在企業內使用Kubernetes,對部署在Kubernetes上的應用做訪問控制是比較基本的安全需求,不但要控制外部流量,而且各服務之間的流量也要兼顧。對此Kubernetes也給出了官方的解法——NetworkPolicy。然而,這還要仰仗各網路驅動的支援程度。而對於不同型別的網路驅動(如基於路由技術或隧道技術)又各有各的解法和困難。文章中,我們將剖析主流Kubernetes網路驅動是如何支援NetworkPolicy的,同時,分享面對公有雲複雜需求摸索的經驗和企業落地Kubernetes私有雲的解決思路。
在企業內使用Kubernetes,其上部署的應用是否需要嚴格的訪問控制,這個答案並不總是肯定的,至少支援訪問控制並不是方案選型時的優先考慮要素。但對於我們行雲創新來講,這種控制必不可少。因為,我們提隊供的公有雲業務允許任何個人和團自由地開發和部署應用到任意雲端,那麼為每位使用者的應用提供安全可靠的訪問控制是一個十分基本的要求。相信我們對公有雲複雜需求的摸索經驗和一些解決思路也將對眾多企業落地Kubernetes私有雲非常有借鑒意義。

Kubernetes提供了一種叫NetworkPolicy的物件,專門用來解決L3/L4訪問控制的問題。然而,它只定義瞭如何制定這些策略,而它們如何來發揮作用卻還要仰仗各Kubernetes網路外掛的支援程度。而對於不同型別的網路外掛在支援NetworkPolicy方面又有各自的解法和麵臨的挑戰。
在本次分享中,我們將在簡單分析主流Kubernetes網路外掛如何支援NetworkPolicy之餘,講述行雲創新在實現訪問控制的過程中遇過到的那些挑戰,以及它們又是如何被解決的。
首先我們來聊聊Kubernetes NeworkPolicy 物件 。
簡單的說,NetworkPolicy是透過定義策略對選定Pod進行網路通訊控制的,這樣可以讓執行在POD裡的業務受到安全保護。Kubernetes早在1.6版本中就支援了NetworkPolicy物件,但只能透過Selector對Pod間通訊進行控制,直至1.8版本在NetworkPolicyPeer物件支援IPBlock之後,才具備了透過指定IP段(CIDR)的方式對叢集內外訪問進行全面控制。
下麵我們分析一下NetworkPolicy是如何工作的。
上圖是NetworkPolicy物件的結構平鋪圖。NetworkPolicy的作用域在Namespace內,它透過podSelector來確定哪些Pod將受這個policy約束。在一個NetworkPolicy物件中,可以設定多條NetworkPolicyEgressRule和NetworkPolicyIngressRule,分別用來做出口和入口的訪問控制。每條Rule由一組NetworkPolicyPeer和一組NetworkPolicyPort組成,意思比較明確,這組Peers的這些Ports被授予了訪問許可權。
NetworkPolicyPeer則可以是兩類資源,其一是透過namespace selector和pod selector來篩選出Pod,另一則是前文提到過的IPBlock,它透過CIDR來指定。具體的配置方式可以參考官方檔案:https://kubernetes.io/docs/concepts/services-networking/network-policies。
從上圖我們可以看出,無論Ingress還是Egress,NetworkPolicy定義的是Pod之間或者Pod和某些CIDR之間的關係。從Kubernetes的設計理念和訪問實際發生的位置來看,這樣的設計實在再合理不過。然而,卻給實現層面增加了不少複雜度,甚至可能會影響到是否能夠讓方案落地實現。問題主要出在以下幾方面。
Pod網路由各網路外掛提供的網路驅動支援,NetworkPolicy幾乎全部依賴這些網路驅動來實現,而不同原理的網路驅動並不一定能實現NetworkPolicy的全部功能,而且難易程度也有所不同,即便到了今天,Kubernetes已經釋出了1.10,NetworkPolicy仍然沒有被所有主流網路外掛完整支援。
雖然Pod網路由網路驅動實現,但Service網路卻是Kubernetes管理的,而Kubernetes應用都是透過Service向外提供服務的,這中間的轉換也會對NetworkPolicy的實現有嚴重的影響。
在遵循NetworkPolicy的前提下,同時還要考慮以下各種情況如何應對:
-
Pod訪問API server的情形
-
基於網路訪問的Probes(LivenessProbe和ReadinessProbe)
-
kube-proxy的–masquerade-all選項的開啟和關閉
-
NodePort型別的Service是否會受到影響
-
叢集擴容時NetworkPolicy的考慮等
接下來我們簡單分析一下主流的網路外掛對NetworkPolicy的支援程度。
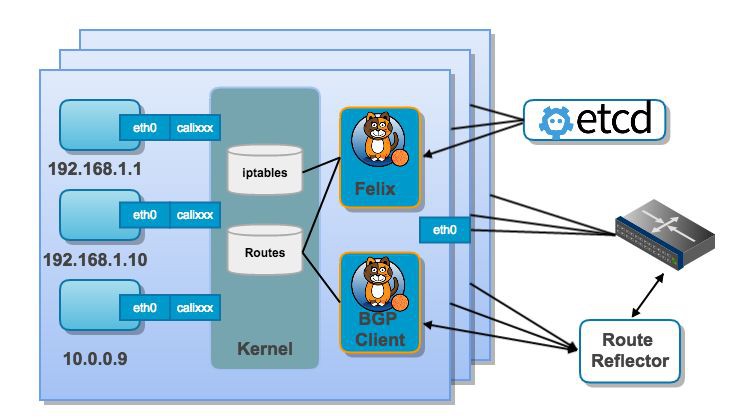
Calico提供的是一個基於路由的解決方案,也就是說Pod之間的互動將透過在Node上生效的各種路由規則來實現。如下圖所示。
Calico部署完成後,每臺Node上的Calico元件Felix會負責根據etcd中的配置來修改路由和iptables規則。Calico的元件BIRD則負責將這些路由策略分發到其他Node。Calico不但支援NetworkPolicy的特性,還支援了更多的安全策略,使用者可以透過calicoctl客戶端來配置,而這些特性也皆是透過iptables來實現的。
Flannel的標的在於解決Node之間的網路互聯問題,它支援眾多實現方式,不僅包括VxLAN,IPIP等普遍的實現方式,還可以和不少公有雲的網路設施直接整合,對於在公有雲上部署Kubernetes叢集十分友好。然而它旨在解決網路通訊的問題,因此並不支援NetworkPolicy。官方的建議是配合在這方面擅長的Calico來使用,或者使用Canal。
Cilium是一個十分有趣的專案,在組網方面它同時提供了基於路由的組網方式和基於VxLAN的Overlay網路。而在訪問控制方面,它使用了BPF而非Netfilter。如下圖所示。
比起其他的網路驅動,Cilium還比較年輕,尚未完全支援NetworkPolicy,但是它提供了CiliumNetworkPolicy物件用來提供更多的訪問控制特性,不只包括L3/L4的訪問控制,甚至涵蓋了L7的訪問控制,十分了得。
WeaveNet提供了一種十分便利的方式在Kubernetes主機之間構建一個Overlay網路,工作原理如下圖所示。
WeaveNet在Kubernetes上以DaemonSet的形式部署,每個Pod中包含兩個容器,分別是weave-kube和weave-npc。前者負責構建網路,後者則是[n]etwork-[p]olicy-[c]ontroller。WeaveNet需要在每臺主機上建立一個bridge,作為主機上所有接入weave網路的Pod的閘道器,不同主機的bridge之間的資料流則會透過VxLAN協議轉發,其他的資料流都會在主機上經過SNAT從而進入主機網路。
對於NetworkPolicy,WeaveNet僅僅支援NetworkPolicyIngressRule和基於Selector的NetworkPolicyPeer,並不支援IPBlock型別的Peer。WeaveNet的實現方式和其他外掛類似,透過從API Server監聽NetworkPolicy的狀態,修改主機上iptables策略和ipset來實現控制。
行雲創新的公有雲服務必須要具備跨多個雲供應商的能力來幫助使用者解除對單一雲依賴,並構築成本優勢。不同的雲廠商,如阿裡、華為、Azure、Ucloud、AWS等提供的網路架構和網路能力是差異很大的, 這就決定了我們必然會面對十分複雜並且多樣的網路環境,也應該選擇一種與各公雲的網路架構相容最好的Kubernetes網路方案。 先看看我們曾經在阿裡上遇到的一個問題:
阿裡雲在網路底層採用了ARP劫持技術,所有網路通訊(包括L2)都要到閘道器中轉,自定義的“非法網路” 將被丟棄,此時需要在阿裡雲平臺上的路由表中增加策略,才有可能成功。而其它家雲在這些方面的行為又會大不相同,包括可能會存在路由表條目數量的限制。因此,基於路由技術的網路外掛,如Calico就不是最合適的選擇。
那麼看看基於“隧道”技術的實現方案。同樣使用VxLAN技術的Flannel和WeaveNet要如何選擇呢?WeaveNet除了配置簡單,它還有一個獨特的功能,那就是它並不要求所有主機必須處於full mesh network中,對於如下這種網路拓撲它也能夠支援。
所以行雲創新在公有雲的實現上選擇了WeaveNet,但如同其它網路外掛一樣,在NetworkPolicy的支援上,它也無法完全滿足我們應對的公有雲環境下應用控問控制需求。
對於我們來說,對NetworkPolicy最迫切的需求當是支援IPBlock型別的NetworkPolicyPeer,這也是多叢集管理的需要。試想多個微服務分別部署在不同地理位置、不同雲商的叢集中時,IPBlock是Kubernetes給我們的唯一選擇。為什麼WeaveNet只支援了透過Selector來定義NetworkPolicyPeer,IPBlock不能用類似的方法來實現嗎?那我們必須來分析一下。
weave-npc透過API Server監聽NetworkPolicy的變化,並隨之改變配置。它在得到NetworkPolicyPeer物件後,根據其中的Selector篩選出符合條件的Pod,在得到Pod的IP地址後便可以在Pod所在主機iptables的Filter表中設定規則,接受來自這些地址的請求。當然,實際的實現方式要更高效和複雜一點。那麼基於IPBlock的NetworkPolicyPeer是否也能如此簡單?答案當然是否定的,至於原因還要從如何從叢集外訪問到叢集內應用說起,我們稱之為L3接入方式。
Kubernetes以Service的方式管理L3接入,那麼便可以透過LoadBalancer和NodePort直接從叢集外訪問Service,這是比較常見的方式。但技術上來講,我們還可以打通叢集外到ClusterIP的路由,來直接訪問Service的ClusterIP。照此原理,若大家希望從叢集外直接訪問Pod網路本身,透過直接路由的方式也是可以達成的,只不過要把Pod的IP暴露到全網中。
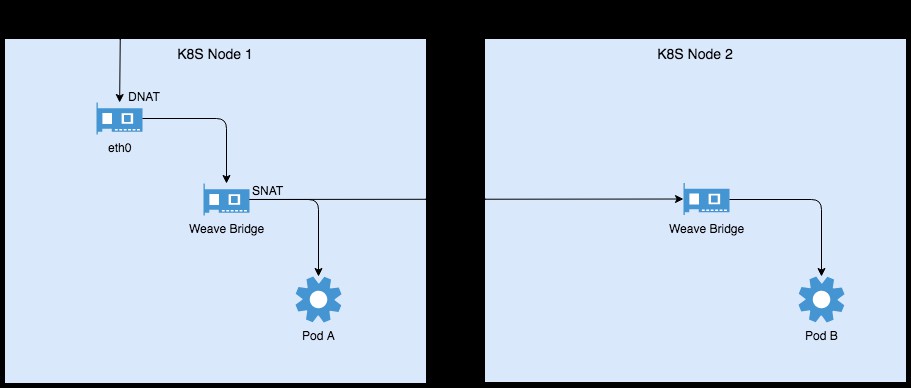
如上圖所示,無論是透過NodePort還是直接訪問Service ClusterIP的方式來接入,所有請求都會在進入主機網路時經過DNAT,將標的地址和埠轉換成Service對應的Pod及其埠。而在經由Weave bridge將請求轉發到Pod或者另一臺Node的Weave Bridge前(此時會透過隧道方式以VxLAN協議傳輸)會再做一次SNAT,將源地址修改為Weave Bridge的地址,這是Kubernetes確定的規則。
若我們如法炮製實現IPBlock,必然會面對這樣的難題。如上圖示例,Node2在接收到對PodB的請求時,該請求已然在Node1上經過了SNAT,其源地址已經變成了Node1上Weave Bridge的地址,而非原始的源地址,此時再在Node2上執行NetworkPolicy怕是會發生錯誤,因為我們想要做訪問控制的是原始的源地址。那麼Kubernetes為何要在這個關鍵位置做SNAT?這是必須的嗎?
面對這個問題,我們的解決思路是,只要將針對每個Pod的NetworkPolicy應用到所有的Node上而非僅僅在Pod所在的Node上即可,如同kube-proxy一樣。這樣,WeaveNet就可以全面支援單Kubernetes叢集的NetworkPolicy了。此外,還有一個有趣的問題值得思考,Pod和Node之間的互動是否要受NetworkPolicy的約束[?這個問題我將在稍後和各位朋友加以分析。
接下來,我們來講述一個更加複雜的場景,也是行雲創新要面對的場景,即將不同的微服務部署到不同地理位置、不同雲商的Kubernetes叢集,它們要如何相互訪問,又如何來做訪問控制呢?為了延續使用者在Kubernetes叢集中的使用習慣和程式碼習慣,在跨叢集部署服務時維持Service和Kubernetes的服務發現機制是必須的(跨地理位置、跨雲商的服務發現我們會在未來分享中詳細加以交流)。請看下圖。
從路由的角度來看,跨叢集訪問並沒有什麼特別之處,打通雙向路由即可。然而WeaveNet提供的是Overlay的解決方案,主機網路上並不存在到Pod網路的路由策略,所有的Pod到叢集外的訪問均在從主機網絡卡發出時做了SNAT,故在Cluster2的Node上看到的請求源地址是Cluster1的Node地址,而非Pod A的地址,因此不能在Cluster2上簡單地使用Pod A的地址透過IPBlock配置NetworkPolicy。
那麼WeaveNet在此時做SNAT是必要的嗎?答案是肯定的。Pod網路和主機網路是相互隔離的,若他們要互相訪問,則必須要建立起路由(Calico的做法),或者在這種特殊架構的前提下使用SNAT,使得Pod網路保持獨立且不汙染外部網路環境。那麼為了實現跨叢集的訪問控制,我們必須對從Pod發出的請求區別對待,若是訪問其他叢集的Service則不需要SNAT,否則依然要做SNAT。
至此,WeaveNet在行雲創新跨地理位置、跨雲商的場景下的連通和訪問控制就完全實現了,而且它最大限度地繼承了使用者對Kubernetes的使用習慣。至於如何使用和開髮網路外掛,關鍵還是在於充分理解Kubernetes對Service和Pod網路的定義。
最後,對於前文中提出的問題“Pod和Node之間的互動是否要受NetworkPolicy的約束?”來分享一下我們的思考。
從完整性的角度來講,一旦開啟了NetworkPolicy,那麼所有的互動都應當受其控制,這其中自然包括Pod和Node之間的通訊。此時就需要考慮,當Pod需要訪問API Server或者設定Probe策略時,為它們開通訪問控制的責任是否要交給使用者?使用者是否有足夠的資訊來完成這些設定?但從運營的角度來講,叢集中所有的Node都在運營商的控制中,是安全的,也就可以認為Pod和這些Node之間的通訊也是安全的。
當然,在跨地址位置、跨雲商的複雜公有雲環境中部署業務其所面臨的挑戰和技術陷阱並非今天的分享就能夠介紹全面的。
Q:根據http://cmgs.me/life/docker-network-cloud的測試,Weave網路方案在效能上比其他方案差很多,這是真的嗎?
A:該文章測試的時候並未開啟fast-data-path,經過我們的測試,在fast-data-path開啟的情況下,還是很可觀的。況且這個測試到今天已經過去了2年時間,Weave社群一直以來還是很活躍的,相信未來只會更好。
Q:請問針對Azure和AWS在網路方面有沒有遇到什麼坑?好像前面只看到Aliyun的。
A:AWS有個“源/標的地址檢查”,華為雲也有類似功能,如果在你的網路設計中雲主機出來或進去的IP與註冊的雲主機IP不符,則需要把它關掉,另外如果不關“源/標的”地檢查,也無法把標的主機設定成路由的next-hop;Azure主要就是預設動態公網IP,需要調整成固定IP。另外要特別註意主機間copy資料的流量費。
AWS上設定Kubernetes for Windows確實大費周折,我們當時和Kubernetes社群的Windows AIG的人一起搞了個方案,比較複雜。
Q:有沒有什麼辦法為每個名稱空間設定一個全域性的NetworkPolicy,還是說必須要先建立名稱空間才能定義NetworkPolicy(希望是就像ClusterRoleBinding一樣)?
A:至少現在還不可以,一般來說這不應該是普遍的需求,因為每個應用在一個Namespace下,而每個應用的的訪問控制策略不大可能是相同的。從另一個方面看,以Kubernetes社群的風格,任何普遍的需求最終都是會被實現的,而且速度很快。
本次培訓內容包括:Docker基礎、容器技術、Docker映象、資料共享與持久化、Docker三駕馬車、Docker實踐、Kubernetes基礎、Pod基礎與進階、常用物件操作、服務發現、Helm、Kubernetes核心元件原理分析、Kubernetes服務質量保證、排程詳解與應用場景、網路、基於Kubernetes的CI/CD、基於Kubernetes的配置管理等,點選瞭解具體培訓內容。
長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。