你是否希望照片上的偶像、男神女神,甚至動畫人物對著你說出你想聽的那句話?又或是希望偽造明星說他們沒說過話的影片?
作者丨Lovely Zeng
學校丨CUHK
研究方向丨Detection
香港中文大學 MMLab 提出透過解離的聽覺和視覺資訊進行說話人臉影片的生成,使得生成高解析度且逼真的說話影片成為可能,而系統的輸入可以僅僅是一張照片和一段任何人說話的語音,無需先對人臉形狀建模。
論文的效果如下:

甚至對於動畫人物和動物也能取得很好的效果:

論文已經被 AAAI 2019 收錄為 Oral Presentation,接下來就將對論文進行詳細的講解,在此將著重於本文的背景和技術,細節部分詳見論文,本文程式碼已經開源,長按識別下方二維碼即可檢視論文和原始碼。


背景介紹
多數研究基於音訊的說話人臉影片生成問題都是基於圖形學的方法,比如在論文 [1] 中,超逼真的奧巴馬說話影片已經被成功的合成出來。但是這類方法通常需要對特定的標的物件的大量影片進行訓練和建模。
而最近基於深度學習的方法 [2] 和 [3] 使用了 Image-to-Image 的方式,透過單張影象生成整個人臉說話的影片。這種方式已經足以得到很好的與提供的語音匹配的唇形,但是生成影象的質量卻大打折扣,生成的結果不但解析度不高,甚至可能出現人物的面部特徵丟失或是出現色差等問題。
問題出現的原因則是因為,由於人臉的身份特徵和唇形的語意特徵沒有完全解離,所以當身份特徵被儲存完好,也就是希望輸出高質量影象的時候,其原來的唇形特徵也會被儲存下來,難以受音訊資訊影響。
本文旨在生成與音訊完美契合,同時對人臉的細節特徵儲存完好的高質量的說話影片。因為在方法中同時編碼了影片和音訊資訊,從而使一個單獨的模型獲得了既可以使用音訊又可以使用影片進行進行說話人影片生成的特性。
文章解決的問題如圖 1 所示:
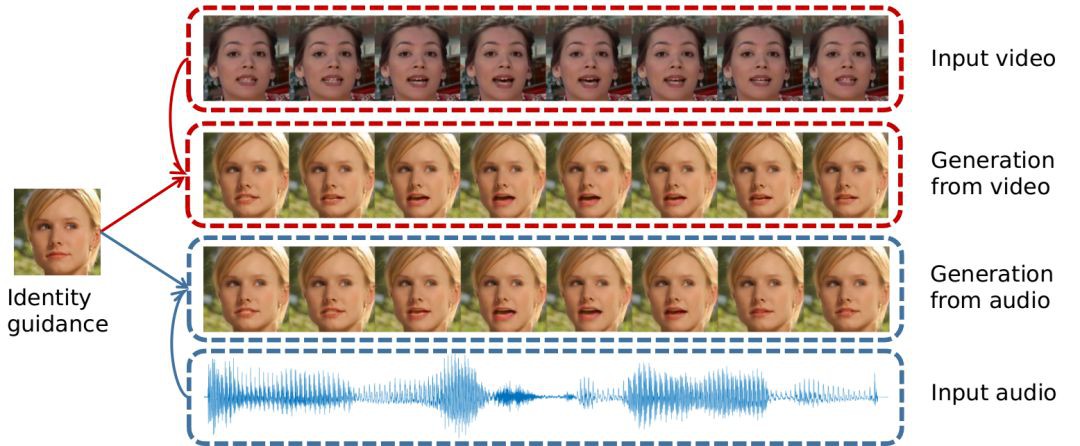
▲ 圖1
解決方案
在本文中,解決問題的思路是將一段說話的影片對映到兩種互補的人臉資訊表示空間上,一種是人臉身份特徵的表示空間(PID),另一種就是說話內容的表示空間(WID)。
如果能有方法將這兩種表示所在的空間的資訊解離開,則保持身份特徵資訊不變,使說話內容空間的資訊根據音訊流動,再將兩個空間的資訊組合就可以達到任意 PID 說任意 WID 的標的。大體思路如下圖所示:
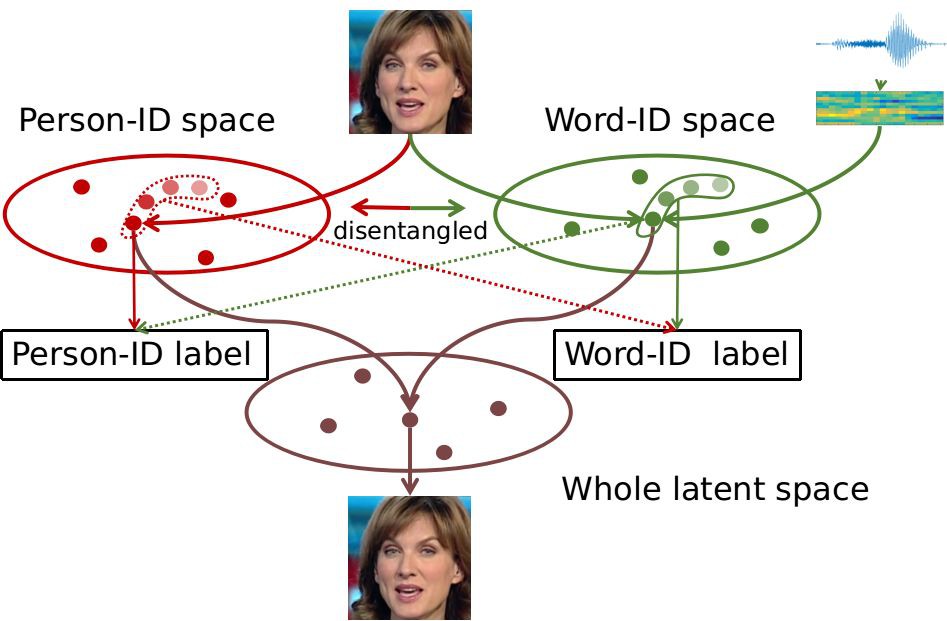
其核心思想在於使用聯合視覺的語音識別(Audio-Visual Speech Recognition)(帶音訊的唇語識別)任務進行空間的編碼和解離。包含說話人臉影片,音訊和所說詞語標簽的唇語識別資料集天然的標的,由此文章提出了一種“協同與對抗(associate-and-adversarial)”的訓練方式。
透過使用音訊和視覺資訊同時訓練語音識別任務,有關說話內容的特徵空間就可以被找到。而在此空間中,一組對應的影片和音訊因為表達的是同樣的資訊,所以理應對映到同一個位置。
因此文章透過協同訓練找到一個聽視覺資訊融合的表示空間(joint audio-visual representation),也就是上圖中的 Word-ID space。而這樣的協同空間中無論是視覺資訊還是音訊資訊對映的特徵,都可以拿來進行人臉和重構,由此又巧妙地達到了使用一個模型統一使用影片或者音訊生成說話影片。
有了詞語的標簽之後,更有趣的是可以透過詞語標簽對編碼人臉身份特徵的網路進行對抗訓練(adversarial training),將語言資訊也就是唇形資訊從中解離出來。同時,找到對映人臉的空間因為有大量標有人身份標簽的資料集的存在,本身是一件很簡單的事情。
透過使用額外的帶有身份資訊的資料進行訓練既可以透過分類任務找到對映人臉的空間,又可以透過對抗訓練將人臉資訊從語言空間解離出來。
簡單總結一下文章的貢獻:
1. 首先透過音訊和影片協同訓練唇語識別,將兩種資訊向語言空間融合對映,協同訓練的結果顯示甚至相比基線可以提升唇語識別的結果;
2. 因為透過了使用識別性的任務進行對映,充分利用可判別性,使用對抗訓練的方式進行了人臉特徵和語言資訊的解離;
3. 透過聯合訓練上述任務,任意一張照片都可以透過一段給定的音訊或者影片,生成高質量的說話影片。
技術細節
方法的整個流程圖如下,文章的整個方法被命名為“解離的音-影片系統”,Disentangled Audio-Visual System (DAVS):
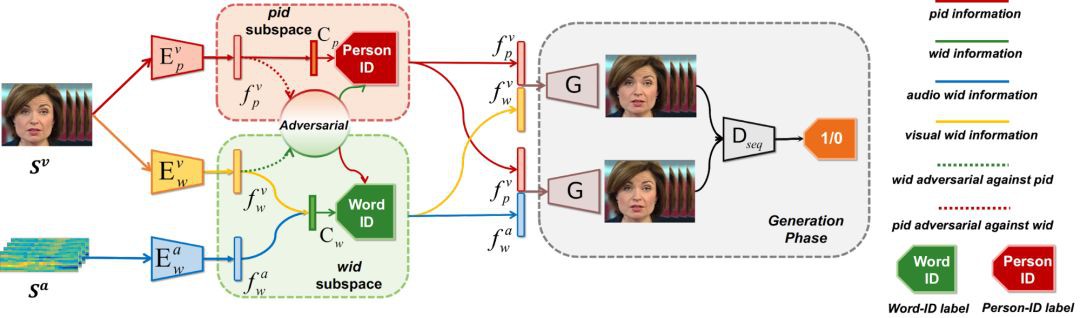
本文使用了單詞級別的唇語識別資料集 LRW。在此資料集中每段定長的影片擁有其所含的主要單詞的 label,所以對映的說話內容空間,被命名為 Word-ID(wid)空間(詞空間),對應於人臉的 Peron-ID (pid) 空間(身份空間)。
整個系統包含影片對詞空間的編碼網路![]() ,音訊對詞空間的編碼網路
,音訊對詞空間的編碼網路![]() ,和影片對身份空間的編碼網路
,和影片對身份空間的編碼網路![]() ;透過網路,人臉空間被劃分成 wid 和 pid 兩個互斥的空間,並使用對抗訓練的方式解離開。同時 wid 空間是音訊和影片協同對映的聯合空間,透過同步兩個空間的資訊,要求對應的音訊和影片對映到空間的同一位置。
;透過網路,人臉空間被劃分成 wid 和 pid 兩個互斥的空間,並使用對抗訓練的方式解離開。同時 wid 空間是音訊和影片協同對映的聯合空間,透過同步兩個空間的資訊,要求對應的音訊和影片對映到空間的同一位置。
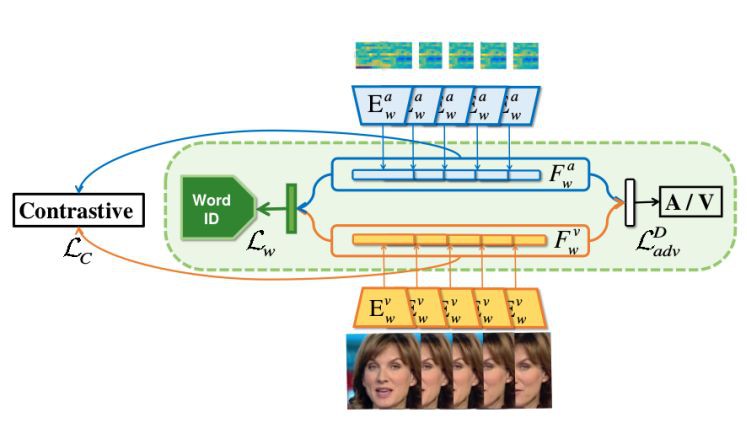
音訊影片聯合空間對映
聯合空間的對映透過三個監督聯合完成,這三個監督分別是:共享影片和音訊對映到詞標簽的分類器;通常用於排序的 contrastive 損失函式;和一個簡單的用於混淆兩個空間的對抗訓練器。
共享分類器這一方法,本質在於讓資料向類中心靠攏,可以稱之為“中心同步”[4]。而排序 Contrastive loss 用於音訊和影片同步最早源於 VGG 組提出的 SyncNet [5]。
利用這一體系進行聯合空間對映,所以聯合空間對映模組也適用於將音-影片同步這一任務。而本身使用唇語識別這一任務做監督又意味著可以同時將唇語識別這一任何融入其中。
對抗訓練空間解離
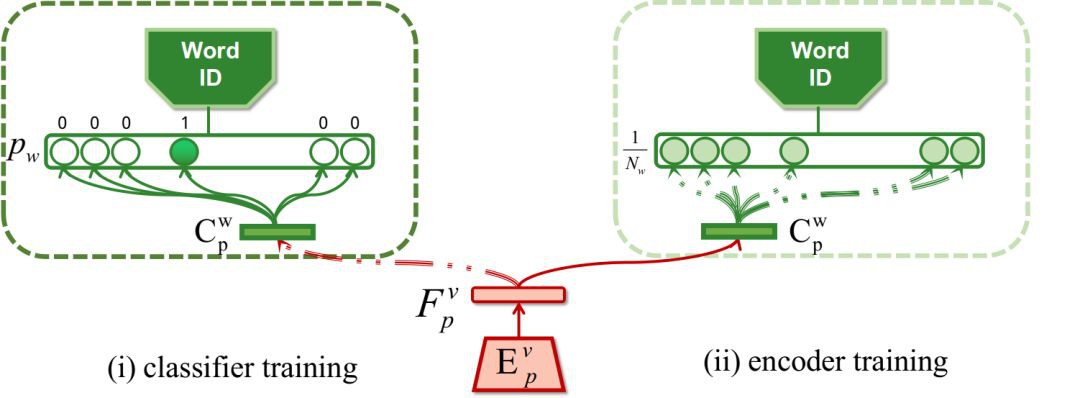
為了將身份空間和詞空間解離,文章首先依託唇語識別資料集的標簽,對身份空間的編碼器進行語言資訊的解離。在保持身份編碼器![]() 權重不變的情況下,透過訓練一個額外的分類器
權重不變的情況下,透過訓練一個額外的分類器![]() ,將
,將![]() 編碼的影片特徵
編碼的影片特徵![]() ,對映到其對用的詞標簽上。這一步驟的意義在於盡可能的將已編碼的身份特徵中的語言資訊提取出來。然後第二步保持分類器的權重不變,訓練編碼器
,對映到其對用的詞標簽上。這一步驟的意義在於盡可能的將已編碼的身份特徵中的語言資訊提取出來。然後第二步保持分類器的權重不變,訓練編碼器![]() ,此時詞標簽則取成總類別數的平均值。由此我們期望對映的特徵向量中含有的詞資訊不足以讓分類器
,此時詞標簽則取成總類別數的平均值。由此我們期望對映的特徵向量中含有的詞資訊不足以讓分類器![]() 成功分類。
成功分類。
對於詞編碼器![]() ,文章使用額外的人臉識別資料 MS-Celeb-1M [6],使用同樣的方式對稱的提純對映的詞空間資訊,完成身份空間和詞空間的解離。
,文章使用額外的人臉識別資料 MS-Celeb-1M [6],使用同樣的方式對稱的提純對映的詞空間資訊,完成身份空間和詞空間的解離。
實驗結果
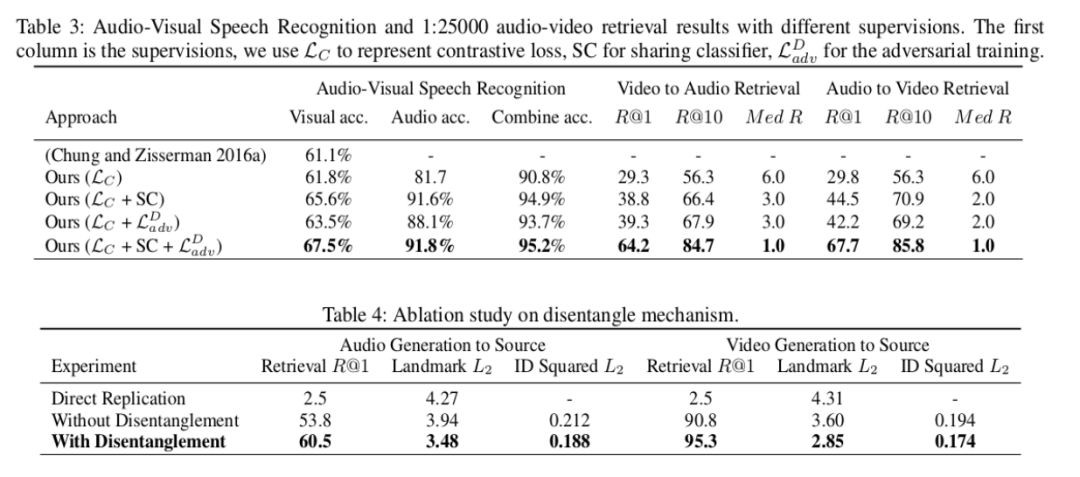
文章中進行了一些數值的對比實驗證明其提出的每一個模組的有效性,但對於此任務,最重要的生成的效果。Gif 結果附在了本文開頭,而長影片結果請見主頁:
https://liuziwei7.github.io/projects/TalkingFace
參考文獻
[1] Suwajanakorn, S., Seitz, S. M., & Kemelmacher-Shlizerman, I. (2017). Synthesizing obama: learning lip sync from audio. ACM Transactions on Graphics (TOG), 36(4), 95.
[2] Chung, J. S., Jamaludin, A., & Zisserman, A. (2017). You said that?. BMVC 2017.
[3] Chen, L., Li, Z., Maddox, R. K., Duan, Z., & Xu, C. (2018). Lip Movements Generation at a Glance. ECCV 2018.
[4] Liu, Y., Song, G., Shao, J., Jin, X., & Wang, X. (2018, September). Transductive Centroid Projection for Semi-supervised Large-Scale Recognition. ECCV 2018.
[5] Chung, J. S., & Zisserman, A. (2016, November). Out of time: automated lip sync in the wild. In ACCV workshop 2016.
[6] Guo, Y., Zhang, L., Hu, Y., He, X., & Gao, J. (2016, October). Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. ECCV 2016.