
筆者邀請您,先思考:
1 信用評分卡如何做分割?
2 信用評分卡如何解決拒絕推斷?
“細分和拒絕推斷,還是保持簡單? – 這是個問題!” 本文探討了計分卡開發過程中經常需要解決的另外兩個方面:分割和拒絕推理(RI)。
分割
多少個評分卡? 標準是什麼? 最佳做法是什麼? – 是我們試圖在評分卡開發早期回答的常見問題,從識別和證明評分卡數量的過程開始 – 稱為分割。

圖1.評分卡分割
初步分割預評估是在業務見解分析期間進行的。 在這個階段,企業應該被告知任何可能具有不同特徵的異質人口群體,這些群體不可能作為一個單獨的群體來對待,以便早日做出有關接受多個評分卡的商業決策。
分割的業務驅動因素是:(1)市場營銷,如產品供應或新市場;(2)跨不同客戶群體的不同對待,例如基於人口統計;(3)資料可用性,這意味著不同的資料可能透過不同的營銷渠道提供,或者某些客戶群可能沒有可用的信用記錄。
分割的統計驅動因素假設每個細分市場中都有足夠數量的觀察值,包括“好”和“壞”賬戶,並且每個細分市場都包含互動效應,其中預測樣式在細分市場各不相同。
通常,分割過程包括以下步驟:
-
使用有監督或無監督分割來識別簡單的分割樣式。
-
對於有監督的分割,決策樹通常用於識別潛在的細分並捕捉互動效應。或者,來自整體模型的殘差可用於檢測資料中的互動。
-
可以使用非監督式分割(如聚類)建立分割,但此方法不一定捕獲互動效果。
-
為每個細分確定一組候選預測變數。
-
根據每個細分建立獨立的模型。
-
測試:
-
如果分割模型具有不同的預測樣式,不能確定跨越分割的新預測特徵,則表明資料科學家應尋找更好的分割或建立單一模型。
-
如果分割模型具有相似的預測樣式,但在跨越分割時具有顯著不同的幅度或相反效果。
-
如果分割模型與建立在整個人口中的單一模型相比,在預測能力方面產生了卓越的提升。
細分是一個迭代過程,需要不斷的判斷來確定是使用單個還是多個細分。從實踐者的經驗來看,細分很少會導致顯著的提升,並且應該盡一切努力來製作單一的記分卡。用於避免分割的常用方法包括在邏輯回歸中新增其他變數以捕捉互動效應或者識別每個分段最具預測性的變數並將它們組合成單個模型。
獨立的記分卡通常是獨立建造的。但是,如果模型因素的可靠性是一個問題,父母/孩子模型可能會提供一種替代方法。在這種方法中,我們根據共同特徵開發了父母模型,並將模型輸出用作其子模型的預測變數,以補充兒童群體的獨特特徵。
與單個評分卡相比,多個評分卡的主要標的是提高風險評估的質量。如果分段評分卡為業務提供的顯著價值能夠超過較高的開發和實施成本,決策管理流程的複雜性,評分卡的額外管理以及更多地使用IT資源,才能使用分段評分卡。
拒絕推斷
如果建模僅基於具有已知效能的可接受總體,則申請評分卡具有自然發生的選擇偏差。然而,由於他們未知的表現,從建模過程中排除了一大批被拒絕的客戶。 為瞭解決選擇偏差問題,申請評分卡模型應該包含兩個人群。 這意味著需要推斷拒絕的未知效能,這是使用拒絕推斷(RI)方法完成的。

圖2.接受和拒絕人群
有無拒絕推斷? – 有兩種思想觀點:那些認為RI是惡性迴圈的人,推斷拒絕者的表現將基於批准但有偏見的人群,從而導致拒絕推斷的可靠性降低; 以及那些主張RI方法論是有價值的方法,它對模型的效能有利。
如果使用RI,在評分卡開發過程中還需要一些額外的步驟:
-
在接受方上構建邏輯回歸模型 – 這是base_logit_model
-
使用拒絕推斷技術推斷拒絕
-
將接受和推斷拒絕合併成一個資料集(complete_population)
-
在complete_population上構建一個新的邏輯回歸模型 – 這是final_logit_model
-
驗證final_logit_model
-
根據final_logit_model建立一個評分卡模型

圖3.使用拒絕推斷開發評分卡
拒絕推斷是一種缺失值處理形式,其結果是“非隨機性缺失”(MNAR),導致接受和拒絕人群之間存在顯著差異。 有兩種廣泛的方法來推斷缺失的表現:分配和增強,每種方法都有不同的技術。 兩種方法中最流行的技術是比例分配,簡單和模糊增強和parcelling。

表1.拒絕推斷技術
比例分配是將拒絕物件隨機劃分為“好”和“差”的賬戶,其“壞”比率比公認的人群高兩至五倍。
簡單增強假定使用base_logit_model對拒絕進行評分,並根據截止值將其分為“好”和“壞”帳戶。截止值被選擇為使得拒絕者的不合格率比接受者中大2至5倍。
模糊增強假定使用base_logit_model對拒絕進行評分。每條記錄都有效地複製,其中包含加權“壞”和加權“好”元件,二者均來自拒絕評分。這些權重,以及所有接受權重等於“1”的權重,將在final_logit_model中使用。建議的策略是拒收率比接受者高兩到五倍。
Parcelling是一種包含簡單增強和比例分配的混合方法。透過將使用base_logit_model生成的拒絕分數分箱成分數帶中來建立parcel。比例分配適用於每個parcel,其“壞”比率是被接受人口的等值分數帶中的“壞”率的兩倍至五倍。

圖4.比例分配
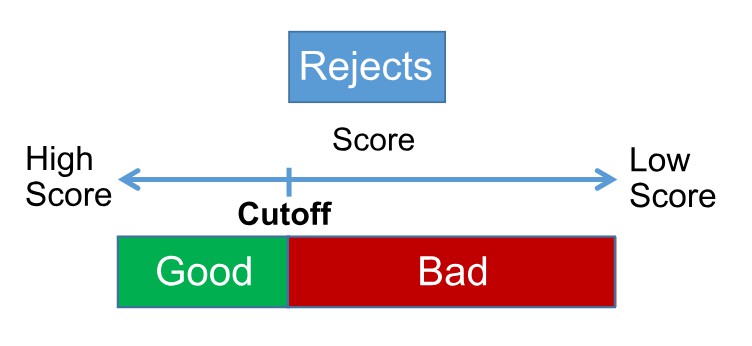
圖5.簡單增強
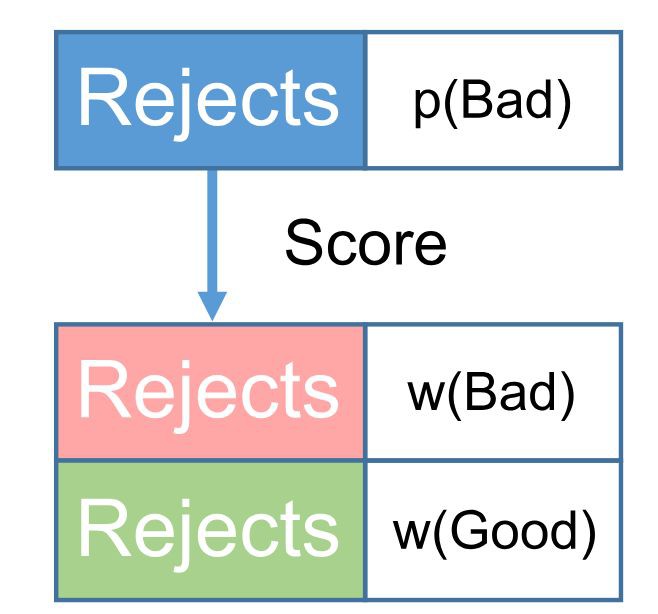
圖6.模糊增強

圖7. Parcelling
系列之前:信用評分:第5部分 – 評分卡開發
系列之後:信用評分:第7部分 – 信用風險模型的進一步考慮
作者:
Natasha Mashanovich,
Senior Data Scientist at World Programming,
UK
原文連結:https://www.worldprogramming.com/blog/credit_scoring_pt6
版權宣告:作者保留權利,嚴禁修改,轉載請註明原文連結。
資料人網是資料人學習、交流和分享的平臺http://shujuren.org 。專註於從資料中學習到有用知識。
平臺的理念:人人投稿,知識共享;人人分析,洞見驅動;智慧聚合,普惠人人。
您在資料人網平臺,可以1)學習資料知識;2)建立資料部落格;3)認識資料朋友;4)尋找資料工作;5)找到其它與資料相關的乾貨。
我們努力堅持做原創,聚合和分享優質的省時的資料知識!
我們都是資料人,資料是有價值的,堅定不移地實現從資料到商業價值的轉換!
加入資料人圈子或者商務合作,請新增筆者微信。

點選閱讀原文,進入資料人網,獲取資料知識。
公眾號推薦:
鏈達君,專註於分享區塊鏈內容。

腳印英語,專註於分享英語口語內容。
