點選上方“Java技術驛站”,選擇“置頂公眾號”。
有內涵、有價值的文章第一時間送達!
單表查詢之結果合併
接下來以執行 SELECT o.*FROM t_order o whereo.user_id=10order byo.order_id desc limit 2,3分析下麵這段Java程式碼是如何對結果進行合併的:
result = new ShardingResultSet(resultSets, new MergeEngine(resultSets, (SelectStatement) routeResult.getSqlStatement()).merge());code>
MergeEngine.merge()方法的原始碼如下:
<code class="java">public ResultSetMerger merge() throws SQLException {
selectStatement.setIndexForItems(columnLabelIndexMap);
return decorate(build());
}
build()方法原始碼如下:
private ResultSetMerger build() throws SQLException {
// 說明:GroupBy***ResultSetMerger在第六篇文章單獨講解,所以此次分析的SQL條件中沒有group by
if (!selectStatement.getGroupByItems().isEmpty() || !selectStatement.getAggregationSelectItems().isEmpty()) {
if (selectStatement.isSameGroupByAndOrderByItems()) {
return new GroupByStreamResultSetMerger(columnLabelIndexMap, resultSets, selectStatement);
} else {
return new GroupByMemoryResultSetMerger(columnLabelIndexMap, resultSets, selectStatement);
}
}
// 如果select陳述句中有order by欄位,那麼需要OrderByStreamResultSetMerger對結果處理
if (!selectStatement.getOrderByItems().isEmpty()) {
return new OrderByStreamResultSetMerger(resultSets, selectStatement.getOrderByItems());
}
return new IteratorStreamResultSetMerger(resultSets);
}
根據這段程式碼可知,其作用是根據sql陳述句選擇多個不同的ResultSetMerger對結果進行合併處理,ResultSetMerger實現有這幾種:GroupByStreamResultSetMerger,GroupByMemoryResultSetMerger,OrderByStreamResultSetMerger,IteratorStreamResultSetMerger,LimitDecoratorResultSetMerger;以測試SQL
SELECT o.*FROM t_order o whereo.user_id=10order byo.order_id desc limit 2,3為例,沒有group by,但是有order by,所以使用到了OrderByStreamResultSetMerger和LimitDecoratorResultSetMerger對結果進行合併(GroupByStreamResultSetMerger&GroupByMemoryResultSetMerger;後面單獨講解)
decorate()原始碼如下:
private ResultSetMerger decorate(final ResultSetMerger resultSetMerger) throws SQLException {
ResultSetMerger result = resultSetMerger;
// 如果SQL陳述句中有limist,還需要LimitDecoratorResultSetMerger配合進行結果歸併;
if (null != selectStatement.getLimit()) {
result = new LimitDecoratorResultSetMerger(result, selectStatement.getLimit());
}
return result;
}
接下來將以執行SQL:
SELECT o.*FROM t_order o whereo.user_id=10order byo.order_id desc limit 2,3(該SQL會被改寫成SELECT o.*,o.order_id AS ORDER_BY_DERIVED_0 FROM t_order_0 o whereo.user_id=?order byo.order_id desc limit 2,3)為例,一一講解OrderByStreamResultSetMerger,LimitDecoratorResultSetMerger和IteratorStreamResultSetMerger,瞭解這幾個ResultSetMerger的原理;
OrderByStreamResultSetMerger
OrderByStreamResultSetMerger的核心原始碼如下:
private final Queue<OrderByValue> orderByValuesQueue;
public OrderByStreamResultSetMerger(final List<ResultSet> resultSets, final List<OrderItem> orderByItems) throws SQLException {
// sql中order by列的資訊,實體sql是order by order_id desc,即此處就是order_id
this.orderByItems = orderByItems;
// 初始化一個優先順序佇列,優先順序佇列中的元素會根據OrderByValue中compareTo()方法排序,並且SQL重寫後傳送到多少個標的實際表,List的size就有多大,Queue的capacity就有多大;
this.orderByValuesQueue = new PriorityQueue<>(resultSets.size());
// 將結果壓入佇列中
orderResultSetsToQueue(resultSets);
isFirstNext = true;
}
private void orderResultSetsToQueue(final List<ResultSet> resultSets) throws SQLException {
// 遍歷resultSets--在多少個標的實際表上執行SQL,該集合的size就有多大
for (ResultSet each : resultSets) {
// 將ResultSet和排序列資訊封裝成一個OrderByValue型別
OrderByValue orderByValue = new OrderByValue(each, orderByItems);
// 如果值存在,那麼壓入佇列中
if (orderByValue.next()) {
orderByValuesQueue.offer(orderByValue);
}
}
// 重置currentResultSet的位置:如果佇列不為空,那麼將佇列的頂部(peek)位置設定為currentResultSet的位置
setCurrentResultSet(orderByValuesQueue.isEmpty() ? resultSets.get(0) : orderByValuesQueue.peek().getResultSet());
}
@Override
public boolean next() throws SQLException {
// 呼叫next()判斷是否還有值, 如果佇列為空, 表示沒有任何值, 那麼直接傳回false
if (orderByValuesQueue.isEmpty()) {
return false;
}
// 如果佇列不為空, 那麼第一次一定傳回true;即有結果可取(且將isFirstNext置為false,表示接下來的請求都不是第一次請求next()方法)
if (isFirstNext) {
isFirstNext = false;
return true;
}
// 從佇列中彈出第一個元素(因為是優先順序佇列,所以poll()傳回的值,就是此次要取的值)
OrderByValue firstOrderByValue = orderByValuesQueue.poll();
// 如果它的next()存在,那麼將它的next()再新增到佇列中
if (firstOrderByValue.next()) {
orderByValuesQueue.offer(firstOrderByValue);
}
// 佇列中所有元素全部處理完後就傳回false
if (orderByValuesQueue.isEmpty()) {
return false;
}
// 再次重置currentResultSet的位置為佇列的頂部位置;
setCurrentResultSet(orderByValuesQueue.peek().getResultSet());
return true;
}
繼續深入剖析:這段程式碼初看可能有點繞,假設執行SQL
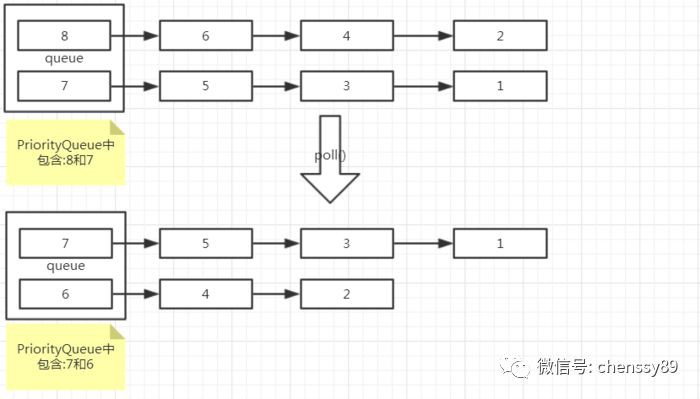
SELECT o.*FROM t_order o whereo.user_id=10order byo.order_id desc limit 3會分發到兩個標的實際表,且第一個實際表傳回的結果是1,3,5,7,9;第二個實際表傳回的結果是2,4,6,8,10;那麼,經過OrderByStreamResultSetMerger的構造方法中的orderResultSetsToQueue()方法後,Queue<OrderByValue>orderByValuesQueue中包含兩個OrderByValue,一個是10,一個是9;接下來取值執行過程如下:
取得10,並且10的next()是8,然後執行orderByValuesQueue.offer(8);,這時候orderByValuesQueue中包含8和9;
取得9,並且9的next()是7,然後執行orderByValuesQueue.offer(7);,這時候orderByValuesQueue中包含7和8;
取得8,並且8的next()是6,然後執行orderByValuesQueue.offer(6);,這時候orderByValuesQueue中包含7和6; 取值數量已經達到limit 3的限制(原始碼在LimitDecoratorResultSetMerger中的next()方法中),退出;
這段程式碼執行示意圖如下所示:

LimitDecoratorResultSetMerger
LimitDecoratorResultSetMerger核心原始碼如下:
public LimitDecoratorResultSetMerger(final ResultSetMerger resultSetMerger, final Limit limit) throws SQLException {
super(resultSetMerger);
// limit賦值(Limit物件包括limit m,n中的m和n兩個值)
this.limit = limit;
// 判斷是否會跳過所有的結果項,即判斷是否有符合條件的結果
skipAll = skipOffset();
}
private boolean skipOffset() throws SQLException {
// 假定limit.getOffsetValue()就是offset,實體sql中為limit 2,3,所以offset=2
for (int i = 0; i < limit.getOffsetValue(); i++) {
// 嘗試從OrderByStreamResultSetMerger生成的優先順序佇列中跳過offset個元素,如果.next()一直為true,表示有足夠符合條件的結果,那麼傳回false;否則沒有足夠符合條件的結果,那麼傳回true;即skilAll=true就表示跳過了所有沒有符合條件的結果;
if (!getResultSetMerger().next()) {
return true;
}
}
// limit m,n的sql會被重寫為limit 0, m+n,所以limit.isRowCountRewriteFlag()為true,rowNumber的值為0;
rowNumber = limit.isRowCountRewriteFlag() ? 0 : limit.getOffsetValue();
return false;
}
@Override
public boolean next() throws SQLException {
// 如果skipAll為true,即跳過所有,表示沒有任何符合條件的值,那麼傳回false
if (skipAll) {
return false;
}
if (limit.getRowCountValue() > -1) {
// 每次next()獲取值後,rowNumber自增,當自增rowCountValue次後,就不能再往下繼續取值了,因為條件limit 2,3(rowCountValue=3)限制了
return ++rowNumber <= limit.getRowCountValue() && getResultSetMerger().next();
}
return getResultSetMerger().next();
}
IteratorStreamResultSetMerger
構造方法核心原始碼:
private final Iterator<ResultSet> resultSets;
public IteratorStreamResultSetMerger(final List<ResultSet> resultSets) {
// 將List改成Iterator ,方便接下來迭代取得結果;
this.resultSets = resultSets.iterator();
// 重置currentResultSet
setCurrentResultSet(this.resultSets.next());
}
END

