Prometheus是繼Kubernetes後第2個正式加入CNCF基金會的專案,容器和雲原生領域事實的監控標準解決方案。在這次分享將從Prometheus的基礎說起,學習和瞭解Prometheus強大的資料處理能力,瞭解如何使用Prometheus進行白盒和黑盒監控,以及Prometheus在規模化監控下的解決方案等。最後將從0開始構建完整的Kubernetes監控架構。

在《SRE:Google運維解密》一書中指出,監控系統需要能夠有效的支援白盒監控和黑盒監控。透過白盒能夠瞭解其內部的實際執行狀態,透過對監控指標的觀察能夠預判可能出現的問題,從而對潛在的不確定因素進行最佳化。而黑盒監控,常見的如HTTP探針,TCP探針等,可以在系統或者服務在發生故障時能夠快速通知相關的人員進行處理。透過建立完善的監控體系,從而達到以下目的:
-
長期趨勢分析:透過對監控樣本資料的持續收集和統計,對監控指標進行長期趨勢分析。例如,透過對磁碟空間增長率的判斷,我們可以提前預測在未來什麼時間節點上需要對資源進行擴容。
-
對照分析:兩個版本的系統執行資源使用情況的差異如何?在不同容量情況下系統的併發和負載變化如何?透過監控能夠方便的對系統進行跟蹤和比較。
-
告警:當系統出現或者即將出現故障時,監控系統需要迅速反應並通知管理員,從而能夠對問題進行快速的處理或者提前預防問題的發生,避免出現對業務的影響。
-
故障分析與定位:當問題發生後,需要對問題進行調查和處理。透過對不同監控指標以及歷史資料的分析,能夠找到並解決根源問題。
-
資料視覺化:透過視覺化儀錶盤能夠直接獲取系統的執行狀態、資源使用情況、以及服務執行狀態等直觀的資訊。
而對於上一代監控系統而言,在使用過程中往往會面臨以下問題:
-
與業務脫離的監控:監控系統獲取到的監控指標與業務本身也是一種分離的關係。好比客戶可能關註的是服務的可用性、服務的SLA等級,而監控系統卻只能根據系統負載去產生告警;
-
運維管理難度大:Nagios這一類監控系統本身運維管理難度就比較大,需要有專業的人員進行安裝,配置和管理,而且過程並不簡單;
-
可擴充套件性低: 監控系統自身難以擴充套件,以適應監控規模的變化;
-
問題定位難度大:當問題產生之後(比如主機負載異常增加)對於使用者而言,他們看到的依然是一個黑盒,他們無法瞭解主機上服務真正的執行情況,因此當故障發生後,這些告警資訊並不能有效的支援使用者對於故障根源問題的分析和定位。
在上述需求中,我們可以提取出以下對於一個完善的監控解決方案的幾個關鍵詞:資料分析、趨勢預測、告警、故障定位、視覺化。
除此以外,當前越來越多的產品公司遷移到雲或者容器的情況下,對於監控解決方案而言還需要另外一個關鍵詞:雲原生。
今天將從以下幾個方面來介紹下一代監控解決方案Prometheus是如何解決以上問題的:
-
初識Prometheus
-
讓資料會說話:PromQL與視覺化
-
Alertmanager與告警處理;
-
白盒與黑盒監控
-
規模化監控解決方案
-
從0開始監控Kubernetes叢集
Prometheus受啟發於Google的Brogmon監控系統(相似的Kubernetes是從Google的Brog系統演變而來),從2012年開始由前Google工程師在Soundcloud以開源軟體的形式進行研發,並且於2015年早期對外釋出早期版本。2016年5月繼Kubernetes之後成為第二個正式加入CNCF基金會的專案,同年6月正式釋出1.0版本。2017年底釋出了基於全新儲存層的2.0版本,能更好地與容器平臺、雲平臺配合。
從https://prometheus.io/download/獲取最新的node exporter版本的二進位制包後直接執行即可:
$ node_exporter
INFO[0000] Starting node_exporter (version=0.15.2, branch=HEAD, revision=98bc64930d34878b84a0f87dfe6e1a6da61e532d) source="
node_exporter.go:43"
INFO[0000] Enabled collectors: source="node_exporter.go:50"
INFO[0000] - time source="node_exporter.go:52"
INFO[0000] - meminfo source="node_exporter.go:52"
INFO[0000] - textfile source="node_exporter.go:52"
INFO[0000] - filesystem source="node_exporter.go:52"
INFO[0000] - netdev source="node_exporter.go:52"
INFO[0000] - cpu source="node_exporter.go:52"
INFO[0000] - diskstats source="node_exporter.go:52"
INFO[0000] - loadavg source="node_exporter.go:52"
INFO[0000] Listening on :9100 source="node_exporter.go:76"
訪問http://localhost:9100/metrics,可以看到Node Exporter獲取到的當前主機的所有監控資料,如下所示:
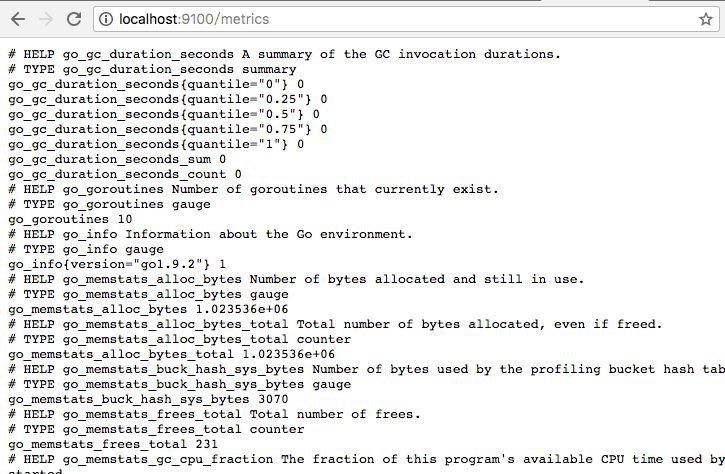
每一個監控指標之前都會有一段類似於如下形式的資訊:
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
node_load1 3.0703125
Node Exporter透過指標名稱和標簽傳回了當前主機的監控樣本資料。
從https://prometheus.io/download/找到最新版本的Prometheus Sevrer軟體包,目前這裡採用最新的穩定版本2.x.x。
建立配置檔案prometheus.yml,如下所示:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
$ prometheus --config.file=prometheus.yml --storage.tsdb.path=/data/prometheus
......
level=info ts=2018-03-11T13:38:06.317645234Z caller=main.go:486 msg="Server is ready to receive web requests."
level=info ts=2018-03-11T13:38:06.317679086Z caller=manager.go:59 component="scrape manager" msg="Starting scrape manager..."
訪問http://localhost:9090,進入到Prometheus Server。透過指標名稱node_load1,可以找到當前採集到的主機負載的樣本資料。

在上述的例子中,我們主要使用到了Node Exporter實體去獲取主機的監控資料,一個執行的Node Exporter實體稱為一個Target。Promthues週期性的從Node Exporter實體中獲取監控樣本,並儲存到Promtheus基於本地磁碟實現的時間序列資料庫中。

在Node Exporter的/metrics介面中傳回的每一行監控資料,在Prometheus下稱為一個樣本。採集到的樣本由以下三部分組成:
-
指標(metric):指標和一組描述當前樣本特徵的labelsets唯一標識;
-
時間戳(timestamp):一個精確到毫秒的時間戳,一般由採集時間決定;
-
樣本值(value): 一個folat64的浮點型資料表示當前樣本的值。
Prometheus會將所有採集到的樣本資料以時間序列(time-series)的方式儲存在記憶體資料庫中,並且定時儲存到硬碟上。每條time-series透過指標名稱(metrics name)和一組標簽集(labelset)命名。如下所示,可以將time-series理解為一個以時間為X軸的二維矩陣:

這種多維度的資料儲存方式,可以衍生出很多不同的玩法。 比如,如果資料來自不同的資料中心,那麼我們可以在樣本中新增標簽來區分來自不同資料中心的監控樣本,例如:
node_cpu{cpu="cpu0",mode="idle", dc="dc0"}
從內部實現上來看Prometheus中所有儲存的監控樣本資料沒有任何差異,均是一組標簽,時間戳以及樣本值。
從儲存上來講所有的監控指標metric都是相同的,但是在不同的場景下這些metric又有一些細微的差異。 例如,在Node Exporter傳回的樣本中指標node_load1反應的是當前系統的負載狀態,隨著時間的變化這個指標傳回的樣本資料是在不斷變化的。而指標node_cpu所獲取到的樣本資料卻不同,它是一個持續增大的值,因為其反應的是CPU的累積使用時間,從理論上講只要系統不關機,這個值是會無限變大的。
為了能夠幫助使用者理解和區分這些不同監控指標之間的差異,Prometheus定義了4中不同的指標型別(metric type):Counter(計數器)、Gauge(儀錶盤)、Histogram(直方圖)、Summary(摘要)。
Counter是一個簡單但有強大的工具,例如我們可以在應用程式中記錄某些事件發生的次數,透過以時序的形式儲存這些資料,我們可以輕鬆的瞭解該事件產生速率的變化。PromQL內建的聚合操作和函式可以使用者對這些資料進行進一步的分析:
例如,透過rate()函式獲取HTTP請求量的增長率:
rate(http_requests_total[5m])
與Counter不同,Gauge型別的指標側重於反應系統的當前狀態。因此這類指標的樣本資料可增可減。常見指標如:node_memory_MemFree(主機當前空閑的內容大小)、node_memory_MemAvailable(可用記憶體大小)都是Gauge型別的監控指標。
透過Gauge指標,使用者可以直接檢視系統的當前狀態:
node_memory_MemFree
對於Gauge型別的監控指標,透過PromQL內建函式delta()可以獲取樣本在一段時間傳回內的變化情況。例如,計算CPU溫度在兩個小時內的差異:
delta(cpu_temp_celsius{host="zeus"}[2h])
還可以使用deriv()計算樣本的線性回歸模型,甚至是直接使用predict_linear()對資料的變化趨勢進行預測。例如,預測系統磁碟空間在4個小時之後的剩餘情況:
predict_linear(node_filesystem_free{job="node"}[1h], 4 * 3600)
使用Histogram和Summary分析資料分佈情況
在大多數情況下人們都傾向於使用某些量化指標的平均值,例如CPU的平均使用率、頁面的平均響應時間。這種方式的問題很明顯,以系統API呼叫的平均響應時間為例:如果大多數API請求都維持在100ms的響應時間範圍內,而個別請求的響應時間需要5s,那麼就會導致某些WEB頁面的響應時間落到中位數的情況,而這種現象被稱為長尾問題。
為了區分是平均的慢還是長尾的慢,最簡單的方式就是按照請求延遲的範圍進行分組。例如,統計延遲在010ms之間的請求數有多少而1020ms之間的請求數又有多少。透過這種方式可以快速分析系統慢的原因。Histogram和Summary都是為了能夠解決這樣問題的存在,透過Histogram和Summary型別的監控指標,我們可以快速瞭解監控樣本的分佈情況。
例如,指標prometheus_tsdb_wal_fsync_duration_seconds的指標型別為Summary。 它記錄了Prometheus Server中wal_fsync處理的處理時間,透過訪問Prometheus Server的/metrics地址,可以獲取到以下監控樣本資料:
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
從上面的樣本中可以得知當前Promtheus Server進行wal_fsync操作的總次數為216次,耗時2.888716127000002s。其中中位數(quantile=0.5)的耗時為0.012352463,9分位數(quantile=0.9)的耗時為0.014458005s。
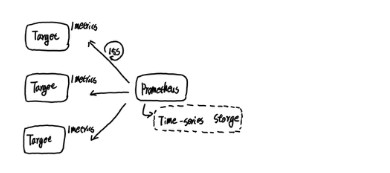
Prometheus對於資料的儲存方式就意味著,不同的標簽就代表著不同的特徵維度。使用者可以透過這些特徵維度對查詢,過濾和聚合樣本資料。
例如,透過node_load1,查詢出當前時間序列資料庫中所有名為node_load1的時間序列:
node_load1

如果找到滿足某些特徵維度的時間序列,則可以使用標簽進行過濾:
node_load1{instance="localhost:9100"}

透過以標簽為核心的特徵維度,使用者可以對時間序列進行有效的查詢和過濾,當然如果僅僅是這樣,顯然還不夠強大,Prometheus提供的豐富的聚合操作以及內建函式,可以透過PromQL輕鬆回答以下問題:
avg(irate(node_cpu{mode!="idle"}[2m])) without (cpu, mode)
topk(5, avg(irate(node_cpu{mode!="idle"}[2m])) without (cpu, mode))
predict_linear(node_filesystem_free{job="node"}[2h], 4 * 3600)

其中avg(),topk()等都是PromQL內建的聚合操作,irate(),predict_linear()是PromQL內建的函式,irate()函式可以計算一段時間傳回內時間序列中所有樣本的單位時間變化率。predict_linear函式內部則透過簡單線性回歸的方式預測資料的變化趨勢。
以Grafana為例,在Grafana中可以透過將Promtheus作為資料源新增到系統中,後再使用PromQL進行資料視覺化。在Grafana v5.1中提供了對Promtheus 4種監控型別的完整支援,可以透過Graph Panel,Singlestat Panel,Heatmap Panel對監控指標資料進行視覺化。
使用Graph Panel視覺化主機CPU使用率變化情況:


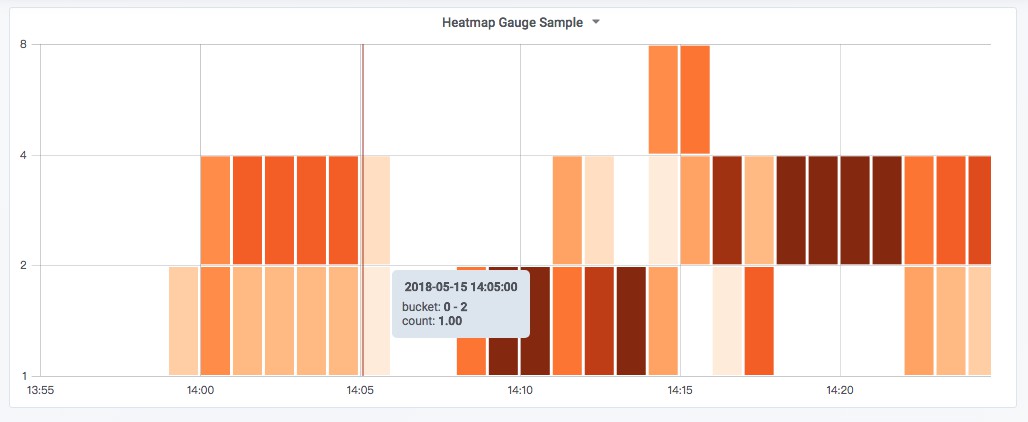
Prometheus透過PromQL提供了強大的資料查詢和處理能力。對於外部系統而言可以透過Prometheus提供的API介面,使用PromQL查詢相關的樣本資料,從而實現如資料視覺化等自定義需求,PromQL是Prometheus對內,對外功能實現的主要介面。

關於Grafana與Promthues的使用案例詳情可以參考:https://github.com/yunlzheng/prometheus-book/blob/master/grafana/README.md。
告警在Prometheus的架構中被劃分成兩個獨立的部分:告警產生和告警處理。
在Prometheus可以透過檔案的形式定義告警規則,Promthues會週期性的計算告警規則中的PromQL運算式判斷是否達到告警觸發條件,如果滿足,則在Prometheus內部產生一條告警。
yaml
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu{mode!='idle'}[5m]))) by (instance) > 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} CPU usgae high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
這裡定義當主機的CPU使用率大於85%時,產生告警。告警狀態將在Promethues的UI中進行展示。

到目前為止Promethues透過週期性的校驗告警規則檔案,從而在內部處罰告警。

而後續的告警處理則由Alertmanager進行統一處理。Alertmanager作為一個獨立的元件,負責接收並處理來自Prometheus Server(也可以是其它的客戶端程式)的告警資訊。Alertmanager可以對這些告警資訊進行進一步的處理,比如消除重覆的告警資訊,對告警資訊進行分組並且路由到正確的接受方,Alertmanager內建了對郵件,Slack等通知方式的支援,同時還支援與Webhook的通知整合,以支援更多的可能性,例如可以透過Webhook與釘釘或者企業微信進行整合。同時AlertManager還提供了靜默和告警抑制機制來對告警通知行為進行最佳化。

關於Alertmanager的詳細內容可以參考:https://github.com/yunlzheng/prometheus-book/blob/master/alert/README.md。
Prometheus作為是一個開源的完整監控解決方案,其對傳統監控系統的check-alert模型進行了徹底的顛覆,形成了基於中央化的規則計算、統一分析和告警的新模型。
在前面的部分中,我們主要介紹了Node Exporter的使用,對於這類Exporter而言,它們主要監控服務或者基礎設施的內部使用狀態,即白盒監控。透過對監控指標的觀察能夠預判可能出現的問題,從而對潛在的不確定因素進行最佳化。
而從完整的監控邏輯的角度,除了大量的應用白盒監控以外,還應該新增適當的黑盒監控。黑盒監控即以使用者的身份測試服務的外部可見性,常見的黑盒監控包括HTTP探針、TCP探針等用於檢測站點或者服務的可訪問性,以及訪問效率等。
黑盒監控相較於白盒監控最大的不同在於黑盒監控是以故障為導向當故障發生時,黑盒監控能快速發現故障,而白盒監控則側重於主動發現或者預測潛在的問題。一個完善的監控標的是要能夠從白盒的角度發現潛在問題,能夠在黑盒的角度快速發現已經發生的問題。

這裡類比敏捷中著名的敏捷測試金字塔,對於完整的監控而言,我們需要大量的白盒監控,用於監控服務的內部執行狀態,從而可以支援有效的故障分析。 同時也需要部分的黑盒監控,用於檢測主要服務是否發生故障。
Blackbox Exporter是Prometheus社群提供的官方黑盒監控解決方案,其允許使用者透過:HTTP、HTTPS、DNS、TCP以及ICMP的方式對網路進行探測。使用者可以直接使用go get命令獲取Blackbox Exporter原始碼並生成本地可執行檔案。
Blackbox Exporter執行時,需要指定探針配置檔案,例如blackbox.yml:
modules:
http_2xx:
prober: http
http:
method: GET
http_post_2xx:
prober: http
http:
method: POST
啟動blackbox_exporter即可啟動一個探針服務:
blackbox_exporter --config.file=/etc/prometheus/blackbox.yml
啟動後,透過訪問http://127.0.0.1:9115/probe?module=http_2xx⌖=baidu.com可以獲得blackbox對baidu.com站點探測的結果。
probe_http_duration_seconds{phase="connect"} 0.055551141
probe_http_duration_seconds{phase="processing"} 0.049736019
probe_http_duration_seconds{phase="resolve"} 0.011633673
probe_http_duration_seconds{phase="tls"} 0
probe_http_duration_seconds{phase="transfer"} 3.8919e-05
probe_http_redirects 0
probe_http_ssl 0
probe_http_status_code 200
probe_http_version 1.1
probe_ip_protocol 4
probe_success 1
在Prometheus中可以透過新增響應的監控採集任務,即可獲取對相應站點的探測結構樣本資料:
- job_name: 'blackbox'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets:
- http:
- https:
- http:
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 127.0.0.1:9115
到目前為止,我們瞭解了Prometheus的基礎架構和主要工作機制,如下所示:
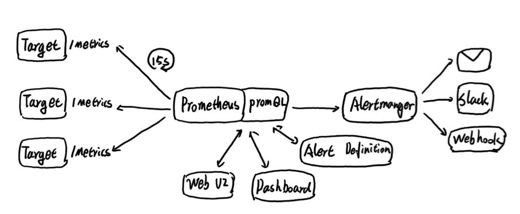
Prometheus週期性的從Target中獲取監控資料並儲存到本地的time-series中,並且透過PromQL對外暴露資料查詢介面。 內部週期性的檢查告警規則檔案,產生告警並有Alertmanager對告警進行後續處理。
那麼問題來了,這裡Prometheus是單點,Alertmanager也是單點。 這樣的結構能否支援大規模的監控量?
對於Prometheus而言,要想完全理解其高可用部署樣式,首先我們需要理解Prometheus的資料儲存機制。
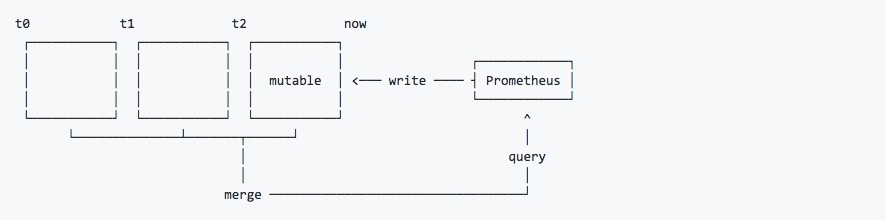
如上所示,Prometheus 2.x採用自定義的儲存格式將樣本資料儲存在本地磁碟當中。按照兩個小時為一個時間視窗,將兩小時內產生的資料儲存在一個塊(Block)中,每一個塊中包含該時間視窗內的所有樣本資料(chunks),元資料檔案(meta.json)以及索引檔案(index)。
當前時間視窗內正在收集的樣本資料,Prometheus則會直接將資料儲存在記憶體當中。為了確保此期間如果Prometheus發生崩潰或者重啟時能夠恢復資料,Prometheus啟動時會從寫入日誌(WAL)進行重播,從而恢復資料。此期間如果透過API刪除時間序列,刪除記錄也會儲存在單獨的邏輯檔案當中(tombstone)。

透過時間視窗的形式儲存所有的樣本資料,可以明顯提高Prometheus的查詢效率,當查詢一段時間範圍內的所有樣本資料時,只需要簡單的從落在該範圍內的塊中查詢資料即可。而對於歷史資料的刪除,也變得非常簡單,只要刪除相應塊所在的目錄即可。
對於單節點的Prometheus而言,這種基於本地檔案系統的儲存方式能夠讓其支援數以百萬的監控指標,每秒處理數十萬的資料點。為了保持自身管理和部署的簡單性,Prometheus放棄了管理HA的複雜度。
因此首先,對於這種儲存方式而言,我們需要明確的幾點:
-
Prometheus本身不適用於持久化儲存長期的歷史資料,預設情況下Prometheus只保留15天的資料。
-
本地儲存也意味著Prometheus自身無法進行有效的彈性伸縮。
而當監控規模變得巨大的時候,對於單臺Prometheus而言,其主要挑戰包括以下幾點:
-
服務的可用性,如何確保Prometheus不會發生單點故障;
-
監控規模變大的意味著,Prometheus的採集Job的數量也會變大(寫)操作會變得非常消耗資源;
-
同時也意味著大量的資料儲存的需求。
由於Prometheus的Pull機制的設計,為了確保Prometheus服務的可用性,使用者只需要部署多套Prometheus Server實體,並且採集相同的Exporter標的即可。

基本的HA樣式只能確保Prometheus服務的可用性問題,但是不解決Prometheus Server之間的資料一致性問題以及持久化問題(資料丟失後無法恢復),也無法進行動態的擴充套件。因此這種部署方式適合監控規模不大,Promthues Server也不會頻繁發生遷移的情況,並且只需要儲存短週期監控資料的場景。
在基本HA樣式的基礎上透過新增Remote Storage儲存支援,將監控資料儲存在第三方儲存服務上。

當Prometheus在獲取監控樣本並儲存到本地的同時,會將監控資料傳送到Remote Storage Adaptor,由Adaptor完成對第三方儲存的格式轉換以及資料持久化。
當Prometheus查詢資料的時候,也會從Remote Storage Adaptor獲取資料,合併本地資料後進行資料查詢。
在解決了Prometheus服務可用性的基礎上,同時確保了資料的持久化,當Prometheus Server發生宕機或者資料丟失的情況下,可以快速的恢復。 同時Prometheus Server可能很好的進行遷移。因此,該方案適用於使用者監控規模不大,但是希望能夠將監控資料持久化,同時能夠確保Prometheus Server的可遷移性的場景。
當單臺Prometheus Server無法處理大量的採集任務時,使用者可以考慮基於Prometheus聯邦叢集的方式將監控採集任務劃分到不同的Prometheus實體當中即在任務級別功能分割槽。

這種場景下Prometheus的效能瓶頸主要在於大量的採集任務,因此使用者需要利用Prometheus聯邦叢集的特性,將不同型別的採集任務劃分到不同的Prometheus子服務中,從而實現功能分割槽。例如一個Prometheus Server負責採集基礎設施相關的監控指標,另外一個Prometheus Server負責採集應用監控指標。再有上層Prometheus Server實現對資料的匯聚。
這種樣式也適合與多資料中心的情況,當Prometheus Server無法直接與資料中心中的Exporter進行通訊時,在每一個資料中部署一個單獨的Prometheus Server負責當前資料中心的採集任務是一個不錯的方式。這樣可以避免使用者進行大量的網路配置,只需要確保主Prometheus Server實體能夠與當前資料中心的Prometheus Server通訊即可。 中心Prometheus Server負責實現對多資料中心資料的聚合。
上面的部分,根據不同的場景演示了3種不同的高可用部署方案。當然對於Prometheus部署方案需要使用者根據監控規模以及自身的需求進行動態調整,下表展示了Prometheus和高可用有關3個選項各自解決的問題,使用者可以根據自己的需求靈活選擇。
| 選項/需求 |
服務可用性 |
資料持久化 |
水平擴充套件 |
| 主備HA |
√ |
× |
× |
| 遠端儲存 |
× |
√ |
× |
| 聯邦叢集 |
× |
× |
√ |
對於Alertmanager而言,Alertmanager叢集之間使用Gossip協議相互傳遞狀態,因此對於Prometheus而言,只需要關聯多個Alertmanager實體即可,關於Alertmanager叢集的詳細詳細可以參考:https://github.com/yunlzheng/prometheus-book/blob/master/ha/alertmanager-high-availability.md

對於諸如Kubernetes這類容器或者雲環境,對於Prometheus而言,需要解決的一個重要問題就是如何動態的發現部署在Kubernetes環境下的需要監控的所有標的。
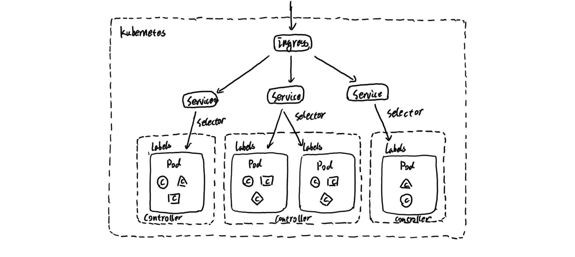
對於Kubernetes而言,如上圖所示,我們可以把當中所有的資源分為幾類:
-
基礎設施層(Node):叢集節點,為整個叢集和應用提供執行時資源
-
容器基礎設施(Container):為應用提供執行時環境
-
使用者應用(Pod):Pod中會包含一組容器,它們一起工作,並且對外提供一個(或者一組)功能
-
內部服務負載均衡(Service):在叢集內,透過Service在叢集暴露應用功能,叢集內應用和應用之間訪問時提供內部的負載均衡
-
外部訪問入口(Ingress):透過Ingress提供叢集外的訪問入口,從而可以使外部客戶端能夠訪問到部署在Kubernetes叢集內的服務
因此,在不考慮Kubernetes自身元件的情況下,如果要構建一個完整的監控體系,我們應該考慮,以下5個方面:
-
叢集節點狀態監控:從叢集中各節點的kubelet服務獲取節點的基本執行狀態;
-
叢集節點資源用量監控:透過Daemonset的形式在叢集中各個節點部署Node Exporter採集節點的資源使用情況;
-
節點中執行的容器監控:透過各個節點中kubelet內建的cAdvisor中獲取個節點中所有容器的執行狀態和資源使用情況;
-
從黑盒監控的角度在叢集中部署Blackbox Exporter探針服務,檢測Service和Ingress的可用性;
-
如果在叢集中部署的應用程式本身內建了對Prometheus的監控支援,那麼我們還應該找到相應的Pod實體,並從該Pod實體中獲取其內部執行狀態的監控指標。
而對於Prometheus這一類基於Pull樣式的監控系統,顯然也無法繼續使用的static_configs的方式靜態的定義監控標的。而對於Prometheus而言其解決方案就是引入一個中間的代理人(服務註冊中心),這個代理人掌握著當前所有監控標的的訪問資訊,Prometheus只需要向這個代理人詢問有哪些監控標的控即可, 這種樣式被稱為服務發現。

Prometheus提供了對Kubernetes的完整支援,透過與Kubernetes的API進行互動,Prometheus可以自動的發現Kubernetes中所有的Node、Service、Pod、Endpoints以及Ingress資源的相關資訊。
透過服務發現找到所有的監控標的後,並透過Prometheus的Relabling機制對這些資源進行過濾,metrics地址替換等操作,從而實現對各類資源的全自動化監控。
例如,透過以下流程任務配置,可以自動從叢集節點的kubelet服務中內建的cAdvisor中獲取容器的監控資料:
- job_name: 'kubernetes-cadvisor'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
由或者是透過叢集中部署的blackbox exporter對服務進行網路探測:
- job_name: 'kubernetes-services'
metrics_path: /probe
params:
module: [http_2xx]
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter.example.com:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
target_label: kubernetes_name
由於線上分享的形式無法事無巨細的分享關於Prometheus的所有內容,但是希望大家能夠透過今天的分享能夠對Prometheus有更好的理解。
這裡我也將關於Prometheus的相關實踐透過電子書的形式進行了整理:https://github.com/yunlzheng/prometheus-book,希望能對大家學習和使用Prometheus起到一定的幫助作用,當然關於Prometheus的相關問題,也可以透過Github Issue來相互交流。
Q:Prometheus的資料能否自動同步到InfluxDB中?
A:可以,透過remote_write可以實現,可以參考:https://github.com/prometheus/prometheus/tree/master/documentation/examples/remote_storage/remote_storage_adapter。Prometheus透過將採集到的資料傳送到Adaptor,再由Adaptor完成對資料格式的轉換儲存到InfluxDB即可。
Q:Prometheus一個Server最多能執行多少個Job?
A:這個沒有做具體的試驗,不過需要註意的是Job任務量(寫操作),會直接影響Prometheus的效能,最好使用federation實現讀寫分離。
Q:請問告警由Grafana實現比較好,還是Alertmanager,常用的metric串列有沒有彙總的清單連結分享下,歷史資料預設保留時間如何設定?
A:Grafana自身是支援多資料源,Promethues只是其中之一。 如果只使用Promthues那用Alertmanager就好了,裡面實現了很多告警去重和靜默的機制,不然收到郵件轟炸也不太好。 如果需要基於Grafana中用到的多種資料源做告警的話,那就用Grafana。
Q:Prometheus監控資料推薦存哪裡是InfluxDB,或者ES裡面,InfluxDB單節點免費,多節的似乎收費的?
A:預設情況下,直接是儲存到本地的。如果要把資料持久化到第三方儲存只要實現remote_write介面就可以。理論上可以對接任意的第三方儲存。 InfluxDB只是官方提供的一個示例之一。
Q:請問“再有上層Prometheus Server實現對資料的匯聚。”是表示該Prometheus會對下層Prometheus進行資料收集嗎?使用什麼介面?
A:請參考Prometheus Fedreation(https://prometheus.io/docs/prometheus/latest/federation/),這裡主要是指由一部分Prometheus實體負責採集任務,然後Global的Prometheus彙集資料,並對外提供查詢介面。 減少Global Prometheus的壓力。
Q:兩臺Prometheus server 可否用Keepalived?
A:直接負載均衡就可以了,對於Prometheus而言,實體之間本身並沒有任何的直接關係。
Q:用Prometheus監控業務的API介面,有什麼好的方法嗎,能監控資料庫的慢查詢嗎?
A:在系統中整合client_library,直接在程式碼中埋點。可以參考這個例子:https://github.com/yunlzheng/prometheus-book/blob/master/exporter/custom_app_support_prometheus.md。

本次培訓內容包括:Docker基礎、容器技術、Docker映象、資料共享與持久化、Docker三駕馬車、Docker實踐、Kubernetes基礎、Pod基礎與進階、常用物件操作、服務發現、Helm、Kubernetes核心元件原理分析、Kubernetes服務質量保證、排程詳解與應用場景、網路、基於Kubernetes的CI/CD、基於Kubernetes的配置管理等,點選瞭解具體培訓內容。
長按二維碼向我轉賬
![]()
受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。

