




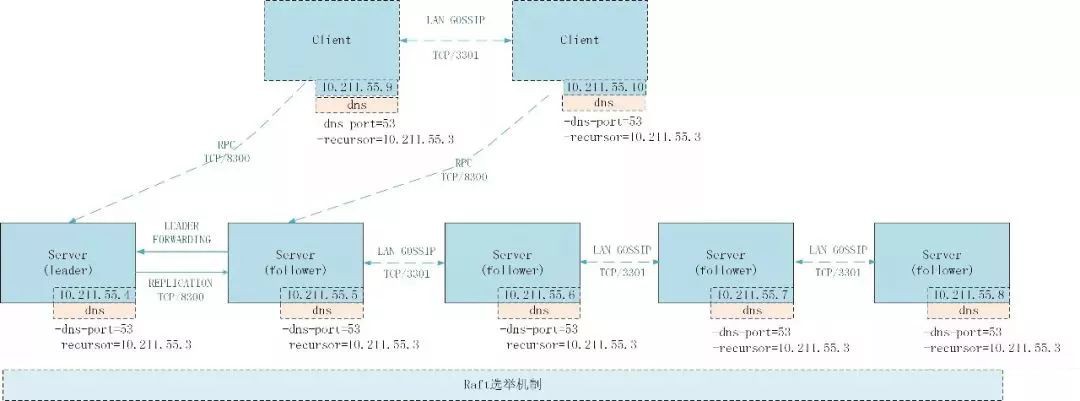
consul agent -server -bootstrap -syslog \-ui \-data-dir=/opt/consul/data \-dns-port=53-recursor=10.211.55.3-config-dir=/opt/consul/conf \-pid-file=/opt/consul/run/consul.pid \-client=10.211.55.4 \-bind=10.211.55.4 \-node=consul-server01 \-disable-host-node-id &


spring:application:name: @project.artifactId@version: @project.version@build: @buildNumber@branch: @scmBranch@cloud:inetutils:ignoredInterfaces:- docker0config:server:health.enabled: falsegit:uri: /opt/repos/configsearchPaths: 'common,{application}'cloneOnStart: truerepos:pay:pattern: pay-*cloneOnStart: trueuri: /opt/repos/example/configsearchPaths: 'common,{application}'finance:pattern: finance-*cloneOnStart: trueuri: /opt/repos/finance/configsearchPaths: 'common,{application}'
