
筆者邀請您,先思考:
1 機器學習模型如何解釋?
機器學習模型時常勝過模型的可解釋性,引數模型如線性回歸模型。模型效能的提高有一定的代價,模型當作一個無法解釋的黑盒子在運作。
幸運的是,有很多方法可以使機器學習模型可以解釋。 R包iml提供分析任何黑盒機器學習模型的工具:
-
特徵重要性:哪些是最重要的功能?
-
特徵效果:特徵如何影響預測? (部分依賴圖和個別條件期望曲線)
-
單一預測的解釋:單個資料點的特徵值如何影響其預測? (LIME和Shapley值)
-
替代樹:我們可以用一個簡短的決策樹來近似潛在的黑盒子模型嗎?
iml包適用於任何分類和回歸機器學習模型:隨機森林,線性模型,神經網路,xgboost等。
這篇文章向您展示了如何使用iml軟體包分析機器學習模型。 mlr軟體包使得機器學習模型的訓練變得非常容易,而iml軟體包可以輕鬆提取關於學習到的黑盒機器學習模型的見解。
如果您想瞭解更多關於所有方法的技術細節,請閱讀可解釋的機器學習手冊。

讓我們來探索iml工具箱,用具體的例子來解釋mlr機器學習模型!
資料:波士頓房屋擬合機器學習模型使用iml預測器容器特徵的重要性部分依賴替代模型用區域性模型解釋單一的預測用博弈論解釋單一的預測完整程式碼
資料:波士頓房屋
我們將使用MASS :: Boston資料集來演示iml包的功能。 該資料集包含來自波士頓社群的中位房屋價值。
data("Boston", package = "MASS")
head(Boston)

擬合機器學習模型
首先,我們訓練一個隨機森林來預測波士頓的房屋價值中位數:
if(!require(mlr)) {
install.packages("mlr")
require(mlr)
}
tsk data = Boston,
target = "medv"
)
lrn "regr.randomForest",
ntree = 100
)
mod 使用iml預測器容器
我們建立一個Predictor物件,它包含模型和資料。 iml包使用R6類:可以透過呼叫Predictor $ new()來建立新物件。Predictor與mlr模型最適合
(WrappedModel類),但也可以使用其他包中的模型。
if(!require(iml))
{
install.packages("iml")
require(iml)
}
X "medv")]
predictor y = Boston$medv)
特徵的重要性
我們使用FeatureImp可以測量每個特徵對於的預測有多重要。 特徵的重要性測量透過對每個特徵進行洗牌並測量效能下降情況而起作用。 對於這個回歸任務,我們選擇用平均絕對誤差(’mae’)來衡量模型效能的損失; 另一個選擇將是均方誤差(’mse’)。
一旦我們建立了FeatureImp的新物件,重要性就會自動計算出來。 我們可以呼叫物件的plot()函式或檢視data.frame中的結果。
imp $new(predictor, loss = "mae")
plot(imp)

imp$results

部分依賴
除了瞭解哪些特徵很重要之外,我們對特徵如何影響預測結果感興趣。 Partial類實現了部分依賴圖和單個條件期望曲線。 當我們改變其中一個特徵(例如,x軸上的’lstat’)時,每條線代表一個資料點的預測(y軸)。 突出顯示的行是各行的逐點平均值,並等於部分依賴圖。 x軸上的標記表示“lstat”特徵的分佈,顯示了一個區域與解釋的相關程度(很少或沒有意味著我們不應該過度解釋該區域)。
pdp.obj $new(predictor, feature = "lstat")
plot(pdp.obj)

如果我們想要計算另一個特徵的區域性依賴曲線,我們可以簡單地重置特徵。 另外,我們可以將曲線居中放置在我們選擇的特徵值處,這樣可以更容易地看到曲線的趨勢:
pdp.obj$set.feature("rm")
pdp.obj$center(min(Boston$rm))
plot(pdp.obj)

替代模型
另一種使模型更易解釋的方法是用一個更簡單的模型 – 一個決策樹來替代黑匣子。 我們對黑箱模型(在我們的例子中是隨機森林)進行預測,並對原始特徵和預測結果進行決策樹訓練。 該圖顯示了擬合樹的終端節點。 maxdepth引數控制樹可以增長的深度以及它是如何解釋的。
tree $new(predictor, maxdepth = 2)
plot(tree)
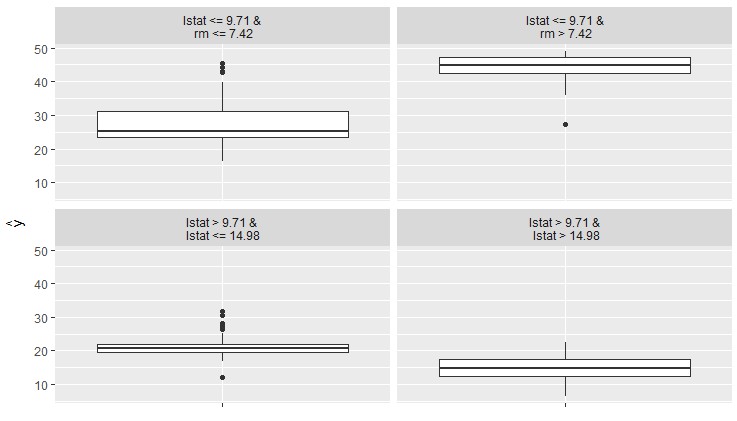
我們可以使用樹來做出預測:
head(tree$predict(Boston))

用區域性模型解釋單一的預測
全域性替代模型可以提高對全域性模型行為的理解。 我們也可以在擬合區域性模型,更好地理解單一預測。 由LocalModel擬合的區域性模型是一個線性回歸模型,資料點透過它們與資料點的接近程度來加權,以便我們解釋預測。
lime.explain $new(predictor, x.interest = X[1,])
lime.explain$results

plot(lime.explain)

用博弈論解釋單一的預測
解釋個人預測的另一種方法是來自聯合博弈論Shapley價值的一種方法。 假設對於一個資料點,特徵值一起玩遊戲,其中他們將預測作為支付。 Shapley值告訴我們如何公平分配特徵值之間的支付。
shapley $new(predictor, x.interest = X[1,])
plot(shapley)

我們可以重用該物件來解釋其他資料點:

data.frame表單中的結果可以像這樣提取:
results $results
head(results)

完整程式碼
# 任務描述:
# 機器學習模型的解釋
# 利用iml和mlr包
# 資料集
data("Boston", package = "MASS")
head(Boston)
# 擬合機器學習模型
if(!require(mlr)) {
install.packages("mlr")
require(mlr)
}
tsk data = Boston,
target = "medv"
)
lrn "regr.randomForest",
ntree = 100
)
mod # 模型的解釋信
if(!require(iml))
{
install.packages("iml")
require(iml)
}
X "medv")]
predictor y = Boston$medv)
# 特徵的重要性
imp "mae")
plot(imp)
imp$results
# 部分依賴圖
pdp.obj "lstat")
plot(pdp.obj)
pdp.obj$set.feature("rm")
pdp.obj$center(min(Boston$rm))
plot(pdp.obj)
# 替代模型解釋法
tree 2)
plot(tree)
head(tree$predict(Boston))
# 擬合區域性模型
lime.explain 1,])
lime.explain$results
plot(lime.explain)
# 博弈論分析法
shapley 1,])
plot(shapley)
shapley$explain(x.interest = X[2,])
plot(shapley)
results head(results)
原文連結:
https://mlr-org.github.io/interpretable-machine-learning-iml-and-mlr/
作者: Christoph Molnar
版權宣告:作者保留權利,嚴禁修改,轉載請註明原文連結。
資料人網是資料人學習、交流和分享的平臺http://shujuren.org 。專註於從資料中學習到有用知識。
平臺的理念:人人投稿,知識共享;人人分析,洞見驅動;智慧聚合,普惠人人。
您在資料人網平臺,可以1)學習資料知識;2)建立資料部落格;3)認識資料朋友;4)尋找資料工作;5)找到其它與資料相關的乾貨。
我們努力堅持做原創,聚合和分享優質的省時的資料知識!
我們都是資料人,資料是有價值的,堅定不移地實現從資料到商業價值的轉換!
文章推薦:
加入資料人圈子或者商務合作,請新增筆者微信。

點選閱讀原文,進入資料人網,獲取資料知識。
公眾號推薦:
鏈達君,專註於分享區塊鏈內容。

腳印英語,專註於分享英語口語內容。

