報及其類似工作的有效途徑,因為常常缺少完整的高解析度資料或完美的物理模型。他說:“我們應該利用我們所掌握的良好知識,如果我們對某個事物一無所知,我們就應該利用機器學習來填補無知。”
庫計算的預測可以校準氣象模型,在 Kuramoto-Sivashinsky 方程中,準確的預測時長被進一步推廣到了12個Lyapunov時間。不同系統到達Lyapunov時間所經歷的時間長度是不同的,從毫秒到數百萬年不等。 就天氣而言,只有幾天。時間越短,系統更容易受蝴蝶效應的影響。

▲在 netlogo 模擬軟體中模擬森林火災的蔓延
08 無處不在的混沌
混沌系統在自然界中無處不在,然而奇怪的是,混沌本身是很難確定的。
芝加哥大學的數學教授Amie Wilkinson說:“在動力系統中,大多數人都使用混沌這個術語,但這些人在使用‘混沌’時會覺得有些尷尬。因為它在沒有準確的數學定義的情況下吸引了人們的註意力。
Kantz(德國馬普所的混沌理論家)同意這樣的說法:“混沌並不是一個簡單的概念。在某些情況下,調整一個系統的單個引數可以使系統從混沌變為穩定,反之亦然。”
Wilkinson 用拉伸和摺疊來描述混沌,就像在做酥皮糕點時反覆拉伸和摺疊麵團一樣。每一塊麵團在擀麵杖下水平伸展,在兩個空間方向上以指數的速度迅速分離,然後將麵團摺疊壓平,在垂直的方向上將麵團錶面凸起凹陷的部分再壓平。
天氣、森林大火、太陽錶面的‘風暴’以及所有其他混沌的系統就是這樣運作的,為了讓混沌系統的軌跡指數發散,需要這種拉伸,為了不使系統發散到無窮遠處,需要一些摺疊。摺疊來自系統中變數之間的非線性關係。不同維度的拉伸和壓縮分別對應於一個系統的正負”Lyapunov指數”。
▲在狀態中切換,猶如鐘擺
09 為什麼有效?神經網路的機制仍待探究
在《Chaos》另一篇最新的論文中(連結:https://aip.scitation.org/doi/abs/10.1063/1.5010300?journalCode=cha&),Ott 團隊報告說,他們的庫計算模型,可以成功地從混沌系統進化資料中,學習到這些拉伸和壓縮的特徵指數的值。
庫計算的主要思想是,計算機根據反饋的資料調整混沌系統動力學的公式,直到這個公式能夠複製混沌系統的動態變化過程。這個技術的效果非常好,但其內部的學習機制卻很少有人清楚。
最終,雖然庫計算可以很好的學習混沌動力學,但很多人並不理解庫計算到底為什麼能學的這麼好。事實上,Ott和其他一些馬裡蘭州的研究人員現在打算用混沌理論來更好地理解神經網路的內部機制。

譯者:Frank、陳孟園、張章
原文:
https://www.quantamagazine.org/machine-learnings-amazing-ability-to-predict-chaos-20180418/
推薦閱讀
Q: 你相信機器學習能夠成功預測未來嗎?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視

