

在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @TwistedW。本文來自 UC Berkeley,GAN 生成的樣本在視覺方面已經達到與真實樣本很相近的程度了,有的生成樣本甚至可以在視覺上欺騙人類的眼睛。區分生成樣本和真實樣本當然不能簡單的從視覺上去分析,TequilaGAN 從影象的畫素值和影象規範上區分真假樣本,證明瞭真假樣本具有在視覺上幾乎不會被註意到的屬性差異從而可以將它們區分開。
如果你對本文工作感興趣,點選底部閱讀原文即可檢視原論文。
關於作者:武廣,合肥工業大學碩士生,研究方向為影象生成。
■ 論文 | TequilaGAN: How to easily identify GAN samples
■ 連結 | https://www.paperweekly.site/papers/2116
■ 作者 | Rafael Valle / Wilson Cai / Anish Doshi
GAN 和 GAN 的變種已經將影象生成質量達到了以假亂真的效果,雖然生成的一部分影象可以用肉眼去分辨,但是仍然有一部分由 GAN 生成的影象在視覺上很難和真實影象區分開。區分真假影象對於分析 GAN 的生成上具有一定的意義,同時也說明瞭 GAN 在生成上與真實影象的不同所在。TequilaGAN: How to easily identify GAN samples 一文將從視覺以外的方面去區分生成樣本和真實贗本之間的差距。
論文引入
使用 GAN 框架生成的假樣本在一定程度上騙過了人類和機器,使他們相信生成樣本與實際樣本無法區分。雖然這可能適用於肉眼和被髮生器愚弄的判別器,但生成樣本不可能在數值上與實際樣本無法區分。TequilaGAN 一文正是透過真實樣本和生成樣本在數值上的分析可以判斷出真假。
GAN 的生成資料的評判標準一直沒有很好的統一,大部分的評估是在定性的方面作分析,定量上 Inception Score [1] 一直被廣泛使用,但是 A Note on the Inception Score [2] 一文也指出了 Inception Score 未能為 GAN 模型的評估提供系統指導。
在已驗證的人工智慧的背景下,很難系統地驗證模型的輸出是否滿足其訓練的資料的規範,特別是當驗證取決於感知有意義的特徵的存在時。例如,考慮一個生成人類影象的模型,儘管可以比較真實樣本和假樣本的顏色直方圖,但還沒有強大的演演算法來驗證影象是否遵循從解剖結構得出的規範。
TequilaGAN 涉及假樣本的系統驗證,重點是比較假樣本和真實樣本的數值特性。除了比較統計彙總之外,還研究了 Generator 如何逼近實際分佈中的統計樣式,並驗證生成的樣本是否違反了從實際分佈中得出的規範。總結一下 TequilaGAN 的主要貢獻:
-
證明瞭假樣本在視覺上和真實樣本具有幾乎不會被註意到的屬性
-
這些屬性可用於識別資料來源(真實或生成)
-
證明瞭假樣本違反了從真實資料中學習的正式規範
研究方法
實驗主要集中在三點:第一點表明,假樣本具有視覺檢查難以察覺的特性,此特性與可微分的要求密切相關;第二個表明,從可用於識別資料的真實和假樣本中提取的特徵計算的統計矩之間存在數值差異;第三個表明假樣本違反了從真實資料中學到的正式規範。
資料集
實驗使用 MNIST,CIFAR10 以及從網上下載的 389 個 Bach Chorales 的 MIDI 資料集和 NIST 2004 電話會話語音資料集的子樣本。
特徵
特徵光譜質心[3] 是音訊領域常用的特徵,它代表光譜的重心。MNIST 和 Mel-Spectrograms 的特徵光譜質心如下圖所示示例。對於影象中的每一列,透過對列總和進行歸一化,將畫素值轉換為行機率,然後獲取預期的行值,從而獲得光譜質心。

試驗中同時表示了譜斜率圖:

GAN框架選取
GAN 框架使用最小二乘 GAN(LSGAN)和改進的 Wasserstein GAN(IWGAN / WGAN-GP)網路搭建使用 DCGAN 架構。還比較了使用快速梯度符號法(FGSM)生成的對抗性 MNIST 樣本。在生成器的輸出和其他變換(例如縮放的 tanh 和身份)上評估常用的非線性,sigmoid 和 tanh。
MNIST實驗
這部分著重於顯示由 GAN 偽造的 MNIST 樣品的數值特性以及肉眼未知的特徵。首先將透過 MNIST 訓練集計算的特徵分佈與其他資料集進行比較,包括 MNIST 測試集,使用 GAN 生成的樣本和使用 FGSM 計算的對抗樣本。將訓練資料縮放到 [0,1],並且從伯努利分佈取樣隨機基線,機率等於 MNIST 訓練資料中畫素強度的平均值 0.13。
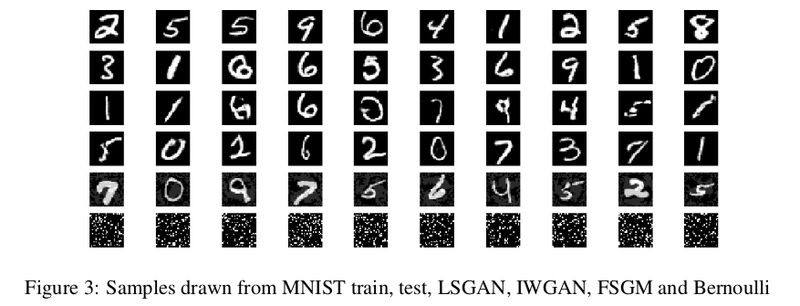
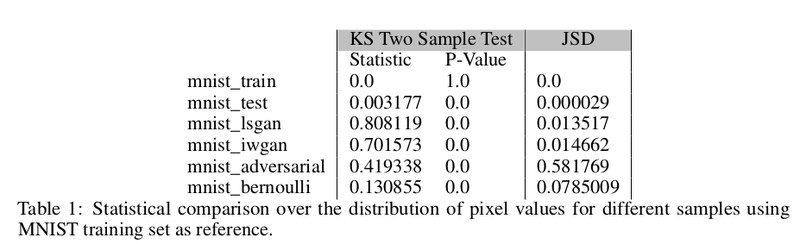
從上圖生成的樣本表明,IWGAN 似乎比 LSGAN 產生更好的樣本。在 Kolgomorov-Smirnov(KS)雙樣本檢驗和 Jensen-Shannon Divergence(JSD)上,LSGAN 和 IWGAN 生成的樣本如表一所示與標準資料集還是有一定的不同。
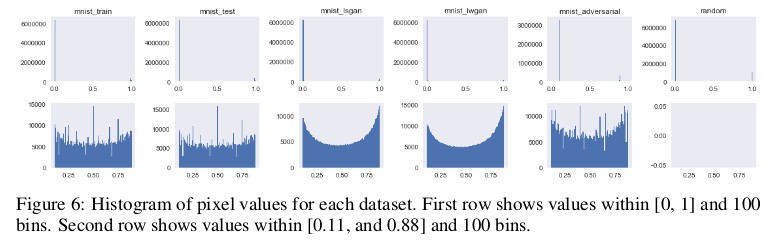
下圖中的經驗 CDF 可以理解這些數值現象,使用 GAN 框架生成的樣本的畫素值分佈主要是雙模態的,並且漸近地接近實資料中的分佈樣式值 0 和 1。

此外,光譜質心的統計矩的分佈圖表明假影象比真實影象更嘈雜。

最後,下圖顯示 GAN 生成的樣本平滑地接近分佈樣式,這種平滑近似與訓練和測試集有很大不同。雖然在感知上沒有意義,但這些屬性可用於識別資料源。
對分佈樣式的平滑逼近的解釋上,第一個假設是網路搭建採用隨機梯度下降和漸近收斂啟用函式(例如 sigmoid 或 tanh),為了驗證這一假設,保持判別器固定,在發生器的輸出端採用不同的啟用函式,包括線性和縮放的 tanh。如下圖所示,使用線性或縮放 tanh 啟用訓練的模型能夠部分地生成類似於 MNIST 訓練資料和畫素強度分佈的影象,仍然具有平滑的曲線。

另一個假設是平滑行為是由於訓練資料本身的畫素強度的平滑性,為了驗證這一點,首先透過在 [0,1] 之間對其進行縮放,然後將其設定為 0.5 來對實際資料進行二值化。透過這種改變,實資料的畫素強度的分佈變為完全雙模態,樣式為 0 和 1,從下圖結果顯示假設是合理的。

根據上述實驗可知,隨機梯度下降和方向傳播的應用使得生成的影象分佈上是平滑的,這是區分真假樣本的一個重要依據。
CIFAR-10實驗
CIFAR-10 的實驗主要是在 MNIST資料集的基礎上將畫素擴充套件到 3 通道的彩色影象上,實驗結果如下:

可以看出生成樣本仍然是平滑分佈。
Bach Chorales和Speech實驗
這兩種資料集都是在語音資料下比較的,Bach Chorales(巴赫合唱)音樂是復調的音樂作品,通常為 4 或 5 種聲音編寫,遵循一系列規範或規則。例如,全域性規範可以宣告只有一組持續時間有效;本地規範可以宣告只有狀態(音符)之間的某些轉換才有效,具體取決於當前的和聲。
實驗中,將 Bach Chorales 資料集轉換為鋼琴捲,鋼琴捲是一種表示,其中行表示音符編號,串列示時間步長,單元格值表示音符強度。實驗的目的是為了證明生成的樣本是否違反了 Bach 合唱的規範。下圖為真實和生成的樣本資料,表 2 為打破規則的次數:


雖然圖 11 顯示的生成樣本看起來與實際資料類似,但 IWGAN 樣本有超過 5000 次違規,比測試集多 10 倍!違反規範是一個有力的證據,表明假樣本不是來自與真實資料相同的分佈。
在語音(speech)域中,實驗研究了 Mel-Spectrogram 特性。將 NIST 2004 資料集劃分為訓練和測試集,將語音轉換為 Mel-Spectrogram 圖,得到的生成樣本如下:

經驗 CDF 的對比結果如下:

總結
TequilaGAN 研究了用對抗方法生成的樣本的數值特性,特別是生成對抗網路。實驗發現假樣本在視覺具有與真實樣本幾乎無法註意到的特性,即由於隨機梯度下降和可微分性的要求,假樣本平滑地接近分佈的主導樣式。
實驗還對真實資料與其他資料之間差異的統計度量,結果表明,即使在簡單的情況下,例如畫素強度的分佈,訓練資料和偽資料之間的差異對於測試資料而言是大的,並且假資料嚴重違反了實際資料的規範。
參考文獻
[1]. Tim Salimans, Ian J. Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. CoRR, abs/1606.03498, 2016.
[2]. Shane Barratt and Rishi Sharma. A note on the inception score. arXiv preprint arXiv: 1801.01973, 2018.
[3]. Geoffroy Peeters. A large set of audio features for sound description (similarity and classifica- tion) in the cuidado project. Technical report, IRCAM, 2004.
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 下載論文
