
筆者邀請您,先思考:
1 信用評分卡如何做資料準備?
2 您怎麼理解探索性資料分析?如何做探索性資料分析?
“垃圾進出垃圾”是電腦科學中常用的公理,也是對專案成功的威脅 – 輸出質量在很大程度上取決於輸入的質量。
因此,**資料準備是任何資料挖掘專案的關鍵方面,包括信用評分卡的開發。 **這是CRISP-DM週期中最具挑戰性和耗時的階段。 專案總時間中至少70%,有時多於90%專門用於此項活動。 它涉及資料收集,結合多個資料源,聚合,轉換,資料清理,“切片和切塊”,並檢視資料的廣度和深度,以獲得清晰的理解並將資料量轉換為資料質量,從而使我們 可以自信地準備下一階段 – 模型建設。
本系列的前一篇文章中,信用評分卡建模方法論討論了模型設計的重要性,並確定了其主要組成部分,包括分析單元,總體框架,樣本量,標準變數,建模視窗,資料源和資料收集方法。 仔細考慮每個元件對於成功的資料準備至關重要。 這個階段的最終產品是一個挖掘檢視,包括正確的分析層級,總體建模,自變數和因變數。

表1.模型設計元件
資料源
“越多越好” – 作為資料理解步驟的一部分,任何外部和內部資料源都應提供數量和質量。 所使用的資料必須是相關的,準確的,及時的,一致的和完整的,同時具有足夠多樣的數量以提供有用的分析結果。 對於內部資料量有限的申請評分卡,外部資料普遍存在。 相比之下,行為評分卡使用更多的內部資料,並且在預測能力方面通常較高。 以下概述了客戶驗證,欺詐檢測或信用授權所需的常見資料源。
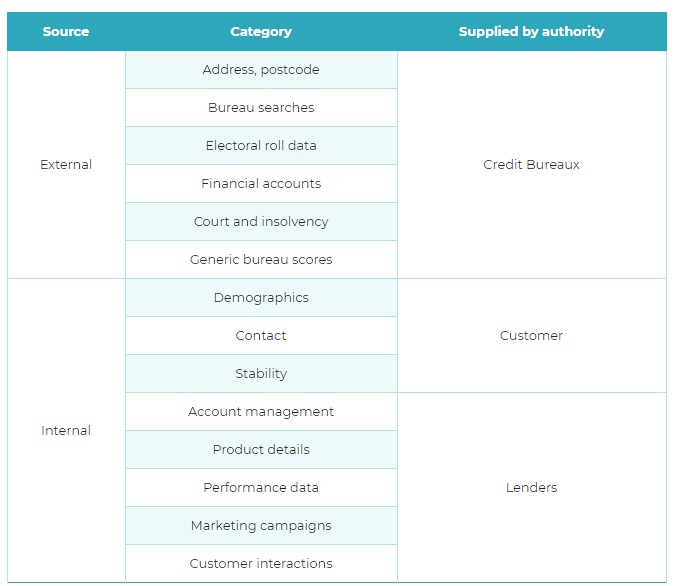
表2.資料源多樣性
過程
資料準備過程從資料收集開始,通常稱為ETL過程(Extract-Transform-Load)。 資料整合使用資料合併和串聯組合不同的資料源。 通常,它需要使用許多完整性規則(如物體,參照和域完整性)來處理關係表。 使用一對一,一對多或多對多的關係,資料被彙總到所需的分析水平,從而生成獨特的客戶簽名。

圖1.資料準備過程
資料探索和資料清理是相互重覆的步驟。 資料探索包括單變數和雙變數分析,範圍從單變數統計和頻率分佈到相關性,交叉串列和特徵分析。
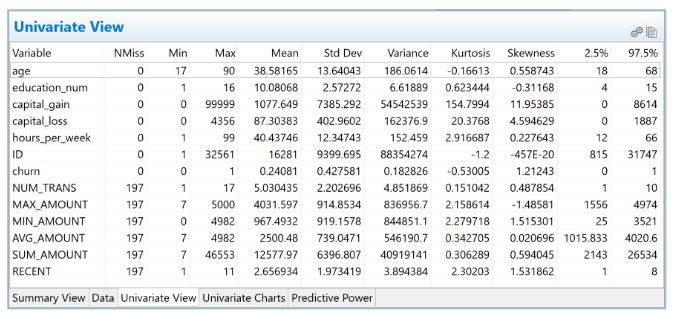
圖2. EDA(單變數檢視)

圖3. EDA(特徵分析)
在探索性資料分析(EDA)之後,對資料進行處理以提高質量。 ** 資料清理**需要良好的業務和資料理解,才能以正確的方式解讀資料。 這是一個反覆的過程,旨在消除不規則行為,並酌情替換,修改或刪除這些不規則行為。 *資料不乾凈的兩個主要問題是缺失值和異常值; 這兩者都會嚴重影響模型的準確性,因此必須細心幹預。*
在決定如何處理缺失值之前,我們需要瞭解缺失資料的原因並理解缺失資料的分佈情況,以便我們可以將其分類為:
隨機完整性缺失(MCAR);
隨機缺失(MAR)或;
非隨機性缺失(MNAR)。
缺少資料處理通常假定MCAR和MAR,而NMAR更難以處理。 下麵的串列提供了按複雜程度排序的常見處理。
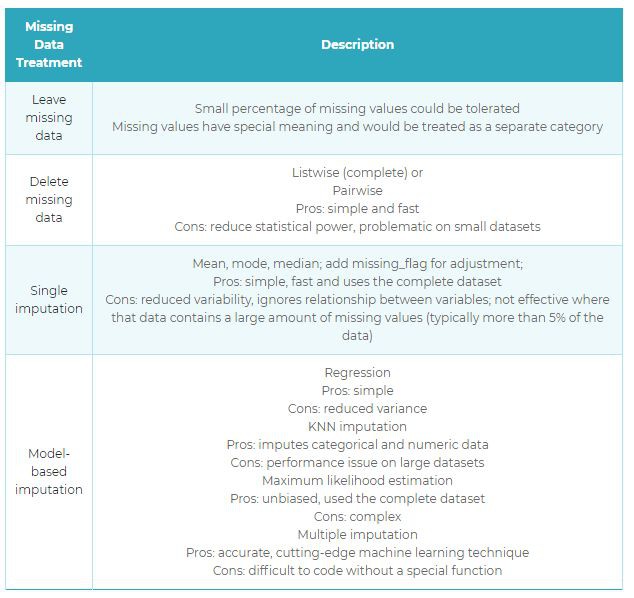
表3.缺失資料處理
在我們的資料中,異常值是另一種“野獸”,因為它們的存在會違揹我們開發模型的統計假設。一旦確定,在應用任何處理之前理解異常值的原因很重要。例如,異常值可能是欺詐檢測中有價值的資訊來源;因此,用平均值或中值代替它們是一個不好的主意。
應該使用單變數和多變數分析來分析異常值。對於檢測,我們可以使用視覺方法,如直方圖,箱形圖或散點圖和統計方法,如平均值和標準偏差,透過檢查遠距離聚類,小決策樹葉節點,馬氏距離,Cook’s D或Grubbs測試。對於什麼應該被視為異常值的判斷並不像識別缺失值那麼簡單。決定應基於特定標準,例如:任何超出±3標準偏差或±1.5IQR或第5-95百分位範圍的值將被標記為異常值。
離群值可用與缺失值類似的方式處理。還可以使用其他轉換,包括:裝箱,重量分配,轉換為缺失值,對數變換以消除極值或Winsorization的影響。
如上所述,資料清理可能涉及實現不同的統計和機器學習技術。儘管這些轉換可能會建立更優質的評分卡模型,但實際操作必須考慮到,因為複雜的資料操作可能難以實施,成本高昂並且會降低模型處理效能。
一旦資料清洗完畢,我們就可以做出更有創意的部分 – 資料轉換。資料轉換或特徵工程是建立附加(假設)模型變數,並對其進行重要性測試。最常見的轉換包括分箱和最佳化分箱,標準化,縮放,熱編碼,互動項,數學轉換(從非線性轉換為線性關係,從傾斜資料轉換為正態分佈資料)以及使用聚類和因子分析進行資料縮減。
除了關於如何解決這一任務的一些一般性建議之外,資料科學家有責任建議將客戶資料簽名轉化為強大資訊人造物的最佳方法 – 挖掘檢視。這可能是資料科學家角色中最具創造性和最具挑戰性的方面,因為除了統計和分析技能之外,它還需要牢固掌握業務理解。通常,建立好模型的關鍵不在於具體建模技術的力量,而在於衍生變數的廣度和深度,這些變數代表了對被審查現象更高水平的知識。
接下來的是特徵創造的藝術……
系列之前:信用評分:第2部分 – 信用評分卡建模方法
系列之後:信用評分:第4部分 – 變數選擇
作者:
Natasha Mashanovich,
Senior Data Scientist at World Programming,
UK
原文連結:https://www.worldprogramming.com/blog/credit_scoring_pt3
版權宣告:作者保留權利,嚴禁修改,轉載請註明原文連結。
資料人網是資料人學習、交流和分享的平臺http://shujuren.org 。專註於從資料中學習到有用知識。
平臺的理念:人人投稿,知識共享;人人分析,洞見驅動;智慧聚合,普惠人人。
您在資料人網平臺,可以1)學習資料知識;2)建立資料部落格;3)認識資料朋友;4)尋找資料工作;5)找到其它與資料相關的乾貨。
我們努力堅持做原創,聚合和分享優質的省時的資料知識!
我們都是資料人,資料是有價值的,堅定不移地實現從資料到商業價值的轉換!
加入資料人圈子或者商務合作,請新增筆者微信。

點選閱讀原文,進入資料人網,獲取資料知識。
公眾號推薦:
鏈達君,專註於分享區塊鏈內容。

腳印英語,專註於分享英語口語內容。

