
筆者邀請您,先思考:
1 催收評分解決什麼問題?
2 如何設計和實現催收評分?
編者按:最近在研究催收評分,發現相關資料不多。這篇論文全面地介紹了催收評分和商業應用策略,很有借鑒價值。
摘要:
本研究的標的是在一家專門從事不良貸款組合的巴西公司254,914名客戶的樣本中開發一個催收評分模型,使用Logistic回歸來識別那些更傾向於償還不良貸款的客戶。 此外,本文還提出了商業應用的建議。
關鍵詞:不良貸款,收集評分,Logistic回歸,統計模型
介紹
1994年,在金融穩定後,巴西市場開始利用大規模信貸分析模型,自動評估大量信貸申請。
巴西的金融機構為新客戶已經大量使用信用評分模型,因為1994年中期開始的Plano Real實現了貨幣穩定性,並導致消費者信貸量的高增長率。
除了用於分析新貸款授予的模型(稱為信用評分)之外,還增加了對其他兩個模型的使用:在第一個模型(行為評分模型)中,目的是評估銀行客戶是否是能夠獲得新的貸款;第二個模型(催收評分)評估已經違約的且需要做催收行動的客戶的還款可能性(Sadatrasoul等人2013)。
本研究旨在為不良貸款組合(NPL)建立一個催收評分模型,尋求透過評估每種型別客戶的還款狀況,定義最佳收集策略。此外,我們還將根據分析中確定的客戶畫像提供催收策略。
文獻評論
不良貸款
不良貸款是逾期90天以上的貸款準備金。 金融機構中不良貸款數量的增加導致該公司破產的風險(Makri等人,2014年)。
Toledo(2013)指出,自從90年代中期以來,在Plano Real實現穩定之後,巴西經濟一直在經歷由貸款增加所帶來的增長過程,因此,據幾位作者稱,快速擴張已經 導致貸款質量惡化,導致違約增加(Kauko 2012; Makri等人2014; Barseghyan 2010; Lu等人2007),導致貸款逾期超過90天。 Toledo(2013)指出,在2002年至2012年間,信貸額度從GDP的25%增加到約50%。
催收政策
催收的職責是為公司的現金帶來資金。 該領域的目的是加速催收,使公司最大限度地減少對信貸設施的需求(Gitman 2006)。
催收政策旨在確定尋求收到應收款項的公司採用的各種可能的標準和程式(Assaf Neto和Lima,2011),即公司在到期日收到應收款項的策略。 使用的基本程式是:透過信件,電話,法庭,訪問等(Machado和Barreto,2011)。
根據Hoji(2014),催收政策應與信貸政策一起實施。 信貸授予不能太一以至於隨後在催收中要求嚴格的申請,反之亦然。 如果在授予信貸的行為中已經預期到催收的困難,則信用評分應該更加嚴格。
評分模型
根據Crook等人的說法。 (2007年),評分模型旨在衡量投資組合在其期限內的風險。 最常見的是使用邏輯回歸作為構建模型的工具; 然而,研究人員使用其他技術,例如:決策樹(Olson等人,2012),神經網路(Olson等人,2012),遺傳演演算法(Gouvêa等人,2012)和生存分析(Andreeva,2003)。
Gouvêa等。 (2012)提出了建立信用評分模型的七步迴圈,可用於製作任何型別的評分模型:
-
調查歷史客戶群:
有必要假設客戶隨著時間的推移具有相同的行為樣式; 基於此,收集過去的資訊用於構建模型。 在此階段,有必要定義模型的標的受眾,將使用哪些資訊以及收集資料的頻率以構建模型。 -
根據行為樣式和響應變數的定義進行客戶分類:
在此階段,定義要建模的客戶群組。 一般而言,使用兩種型別的客戶分類,稱為良好債務人和壞債務人。 一般而言,除了好的和壞的債務人之外,還可能有被排除的客戶(具有特定特徵且不應被視為例如在該機構工作的個人)和不確定的客戶(那些在 所謂的“灰色區域”並不能被歸類為好或壞,例如,新客戶)。 無論是在市場實踐還是在學術論文中,趨勢都只適用於好壞債務人(Olson et al.2012)。 -
從歷史資料中隨機選擇代表性樣本:
為避免因(樣本)大小而產生任何偏差,重要的是在預定義的組中對取樣進行均等分層。 抽樣的客戶數量取決於幾個因素,例如樣本規模和獲取資料的便利性,樣本的同質性等; 然而,Lewis(1992)提出,對於每種型別的響應,對於1,500個樣本客戶,已經可以獲得穩健的結果。 通常,研究使用兩個樣本集,第一個用於構建模型,第二個用於驗證和測試模型。 -
描述性分析和資料準備:
在此階段,使用統計標準分析模型中使用的每個變數。 -
選擇和應用用於構建模型的技術:
在本研究中,我們將使用Logistic回歸。 Gouvêa等。 (2012)對評分模型進行了文獻綜述,並確定了在這些模型中使用的以下技術:線性回歸,Logistic回歸,分類樹,線性規劃,遺傳演演算法,神經網路,判別分析和REAL。 學術研究的結果證實,沒有任何技術被證明總是優於其他技術,因為根據要建模的資料,某個技術可能勝過其他技術。 -
模型比較標準的定義:
在這一步中,我們確定了模型比較的標準; 最常用的工具是基尼繫數,ROC曲線,Kolmogorov-Smirnov(KS)測試和命中率。 -
選擇和實施最佳模型:
所有涉及的領域應該匯聚在一起以確定實施計劃:所有相關人員都應明確截止日期,階段和預期影響,以避免在整個過程中出現意外。
催收評分模型
催收評分模型旨在估計已經違約的客戶的還款機率。 這意味著催收模型的標的受眾包括未能在與債權人商定的最後期限內履行義務的客戶。 這種型別的模型是一種有助於根據已經違約的客戶還款機率來估算損失的工具。 將具有不同程度破產的客戶分成小組,將需要進一步催收行動的人與不需要立即收費的人分開(Sadatrasoul等人,2013年)。 由於在這種情況下,模型是與已經與機構建立關係的客戶建立的,因此建模中使用的變數可以分為兩組:
-
登記資料:客戶的年齡,性別,婚姻狀況,地址等,以及從信用局獲得的資訊(抗議,不良檢查,糾紛和財務限制)。
-
與公司的客戶關係:前幾個月的延遲付款,與公司的關係長度,客戶在以前的交易中花費的金額,以前與客戶的聯絡等。
方法方面
下麵我們介紹一些有關本研究開發的資訊; 我們使用適用於Windows v.21的SPSS軟體。
資料
一家專門從事不良貸款催收的公司提供了254,914名個人客戶的樣本,這些客戶來自於2013年5月在六個月內組建的投資組合,此樣本僅包括公司實際聯絡的客戶。 未聯絡的客戶不包括在樣本中,因為他們無法將其歸類為好或壞的債務人。
這類公司以低於債務價值的價格從一個機構(金融或非金融)購買投資組合(在本研究中,平均價格是債務價值的5%)。
響應變數的定義
定義的響應變數將基於客戶還款(或不還款)。 被定義為良好債務人的客戶是那些已經接受催收公司協議並且至少支付了一筆金額。 所謂壞賬者的定義是那些沒有接受任何協議的人或者接受了協議的人,但是他們沒有向催收公司支付任何分期付款而違反了他們的承諾。
樣本集
選擇了兩個樣本:一個用於構建模型,一個用於驗證模型。 在用於構建模型的樣本中,我們選擇了90,000個按響應變數分層的客戶,其中45,000個客戶被認為是良好的債務人,45,000個是壞賬者; 其他客戶仍然在模型的驗證和測試樣本中,我們發現了良好債務人的普遍性。
自變數
可用的客戶端註冊變數以及觀察到的行為變數用於構建模型。 它們如下:
-
客戶的年齡
-
債務值
-
預設天數
-
居住地區(北部,東北部,中西部,東南部和南部)
-
註冊中的住宅電話數量
-
註冊中的商務電話數量
-
註冊中的電子郵件數量
-
以前透過電話聯絡的人數
-
以前透過電子郵件聯絡的數量
-
對外部信貸局的限制(抗議,不良支票,Refin或Pefin)
-
由外部信貸局計算的分數
-
此客戶在該公司收集的投資組閤中出現的次數
所有變數都被分類到範圍,變成有序變數,以減少異常值的影響並使估計更加穩健。
Logistic回歸
如上所述,Logistic回歸是用於此類問題的最廣泛使用的技術; 它基於客戶被分類到每個組中的機率的計算。
根據Gouvêa等人的說法。 (2012年),採用這種技術有三個前提,如下:
-
沒有異常值:異常值應該從它在總體中的代表性的角度來看待,研究者應該評估它是否應該被保留或消除,以防它對結果產生不正當的影響。
-
低多重共線性:多重共線性意味著變數不是線性獨立的。 “高度的多重共線性可能會導致錯誤估計自變數的繫數,甚至會產生錯誤的訊號。”(Gouvêa等人,2012)
-
樣本量:樣本量應足以允許結果的推廣,這可以根據測試的統計顯著性進行驗證。 根據Hair等人的說法。 (2010),樣本的推薦最小尺寸應按每個預測變數至少10個觀察值的方式計算,每個組(好的和壞的),樣本的總大小應高於400個觀察值。
在本研究中,我們對尋求減少異常值影響的變數進行了分類; 為了防止多重共線性,選擇Logistic回歸模型變數的技術是向前逐步的; 該模型建立了90,000個案例,遠遠超過Hair等人提出的數量。(2010年)。
效能評估標準
使用的第一個效能評估標準是驗證樣本的選擇; 如果驗證樣本的結果接近開發樣本的結果,則意味著該模型適合用於其它情況。 其他兩個標準將用於評估模型的效能:命中率和Kolmogorov-Smirnov檢驗。
命中率
根據Crook等人的說法。 (2007),命中率是透過將正確分類的客戶總數除以屬於該模型的客戶數來衡量的。 必須對根據模型分析的每個客戶組(Good,Bad)進行相同的計算,以瞭解模型是否比其他模型更準確地識別客戶型別。
Hair等人。 (2010)建議將最低可接受命中率定義為實現分類的標準至少比單獨偶然獲得的準確率高出25%; 在這項研究中,偶然正確地對任何隨機客戶進行分類的機率為50%; 因此,最低可接受的準確率為62.5%(50%x 1.25); 如果樣本量不同,我們應該根據最大的組進行權重。
Kolmogorov-Smirnov測試
Kolmogorov-Smirnov(KS)檢驗是一種非引數統計技術,旨在確定兩個樣本是否來自同一群體(Siegel 1975); 就本研究而言,我們尋求區分好債務人和壞債務人。 為了應用該測試,為每個觀察樣本建立累積頻率分佈,對兩個分佈使用相同的間隔。對於每個間隔,從從一個函式值減去另一個函式值,測試註重觀察到的最大偏差。
根據Crook等人的說法。 (2007年),這是一個重要的區分度量; 在模型中獲得的KS越高,模型就能越好地區分壞債務人和壞債務人。
結果
下麵,給出並分析了邏輯回歸處理中獲得的結果。 最後,制定了催收公司經理的行動計劃方案。
Logistic回歸
在本文中,最初,包含所有變數以構建模型; 但是,在最終的邏輯模型中,只會選擇一些變數。 變數將使用前向逐步方法選擇,這是邏輯回歸模型中最廣泛使用的方法(Norusis 2011)。
由此產生的模型由29個變陣列成,客戶分類最重要的變數是違約期間,外部信用局的分類以及客戶之前是否透過電子郵件聯絡,如表1所示。。

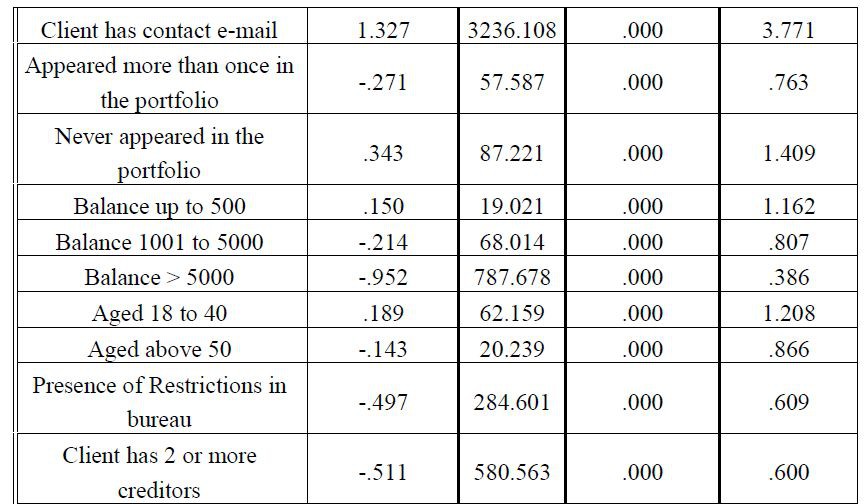
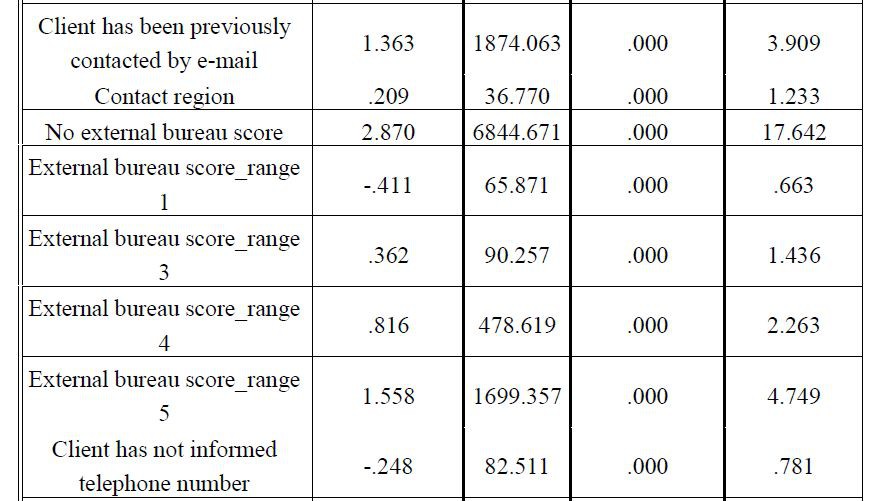
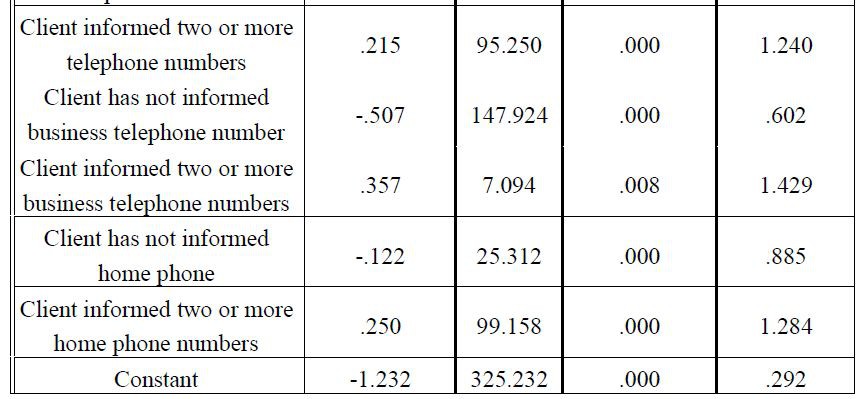
Omnibus測試測量模型是否能夠以所需的準確度進行預測(O’Connell 2006; Menard 2002)。 該分析的結果表明,顯著性檢驗證實該模型能夠正確地進行預測。
接下來,我們測試了模型的命中率。 表2顯示該模型的命中率在開發樣本中為83.9%,在驗證樣本中為83.4%。 好壞債務人的準確率百分比彼此接近,從開發樣本轉換到驗證樣本時沒有變化,這表明該模型的結果良好。

根據Sicsú(2010),KS高於0.70的模型被認為具有極好的辨別力,而KS在0.60和0.70之間的模型具有非常好的辨別力。 對於這些資料,對於開發樣品實現的KS測試的結果是0.680,而在驗證樣品中它達到0.679,表明,與開發樣品的結果良好且非常接近的命中率一樣。
擬議的行動
為了提出行動,我們將使用整個投資組合(包括開發和驗證樣本),其中每個客戶收到由邏輯模型確定的分數。 客戶分為20個同等大小的範圍(每個範圍約占人口的5%); 在這些範圍的每一個中,客戶端都會突出顯示為好或壞。 如果模型調整得很好,壞賬的最高集中度將在較低的範圍內,而所謂的良好債務人應該更頻繁地位於更高的範圍內(Lewis 1992; Mays 2001)。 下表3顯示了20個範圍內的分佈。


由於良好債務人的比例在每個範圍內增加,因此開發的催收評分模型實現了良好的劃分。 可以透過更靈活的催收政策來處理14到20之間的客戶,例如較低價值的折扣; 另一方面,範圍1到5之間的客戶可能是更積極的催收政策的焦點(例如更高的折扣)。
最後的考慮因素
本研究的目的是使用邏輯回歸將催收評分模型應用於不良貸款組合,結果是恰當的。
本研究提出了一個關於如何使現有報價適應所開發模型所確定的客戶概況的方案,因為在具有定製產品的市場中,允許客戶概況差異化的模型能夠幫助管理者基於受眾確定報價和標的策略。
這項研究提出了一些限制。第一個是使用公司提供的二手資料;所以不可能確保所有用於開發模型的變數都可用;同樣,催收公司之前已經將客戶歸類為好或壞債務人。第二個限制是文獻中關於催收評分的學術研究數量很少;根據Sadatrasoul等人的說法。 (2013年),難以獲得此類研究的資料庫,這阻礙了進一步研究的發表。
未來的研究可以集中於開發此類投資組合模型的其他技術,例如神經網路或遺傳演演算法;深化研究的另一個機會是更廣泛地瞭解公司的報價範圍,並根據現有政策建立盈利預測。
作者:Eric Bacconi Gonçalves
版權宣告:作者保留權利,嚴禁修改,轉載請註明原文連結。
資料人網是資料人學習、交流和分享的平臺http://shujuren.org 。專註於從資料中學習到有用知識。
平臺的理念:人人投稿,知識共享;人人分析,洞見驅動;智慧聚合,普惠人人。
您在資料人網平臺,可以1)學習資料知識;2)建立資料部落格;3)認識資料朋友;4)尋找資料工作;5)找到其它與資料相關的乾貨。
我們努力堅持做原創,聚合和分享優質的省時的資料知識!
我們都是資料人,資料是有價值的,堅定不移地實現從資料到商業價值的轉換!
加入資料人圈子或者商務合作,請新增筆者微信。

點選閱讀原文,進入資料人網,獲取資料知識。
公眾號推薦:
鏈達君,專註於分享區塊鏈內容。

艾鴿英語,專註於分享有趣的英語內容。
