
本期內容選編自微信公眾號「開放知識圖譜」。
TheWebConf 2018

■ 連結 | https://www.paperweekly.site/papers/1956
■ 解讀 | 花雲程,東南大學博士,研究方向為自然語言處理、知識圖譜問答
動機
對於 KBQA 任務,有兩個最為重要的部分:其一是問題物體識別,即將問題中的主題物體識別出來,並與 KB 做物體連結;其二是謂詞對映。
對於主題物體識別任務,之前的做法多為依靠字串相似度,再輔以人工抽取的特徵和規則來完成的。但是這樣的做法並沒有將問題的語意與物體型別、物體關係這樣的物體資訊考慮進來。
物體型別和物體關係,很大程度上,是與問題的背景關係語意相關的。當只考慮物體關係時,會遇到 zero-shot 的問題,即測試集中某物體的關係,是在訓練集中沒有遇到過的,這樣的物體關係就沒法準確地用向量表達。
因此,為瞭解決上述問題,本文首先利用 entity type(物體型別)的層次結構(主要為物體型別之間的父子關係),來解決 zero-shot 的問題。
如同利用 wordnet 計算 word 相似度的做法一般,文章將父型別的“語意”視為所有子型別的“語意”之和。一個物體總是能夠與粗顆粒的父型別相關,例如一個物體至少能夠與最粗顆粒的 person、location 等型別相連。這樣,利用物體所述的型別,在考慮物體背景關係時,就可以一定程度上彌補物體關係的 zero-shot 問題。
此外,本文建立了一個神經網路模型 Hierarchical Type constrained Topic Entity Detection (HTTED),利用問題背景關係、物體型別、物體關係的語意,來計算候選物體與問題背景關係的相似度,選取最相似的物體,來解決 NER 問題。
經過實驗證明,HTTED 系統對比傳統的系統來說,達到了目前最優的物體識別效果。
貢獻
文章的貢獻有:
-
利用父子型別的層次結構來解決稀疏型別訓練不充分的問題;
-
設計了基於 LSTM 的 HTTED 模型,進行主題物體識別任務;
-
提出的模型透過實驗驗證取得了 state-of-art 的效果。
方法
本文首先對於父子型別的層次結構進行解釋和論述,也是 HTTED 的核心思想。
本文認為,父型別的語意視為接近於所有子型別的語意之和。例如父型別 organization 的語意,就相當於子型別 company、enterprise 等語意之和。如果型別是由定維向量表示,那麼父型別的向量就是子型別的向量之和。
此外,由於在資料集中,屬於子型別的物體比較稀疏,而父型別的物體稠密,如果不採用文中的方法,那麼稀疏的子型別將會得不到充分的訓練。若將父型別以子型別表示,那麼父子型別都可以得到充分地訓練。

▲ 圖1:HTTED模型圖
其次是對文中模型的解釋。如上圖 1 所示,HTTED 使用了三個編碼器來對不同成分編碼。
其一,是問答背景關係編碼器,即將問題經過分詞後得到的 tokens,以預訓練得到的詞向量來表示,並依次輸入雙向 LSTM 進行第一層的編碼;此後,將雙向 LSTM 得到的輸出拼接,再輸入第二層的 LSTM 進行編碼,即得到表示問題背景關係的 d 維向量 q。
其二,是物體型別編碼器,即對於某個候選物體 e,得到其連線的型別,並將父型別以所有子型別向量之和表示,再將這些型別對應的向量輸入一個 LSTM 中進行編碼,得到物體型別的 d 維向量 et。
其三,是物體關係編碼器,即對於某個候選物體 e,得到其所有物體關係,並表示成向量。此外,對於物體關係,將其關係名切割為 tokens,並以詞向量表示。然後將物體關係和物體關係名這兩種向量,輸入一個 LSTM 中進行編碼,得到物體關係的d維向量 er。
得到三個向量後,文章認為物體的語意可以由物體型別、物體關係近似表達,所以有:

而在訓練時,設定一個 margin,則 ranking loss 為:

其中 γ 為超引數。
實驗結果
文章使用單關係問答資料集 SimpleQuestions 和知識圖譜 FB2M,並有 112 個具有層次父子關係的物體型別。
HTTED 的詞向量為經過預訓練的,關係向量是初始隨機的,而型別向量中,葉子型別初始隨機,父型別的向量由子型別的向量累加得到。如下圖 2 所示,為 HTTED 與其他系統的效果對比,其中 -Hierarchy表示 HTTED 去除了物體型別的層次結構表示。
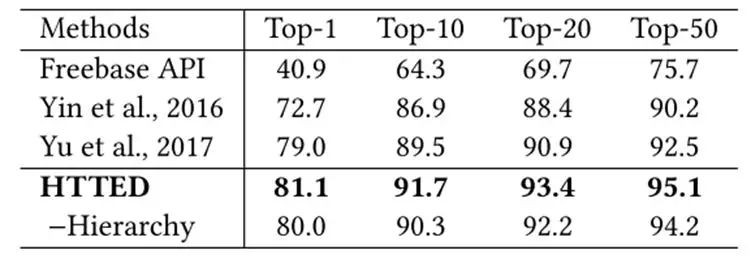
▲ 圖2:主題物體識別效果對比圖
由圖 2 可見,HTTED 為 state-of-art 的效果。並且,將物體型別的層次結構去除,HTTED 的準確性下降很多。可見層次型別約束對於該模型的重要性。
由下圖 3 可見,由於使用了層次結構的型別,同名的物體被識別出來,但是與問題背景關係更相關的物體都被挑選出來,所以能夠正確識別到主題物體。

▲ 圖3:主題物體識別示例圖
總結
這篇文章,主要有兩個主要工作:其一,是引入了層次結構的物體型別約束,來表達物體的語意,使得與問題背景關係相關的物體,更容易被找到;其二,是建立了基於 LSTM 的 HTTED 模型,提高了主題物體識別的效果。
AAAI 2018

■ 連結 | https://www.paperweekly.site/papers/1957
■ 解讀 | 張文,浙江大學博士生,研究方向知識圖譜的分散式表示與推理
動機
知識圖譜的分散式表示旨在將知識圖譜中的物體和關係表示到連續的向量空間中,本文考慮的問題是如何將知識庫的分散式表示和邏輯規則結合起來,並提出了一個新的表示學習方法 RUGE (Rule-Guided Embedding)。
貢獻
1. 本文提出了一種新的知識圖譜表示學習方法 RUGE,RUGE 在向量表示 (embeddings) 的學習過程中迭代地而非一次性地加入了邏輯規則的約束;
2. 本文使用的是已有演演算法自動挖掘的規則,RUGE 的有效性證明瞭演演算法自動挖掘的規則的有效性;
3. 本文提出的方法 RUGE 具有很好的通用型,對於不同的邏輯規則和不同置信度的規則的魯棒性較好。
方法 RUGE
RUGE 方法的輸入有三個部分:
-
已標記的三原組:知識庫中已有三元組;
-
未標記的三元組:知識庫中不存在的三元組。在這篇論文中未標記的三元組只考慮了能夠由邏輯規則推匯出的三元組;
-
機率邏輯規則:本文主要考慮了一階謂詞邏輯規則,每一個邏輯規則都標有一個成立的機率值。實驗中使用的機率規則來自於規則自動挖掘系統 AMIE+。
模型核心想法如下:
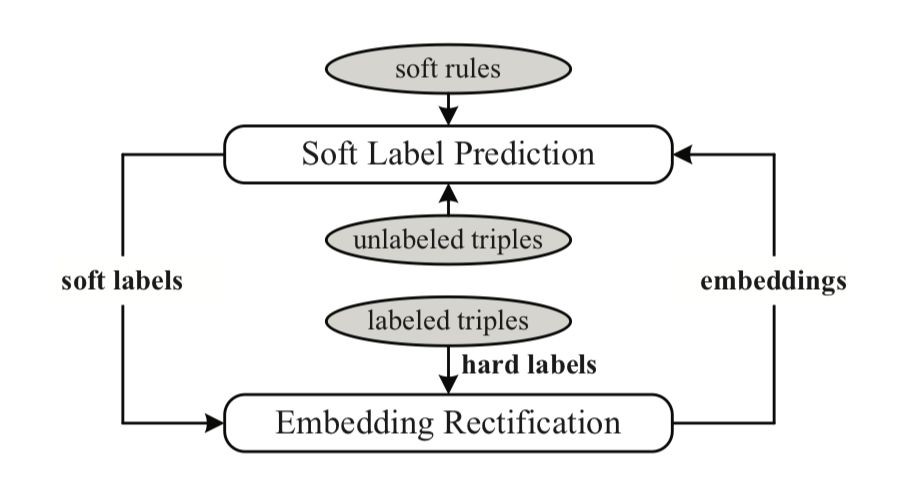
三元組表示:
本文采用了 ComplEx 作為基礎的知識庫分散式表示學習的模型,在 ComplEx中,每一個物體和關係都被表示為一個複數向量,一個三元組 (e_i,r_k,e_j) 的得分函式設計如下:
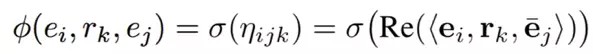
其中 Re
邏輯規則的表示:
本文借鑒了模糊邏輯的核心思想,將規則的真值看作其組成部件真值的組合。例如一個已經實體化的規則 (e_u, e_s,e_v) =(e_u, e_t,e_v) 的真值將由 (e_u, e_s,e_v) 和 (e_u, e_t,e_v) 的真值決定。根據(Guo et al. 2016)的工作,不同邏輯運算元的真值計算如下:
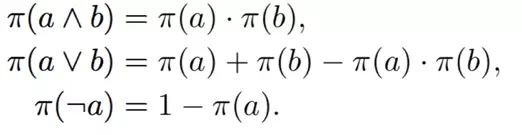
由上三式可推出規則真值計算公式:
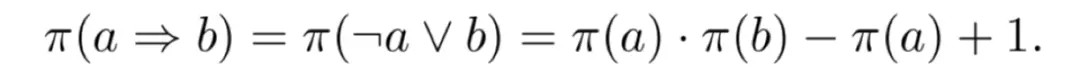
此規則計算公式是後面規則應用的一個重要依據。
未標記三元組標簽預測:
這一步是整個方法的核心,目的在於對未標記三元組的標簽進行預測,並將這些三元組新增到知識圖譜中,再次進行知識圖譜的分散式表示學習訓練,修正向量結果。
標簽預測的過程主要有兩個標的:
標的一:預測的標簽值要盡可能接近其真實的真值。由於預測的三元組都是未標記的,本文將由當前表示學習的向量結果按照得分函式計算出的結果當作其真實的真值。
標的二:預測的真值要符合對應邏輯規則的約束,即透過規則公式計算出的真值要大於一定的值。其中應用的規則計算公式如下:
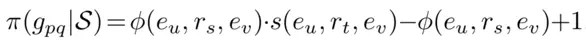
其中 φ(e_u, e_s,e_v) 是當前向量表示計算的結果,s(e_u, e_t,e_v) 是要預測的真值。真值預測的訓練標的如下:
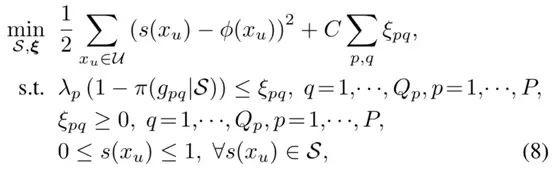
透過對上式對求 s(x_u) 導等於 0 可得到 s(x_u) 的計算公式:

向量表示結果的修正:
將預測了標簽的三元組新增到知識圖譜中,和已由的三元組一起進行訓練,來修正向量學習,最佳化的損失函式標的如下:

上式前半部分是對知識圖譜中真實存在的三元組的約束,後半部分為對預測了標簽的三元組的約束。
以上步驟在模型訓練過程中迭代進行。
實驗
連結預測:
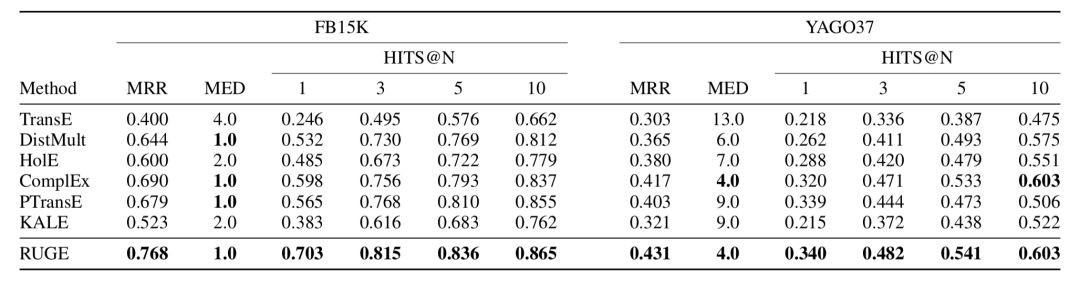
從實驗結果可以看出,規則的應用提升了表示學習的結果。
EMNLP 2017

■ 連結 | https://www.paperweekly.site/papers/713
■ 解讀 | 劉兵,東南大學在讀博士,研究方向為自然語言處理
動機
近年來基於深度學習方法的遠端監督模型取得了不錯的效果,但是現有研究大多使用較淺的 CNN 模型,通常一個捲基層加一個全連線層,更深的 CNN 模型是否能夠更好地解決以有噪聲的標註資料為輸入的遠端監督模型沒有被探索。
為了探索更深的 CNN 模型對遠端監督模型的影響,本文設計了基於殘差網路的深層 CNN 模型。實驗結果表明,較深的 CNN 模型比傳統方法中只使用一層摺積的簡單 CNN 模型具有較大的提升。
方法
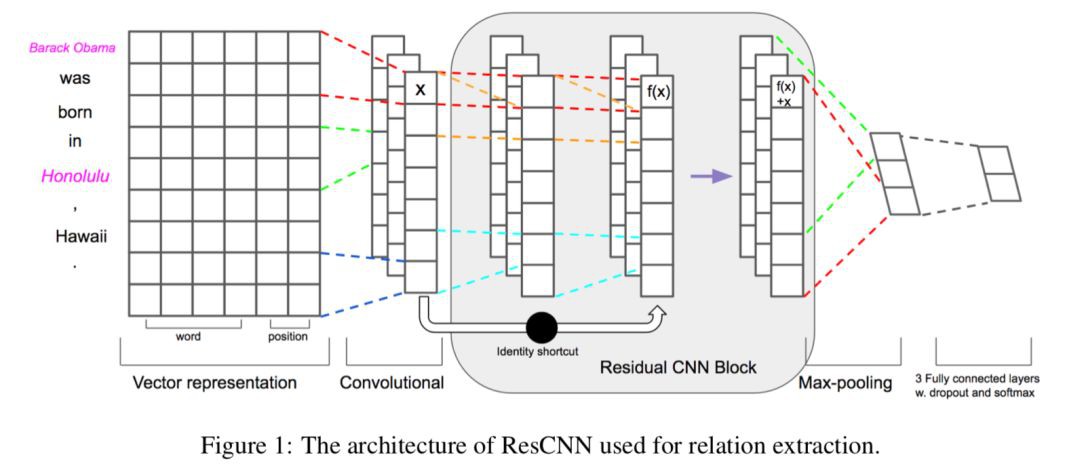
本方法的模型結構如下圖所示:
輸入層:每個單詞使用詞向量和位置向量聯合表示;
捲基層:為了得到句子更高階的表示,採用多個捲基層堆疊在一起。為瞭解決訓練時梯度消失的問題,在低層和高層的捲基層之間建立捷徑連線;
池化層和 softmax 輸出層。
實驗
實驗在遠端監督常用的資料集 NYT-Freebase 上進行。實驗結果表明:
本文提出的方法採用 9 個捲基層時達到最好的效果,這時不適用註意力機制和 piecewise pooling 效能也接近了使用註意力和 piecewise pooling 的方法。結果如下表所示。

不使用殘差網路的深層 CNN 模型,當層數較深時效果變差。使用殘差網路可以解決其無法傳播的問題,效果改善很多;結果如下圖所示。

EMNLP 2017

■ 連結 | https://www.paperweekly.site/papers/1960
■ 原始碼 | http://github.com/LiyuanLucasLiu/ReHession
■ 解讀 | 劉兵,東南大學博士,研究方向為自然語言處理
動機
現有的關係抽取方法嚴重依賴於人工標註的資料,為了剋服這個問題,本文提出基於異種資訊源的標註開展關係抽取模型學習的方法,例如知識庫、領域知識。
這種標註稱作異源監督(heterogeneous supervision),其存在的問題是標註衝突問題,即對於同一個關係描述,不同來源的資訊標註的結果不同。這種方法帶來的挑戰是如何從有噪聲的標註中推理出正確的標簽,以及利用標註推理結果訓練模型。
例如下麵的句子,知識庫中如果存在
Gofraid(e1) died in989, said to be killed in Dal Riata(e2).
為瞭解決這個問題,本文提出使用表示學習的方法實現為關係抽取提供異源監督。
創新點
本文首次提出使用表示學習的方法為關係抽取提供異源監督,這種使用表示學習得到的高質量的背景關係表示是真實標簽發現和關係抽取的基礎。
方法
文章方法框架如下:

▲ 關係描述表示方法
1. 文字特徵的向量表示。從文字背景關係中抽取出文字特徵(基於pattern得到),簡單的one-hot方法會得到維度非常大的向量表示,且存在稀疏的問題。為了得到更好的泛化能力,本文采用表示學習的方法,將這些特徵表示成低維的連續實值向量;
2. 關係描述的向量表示。在得到文字特徵的表示之後,關係描述文字依據這些向量的表示生成關係描述的向量表示。這裡採用對文字特徵向量進行矩陣變換、非線性變換的方式實現;
3. 真實標簽發現。由於關係描述文字存在多個可能衝突的標註,因此發現真實標簽是一大挑戰。此處將每個標註來源視為一個標註函式,這些標註函式均有其“擅長”的部分,即一個標註正確率高的語料子集。本方法將得到每種標註函式擅長的語料子集的表示,並以此計算標註函式相對於每個關係描述的可信度,最後綜合各標註函式的標註結果和可信度,得到最終的標註結果;
4. 關係抽取模型訓練。在推斷了關係描述的真實標簽後,將使用標註的語料訓練關係抽取器。
值得指出的是,在本方法中,每個環節不是各自獨立的,真實標簽發現與關係抽取模型訓練會相互影響,得到關係背景關係整體最優的表示方法。
實驗結果
本文使用 NYT 和 Wiki-KBP 兩個資料集進行了實驗,標註來源一方面是知識庫,另一方面是人工構造的模板。每組資料集進行了包含 None 型別的關係抽取,和不包含 None 型別的關係分類。
結果如下表所示,可見本文的方法相比於其他方法,在兩個資料集的四組實驗中均有較明顯的效能提升。

ACL 2017

■ 連結 | https://www.paperweekly.site/papers/1961
■ 原始碼 | https://github.com/stanfordnlp/cocoa
■ 解讀 | 王旦龍,浙江大學碩士,研究方向為自然語言處理
本文研究了對稱合作對話(symmetric collaborative dialogue)任務,任務中,兩個代理有著各自的先驗知識,並透過有策略的交流來達到最終的標的。本文還產生了一個 11k 大小的對話資料集。
為了對結構化的知識和非結構化的對話文字進行建模,本文提出了一個神經網路模型,模型在對話過程中對知識庫的向量表示進行動態地修改。
任務
在對稱合作對話任務中,存在兩個 agent,每個代理有其私有的知識庫,知識庫由一系列的項(屬性和值)組成。兩個代理中共享一個相同的項,兩個代理的標的是透過對話找到這個相同的項。
資料集
本文建立了一個對稱合作對話任務資料集,資料集中知識庫對應的 schema 中包含 3000 個物體,7 種屬性。資料集的統計資訊如下所示:

模型
針對對稱合作對話任務,本文提出了 DynoNet (Dynamic Knowledge GraphNetwork),模型結構如下所示:
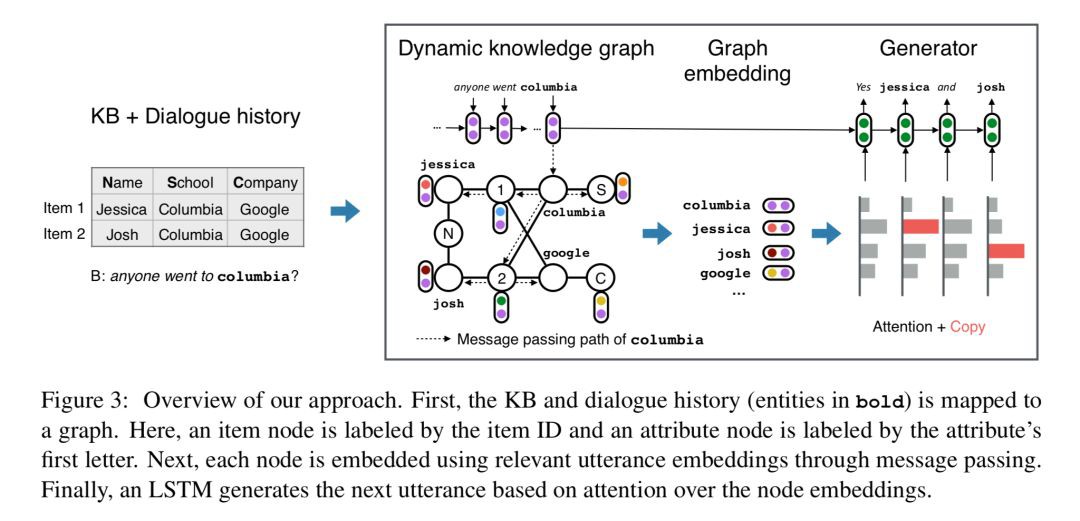
Knowledge Graph
圖譜中包含三種節點:item 節點,attribute 節點,entity 節點。圖譜根據對話中的資訊進行相應的更新。
Graph Embedding
t 時刻知識圖譜中每個節點的向量表示為 V_t(v),向量表示中包含了以下來源的資訊:代理私有知識庫的資訊,共享的對話中的資訊,來自知識庫中相鄰節點的資訊。
Node Features
這個特徵表示了知識庫中的一些簡單資訊,如節點的度(degree),節點的型別。這個特徵是一個 one-hot 編碼。
Mention Vectors
Mentions vector M_t(v) 表示在 t 時刻的對話中與節點 v 相關的背景關係資訊。對話的表示 u_t 由個 LSTM 絡計算得到(後文會提到),為了區分 agent 自身產生的對話陳述句和另一個代理產生的對話陳述句,對話陳述句表示為:
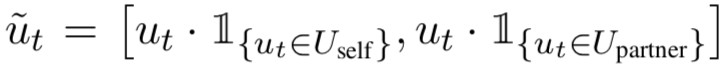
Mentions Vector 透過以下公式進行更新:

Recursive Node Embeddings
一個節點對應的向量表示也會受到相鄰其他節點的影響:

其中 k 表示深度為 k 的節點,R 表示邊對應的關係的向量表示。
最後節點的向量表示為一系列深度的值的連線結果。

本文中使用了:

Utterance Embedding
對話的向量表示 u_t 由一個 LSTM 網路計算得到。

其中 A_t 為物體抽象函式,若輸入為物體,則透過以下公式計算:
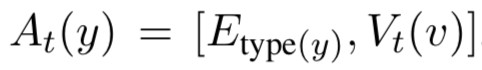
若不為物體,則為文字對應的向量表示進行 zero padding 的結果(保證長度一致)。
使用一個 LSTM 進行對話陳述句的生成:

輸出包含字典中的詞語以及知識庫中的物體:

實驗結果


點選以下標題檢視更多相關文章:

▲ 戳我檢視招募詳情
 #作 者 招 募#
#作 者 招 募#
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。


