在人工智慧時代,企業既想透過大資料分析、挖掘技術提升效率,又被大資料量分析、機器學習挖掘等相關技術門檻阻擾,需要一款資料分析挖掘產品跨越這個鴻溝。Jarvis在這個背景下應運而生。Jarvis是支撐大資料分析挖掘應用開發的工具和平臺,定位在企業開發者和大資料分析挖掘技術之間,提供視覺化互動方面的支援,使得大資料分析、挖掘技術能快速轉化為滿足企業應用場景的具體產品。
據瞭解,Jarvis技術實施棧縱向分層、橫向分級確保可全流程解決資料分析挖掘過程中的資料處理、計算資源、運算元演演算法支援、環境部署等各環節問題,同時針對使用者進行功能分級、並最大限度保持可擴充套件,為真正成為一款造福資料科學家、業務開發者、資料分析師、產品經理、決策分析者等各類開發使用者的產品而努力。

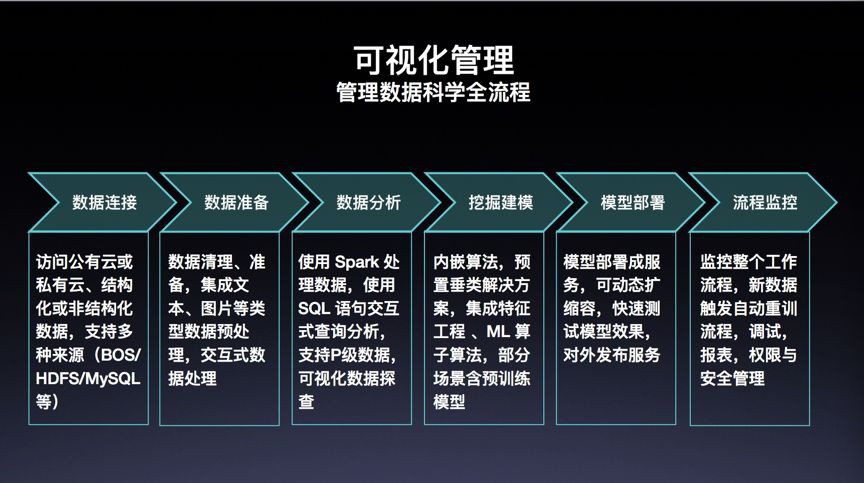
視覺化管理資料科學全流程
一個經典的資料挖掘分析應用過程包括,資料獲取、資料預期處理、特徵提取、建模開發、預測部署、投入應用。Jarvis充分調研分析開發實施人員在各環節面臨的處理場景、可能的高效、方便的工作方式,進行了抽象設計實現:
資料連線,支援結構化、非結構化多型別資料接入,支援私有資料接入、支援雲Bos、分散式HDFS、關係型資料庫等等多型別資料源讀取及靈活掛載。
資料準備,提供支援文字、影象型別的互動式的資料清洗、預處理工具,方便進行資料高效準備。
資料分析,支援PB級別的SQL互動式查詢分析、Spark處理;同時提供豐富的視覺化資料探查工具,方便開發者獲取高價值有效樣本。
挖掘建模,內建了豐富的基礎運算元演演算法供開發者高效進行建模開發;同時預置了經典的垂類行業解決方案,可以低成本在匹配場景進行高效實施。
模型部署,生成模型可直接釋出、部署,並支援動態熱載入。提供了常用模型評價指標的效果監控功能供一鍵選擇監控、支援自由擴充套件。
流程監控,開發者進行的全工作流實現自動Track,新資料可自動觸發重跑全流程。

雲原生服務
在資料分析挖掘全流程及服務過程中,不同的場景、不同的資料、不同的處理階段、不同的開發者對於環境的需求、對於資源的需求多種多樣,這就需要資料分析挖掘平臺的資源(包含開發環境資源)管理要能靈活接入、彈性拉伸、擴充套件方便,確保穩定及資源利用高效。Jarvis採用了雲原生服務架構的方式實現。

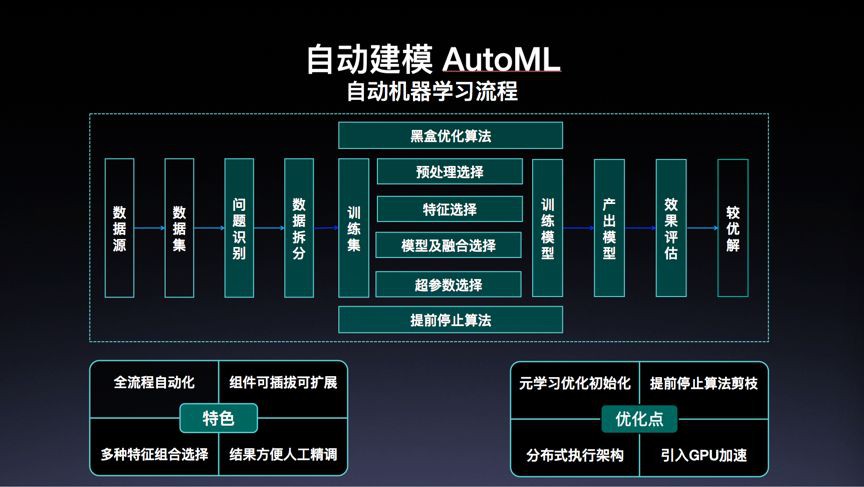
自動機器學習AutoML
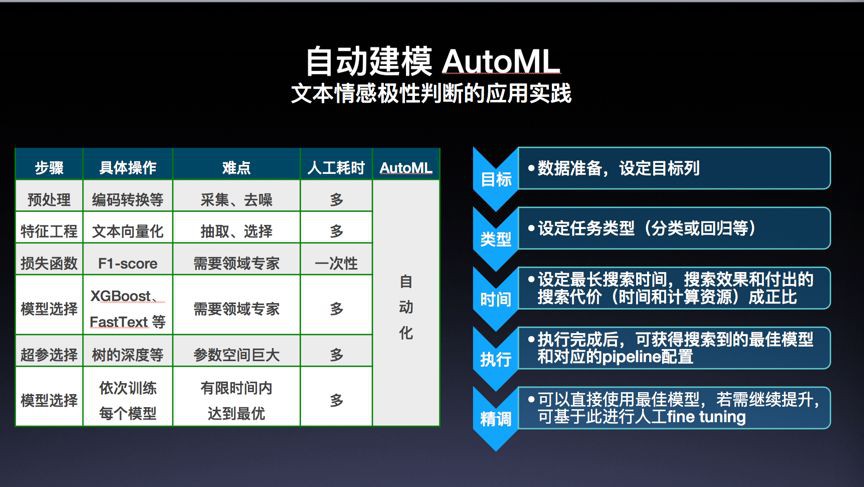
策略模型研發人員大量的時間花費在選取不同的特徵資料、進行不同的演演算法選擇嘗試、引數調優中,最終獲得一個高效的模型。AutoML理論上可透過設定自動嘗試多資料特徵、多演演算法、測試完全不同的模型架構,然後與標的相匹配,給出最終解決問題的方案。

行業解決方案
同行業的不同企業往往存在共性的資料分析挖掘場景,例如:電力行業,用電量預測;工業物理網類,裝置故障檢測、故障預測等。這些同類場景要解決的問題類似、要分析的資料類似,因此可以抽象通用的行業解決方案在同類場景下復用、快速投入應用。對於深層次的資料挖掘開發者,同樣有大量通用的演演算法、運算元庫可以相互復用,提升開發效率。Jarvis從基礎演演算法、通用模型、垂類解決方案分層內建能力並不斷擴充套件整合,為不同場景需求的開發者使用者提供了高效復用能力。


百度開發者大會期間,Jarvis透過點石-大資料眾智平臺(dianshi.baidu.com, DataLab板塊)邀測了第一批使用者進行增強版基礎開發環境的使用(內建了豐富的運算元演演算法庫及百度AI開放介面),受到使用者的一致好評。

敬請期待Jarvis後續的全面正式釋出、邀測!
