

談起HPC時,似乎繞不開Lustre。Lustre是HPC的代名詞,它是開源HPC並行檔案系統市場佔有率最高的檔案系統,並得到瞭如Intel和DDN等廠商的大力支援。目前,Intel與Lustre相關的業務已經被DDN所接手。
鑒於Lustre在HPC行業的知名度和認可度,今天,給讀者分享一篇關於Lustre調優的文章,目的是給Lustre學習者和愛好者提供些學習參考。
1 Lustre效能最佳化參考
1.1 網路頻寬
網路頻寬往往決定著lustre檔案系統的聚合頻寬。Lustre是透過多個OSS同時讀取資料來提高系統整體的讀寫效能,然而,如果網路傳輸的效能過低,則無法發揮lustre檔案系統的效能優勢。從以下幾點考慮網路頻寬對效能的影響:
-
網路型別(TCP/IP網路及Infiniband網路)
-
網絡卡型別(千兆網/萬兆網)
-
網絡卡數量及系結方式(網絡卡系結一起)
-
網絡卡系結樣式
補充:
-
通常情況下Infiniband網路效能遠遠高於TCP/IP網路,但成本較高
-
萬兆網比千兆網效能高
-
網絡卡系結樣式一般為6。
1.2 Lustre自身設定
Luster自身設定主要是條塊數(即OST的個數)及如何條塊化,這兩方面也是lustre實現I/O併發的關鍵。條帶化能夠使系統達到併發的目的,從而影響了系統的效能。Luster自身設定對系統效能的影響主要從以下幾個方面:
-
條塊大小(stripesize,min=64KB)
-
條塊數(stripecount)
-
起始塊數(start-ost,即條塊起始位置)
補充:
-
通常情況下start-ost預設為-1,不需要進行修改,該設定即不指定初始位置,能夠很好達到負載均衡的目的
-
通常情況下lustre條塊的大小的增加,聚合頻寬總體呈下降趨勢,當條塊過大時,某一時間內的多個I/O發生在同一個OST上,造成I/O等待,通常設定為64KB
-
通常情況下,隨著條塊數增加,聚合頻寬總體呈上升趨勢,在一定的環境下,合理的配置OST可以良好的發揮lustre的系統效能。
1.3 客戶端設定
Lustre檔案系統中,客戶端生成一個全域性儲存空間,使用者資料透過客戶端存入lustre檔案系統中,所客戶端的設定也會影響系統的效能。
主要從以下幾點:
-
單個客戶端行程數(連線數)
-
讀寫塊大小
-
客戶端數量
補充:
-
隨著連線數(行程數)的增加,聚合頻寬開始呈上升趨勢,到一定程度後穩定(此時系統效能尚未達到飽和),隨著連線數的增加,頻寬開始下降
-
隨著I/O讀寫塊的大小增加,聚合頻寬開始呈現上升趨勢,到一定程度後穩定,隨後增加塊大小聚合頻寬反而下降,當64KB~64MB大小時,保持穩定
-
隨著客戶端數目的增加,讀樣式下的聚合頻寬明顯提高,而寫樣式下的聚合頻寬則變化不明顯。
1.4 儲存RAID
Luster底層儲存裝置採用通用儲存裝置,可以是單磁碟,也可以是RAID,也可以是LVP,大部分採用RAID方式,既能保證聚合儲存容量,又能提供資料保護。主要從以下幾點說明:
-
RAID方式(硬RAID/軟RAID)
-
RAID樣式(RAID0/1/2/3/4/5/6/10/01)
-
硬RAID卡型別
-
做RAID的磁碟型別(SATA、SAS、SSD)
補充:
-
通常情況下,lustre檔案系統底層採用硬RAID的方式進行底層儲存,效能遠遠大於軟RAID,但成本高
-
Luster通常做RAID6,提高資料保護
-
OST磁碟一般採用低成本的SATA盤,而MDS則一般採用SSD盤
2 Lustre小檔案最佳化
2.1 整體設定
-
1、透過應用聚合讀寫提高效能,比如對小檔案進行Tar,或建立大檔案或透過loopback mount來儲存小檔案。小檔案系統呼叫開銷和額外的I/O開銷非常大,應用聚合最佳化可以顯著提高效能。另外,可以使用多節點、多行程/多執行緒盡可能透過聚合來提高I/O頻寬。
-
2、應用採用O_DIRECT方式進行直接I/O,讀寫記錄大小設定為4KB,與檔案系統保持一致。對輸出檔案禁用locking,避免客戶端之間的競爭。
-
3、應用程式儘量保證寫連續資料,順序讀寫小檔案要明顯優於隨機小檔案I/O。
-
4、OST採用SSD或更多的磁碟,提高IOPS來改善小檔案效能。建立大容量OST,而非多個小容量OST,減少日誌、連線等負載。
-
5、OST採用RAID 1+0替代RAID 5/6,避免頻繁小檔案I/O引起的資料校驗開銷。
2.2 系統設定
-
1、禁用所有客戶端LNET debug功能:預設開啟多種除錯資訊,sysctl -w lnet.debug=0,減少系統開銷,但發生錯誤時將無LOG可詢。
-
2、增加客戶端Dirty Cache大小:預設為32MB,增大快取將提升I/O效能,但資料丟失的風險也隨之增大。
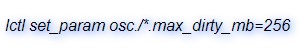
-
3、增加RPC並行數量:預設為8,提升至32將提高資料和元資料效能。不利之處是如果伺服器壓力很大,可能反而會影響效能。
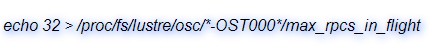
-
4、控制Lustre striping:lfs setstripe -c 0/1/-1 /path/filename,如果OST物件數大於1,小檔案效能會下降,因此將OST物件設定為1。
-
5、客戶端考慮使用本地鎖:mount -t lustre -o localflock,如果確定多個行程從同一個客戶端進行寫檔案,則可用localflock代替flock,減少傳送到MDS的RPC數量。
-
6、使用loopback mount檔案:建立大Lustre檔案,與loop裝置關聯並建立檔案系統,然後將其作為檔案系統進行mount。小檔案作用其上,則原先大量的MDS元資料操作將轉換為OSS讀寫操作,消除了元資料瓶頸,可以顯著提高小檔案效能。
這種方法應用於scratch空間可行,但對於生產資料應該謹慎使用,因為Lustre目前工作在這種樣式下還存在問題,操作方法如下:

3 檔案說明
-
Lustre檔案系統的效能最佳化研究2011(王博,李先國,張曉)
-
基於軟RAID的lustre效能影響要素簡析2008(張丹丹,姚繼峰)
-
Luster I/O效能最佳實踐
-
Luster檔案系統I/O效能的分析和改進(林鬆濤,周恩強,廖湘科)
關於高效能運算技術,前期詳細總結分享過<高效能運算(HPC)技術、方案和行業全面解析>電子書,請點選原文連結查閱詳情。
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲閱讀原文瞭解更多。

求知若渴, 虛心若愚

