李小翠 / 網易雲高階研發工程師
畢業於成都電子科技大學,目前在網易雲負責小檔案儲存系統(NEFS)的開發和產品化工作。對於分散式一致性協議,分散式儲存系統各方面 Golang 的應用有較豐富的一線實踐經驗。
前言
我是來自網易雲儲存團隊的李小翠,自入職以來便一直在團隊中致力於對照儲存的研發。今天演講的核心內容便是向各位介紹一下我們的網易新一代物件儲存引擎NEFS。
物件儲存是什麼?
首先讓我們先來瞭解一下物件儲存是什麼。
物件儲存提供 Key Value 儲存,Key 的最大儲存範圍是1KB,存入資料 ID,而 Value 最大為1TB,包含檔案、映象、圖片、影片等等,物件儲存並不像檔案系統那樣需要維持很深的目錄樹,一般分級是兩層或三層,所提供的 RestFul 是資料讀寫介面。

我們今天將從以下三個方面對儲存引擎進行說明。第一,整體概述網易物件儲存的基礎架構。第二,對對照儲存系統中的物件儲存引擎進行詳細說明。最後,對在開發NEFS系統過程中所做的效能最佳化和質量保障方面的一些工作進行說明。
物件儲存基礎架構
網易物件儲存基礎架構是:首先對一個使用者請求進行執行解析,然後到前端的交換機進行負載均衡,交給 Nginx 之後,再把請求交給 Proxy Cluster,在 Proxy Cluster 儲存架構中它是無狀態的,經過驗證之後會透過請求的資訊去 DDB 中找到 K,透過 K 可以讀取出儲存資料的元資訊,比如它的儲存位置等,我們根據這個元資訊可以讀出資料物件,而 NEFS 就是一個物件儲存引擎,負責資料的儲存。對於使用者來說,我們暴露的結果是 PUT、GET和DELETE,這個層面我們不做修改。

新一代物件儲存引擎
設計標的
在開發 NEFS 之前,網易有一個物件儲存系統叫做 DFS,但由於它的設計非常簡單,比如:沒有一個複製協議的概念,每個物件就是一個檔案,而恰恰這樣的設計對於小檔案是非常不友好的,所以在設計 NEFS 的時候,初衷是在 DFS 基礎之上設計一個能改寫未來五到十年需求的系統。
當時的設計標的主要有以下幾點:
一、單叢集規模達到100 PB,有500臺機器左右。
二、工作負載可以適應大小檔案,能減少多餘的 IO,避免一些IO放大。
三、可靠性方面,可以支援傳統的多副本的儲存,對於3副本可以達到8個9的可靠性,EC 則可以達到11個9。
四、可用性大於99.95,組建高可用,減小依賴。
五、可擴充套件性方面,不影響效能,並且可以支援資料的均衡。在資料均衡過程中,也希望不要進行大規模的資料遷移。
六、支援多租戶,支援不同特性的使用者可以有不同特性的介質。
因此,用一句話概括的話,NEFS 就是基於 LOG 的高可用、高可擴、高可靠的物件儲存系統,全稱為 Netease File System。
接下來,我將會從使用者,運維和開發三個緯度來向大家介紹一下 NEFS。
整體介紹
對於使用者
對於使用者來說,NEFS 就是一個 Key-Valu 儲存系統,所謂 Key 是指標註的檔案邏輯位置,Value 是指任意大小的 blob 資料。對於提供給使用者的介面有四個,分別為:PutFile、GetFile、DeleteFile、GetFileInfo

運維角度
從運維角度來看,我們看到的 NEFS 是如下的拓撲結構。最上面是 User,不同使用者要求不同,所以這一模組主要起到的是隔離作用。Pool 是儲存池,儲存池所有型別都是一致的,Pool 之間是物理隔離的,每個儲存機只能屬於一個 Pool。Zone 是運維域的概念,為了副本的可靠性,在放置副本的時候會考慮到分散在不同的 Zone 中。Server是儲存機,掛載多個磁碟裝置。

對於開發人員
對於開發人員而言,我想應該從 NEFS 的組成部件說起。
Partition是Nefs的最小儲存單元,大小一般設定為20G。PS即PartitionServer,用於管理磁碟,一個PS管理一個磁碟,一個磁碟上有很多Partition。MDS是元資料管理伺服器,如磁碟空間的管理,副本成員的管理、機器上下線管理等。FSI 是 NEFS 提供的一個客戶端,我們可以直接透過該客戶端跟NEFS進行讀寫刪的互動。

接下來介紹一下 NEFS 的讀寫流程。
寫入:FSI從 MDS 獲得可寫Partition的資訊,MDS 把Partition副本的資訊傳回給 FSI,FSI選定PS請求寫入,PS將寫入的資料透過複製協議複製到其他副本後,傳回給使用者一個 FID。使用者可以透過FID讀取儲存的資料。

讀取:FSI對FID進行解析,獲取資料所在Partition,接著從MDS獲取Partition的副本資訊,採用backupRequest和roundRoubin的策略讀取資料。

以上是從不同角度對 NEFS 整體的介紹,下麵我將要針對 NEFS 的每個模組進行介紹。
模組分析
Partition
Partition 是 NEFS 最小的儲存單元,那麼 Partition 有些什麼特點呢?第一,使用者寫入的資料就是日誌,資料只追加,不修改。刪除資料直接追加一條刪除記錄,實際物理空間的回收由後續的垃圾回收進行。Partiton 由 datafile 和 hintfile 組成的。datafile 有隻讀和可以進行追加的active 狀態。 hintfile 是一個二級索引,和index一樣,用於垃圾回收時判斷刪除標記是否要刪除的一個依據。LogEntry 包含使用者資料的crc校驗,一致性協議相關資訊,以及使用者資料。之所以要包含一致性協議相關資訊,是因為Nefs透過一致性協議保障各副本的一致性,在日誌回放、副本不一致的情況下需要用到這些資訊。

一致性協議
NEFS 使用基於 PacifcA 的主從複製協議。過程比較簡單:使用者提交請求給 leader,leader 在日誌裡面進行追加,並且把請求傳送給其他副本,副本寫本地日誌完成之後,回覆leader,leader收到副本的應答之後對當前資料進行commit, 並把寫入結果傳回給客戶端。下一次寫入時,leader通知follower進行上條資料的commit.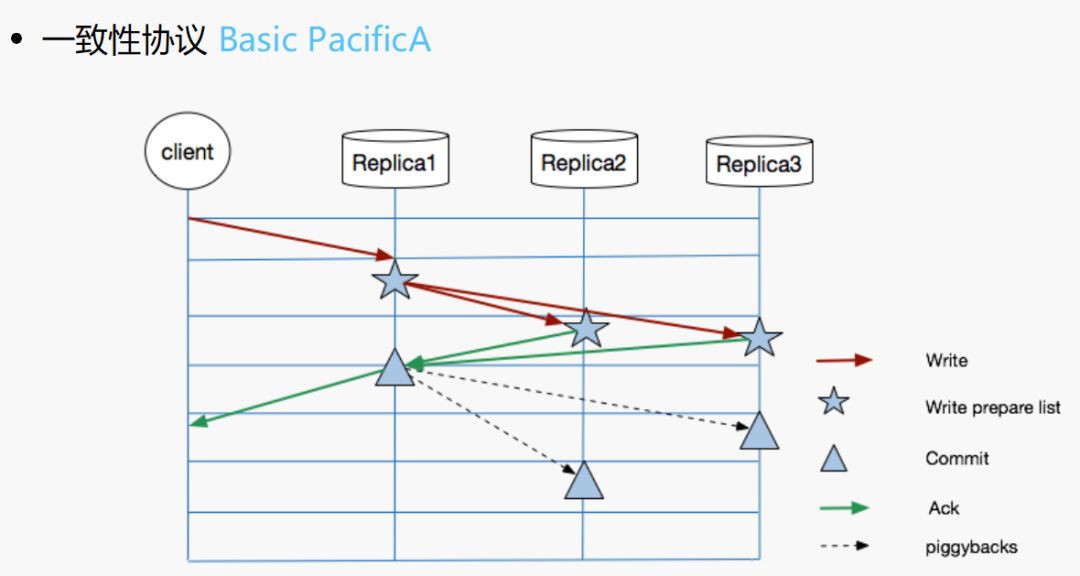
副本的關係不是一直不變的。比如有磁碟壞了,需要進行恢復,那麼該磁碟上涉及到的partition的副本的關係必然會變化;其次,機器負載不夠均衡,有些機器上的leader較多,寫入較多,就需要進行rebalance;再者,磁碟空間使用不均衡等,這些情況均涉及到成員的變更,由於NEFS是有中心的分佈儲存系統,因此成員變更都是透過 MDS 進行的。
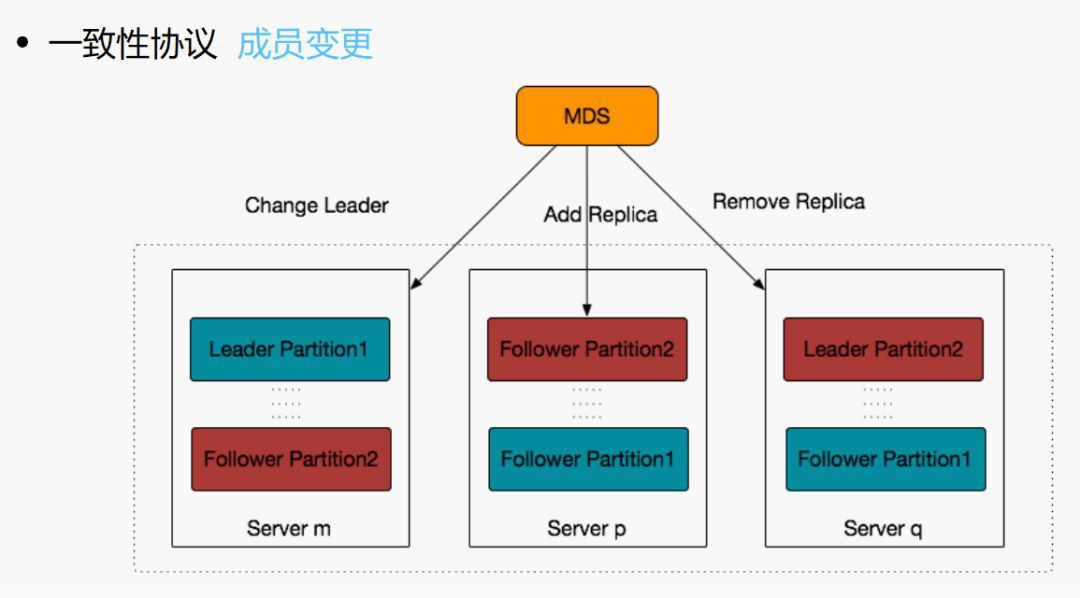
那我們當時選用類PacificA協議,也源於一部分原因是Raft其實在當時也沒有非常靠譜的工業化的實現,PacificA畢竟相對相對簡單。
如果現在進行系統設計、應該選擇什麼樣子的一致性協議?這裡就功能特性、非功能特性方面對兩個協議(pacificA、raft)做了一個簡要的對比。
從功能上來說:兩者的實現難度基本一樣。從實現角度可以發現,pacificA跟raft的差別基本只在最後傳回客戶端的條件判斷上,所以說一致性協議在針對不同的應用場景其實在一些點上可以有很大的變化,來滿足業務不同的需求,比如我們其實也很容易轉化為類似於Raft 的 F/2 +1。成員變更上,PacificA依賴中心節點更加簡單。
從效能上來說:類pacificA的協議是全寫才傳回,而raft是2/F +1 節點寫完就可以傳回。比如三副本的話,raft響應時間是3各種最快的2個,而pacificA全寫是三個中最慢的一個。響應時間的分佈基本呈現zifp分佈,跟磁碟寫入的時間呈現基本同樣的分佈趨勢,但是根據統計每個節點在寫磁碟上耗費的均值都只是60ms,但是寫三副本的耗時是大於60ms的。
從可靠性上看:pacificA在掛一個節點情況下沒法寫入,raft是多數派儲存,pacificA 略勝一籌,隨時隨地都是全副本的可靠性,raft是2/f +1;還有一點就是pacificA 只要有一個副本資料還在就不需要人工介入,但是,raft比如在3個節點情況下,掛2個,就需要人工介入。
要是總體回頭看,pacificA也還算是一個相對不錯的方案。當然就現在來說選擇Raft也不錯,反正都是可以現實的需求對協議進行一定調整。

接下來說一下NEFS非功能特性。
非功能特性
效能
NEFS 的效能:
一、只有一次寫入,IO 放大繫數是1。採用bitCast 小檔案合成大檔案模型,一次寫入只需要一次Append;另外本身多副本一致性協議 不需要額外的實時持久化的資訊。
二、大檔案在上層拆解為1MB的小檔案進行寫入,實現併發寫入,可以併發讀取。
三、最後根據現實情況,我們針對HDD效能在設計層面做了一些調優:
a.當然只能限制寫入,每個磁碟上能夠併發進行開寫的Paritition開支在8個左右
b.合併更多的小寫
c.因為刪除請求發往具體的某個Partition,如果持久化會帶來非常嚴重的隨機 IO,所以對Delete不刷盤

可靠性
可靠性:聽起來很虛,其實業界各個儲存的產品線一般都會有 明確的Durability的SLA,比如我們看AWS S3 物件儲存, Standard、Standard-IA、Glacier 對外保障的可靠性都是11個9。11個9翻譯一下就是100億個檔案一年只可能丟失1個檔案,能不能達到不說,沒達到,按照賠償條款進行賠償。
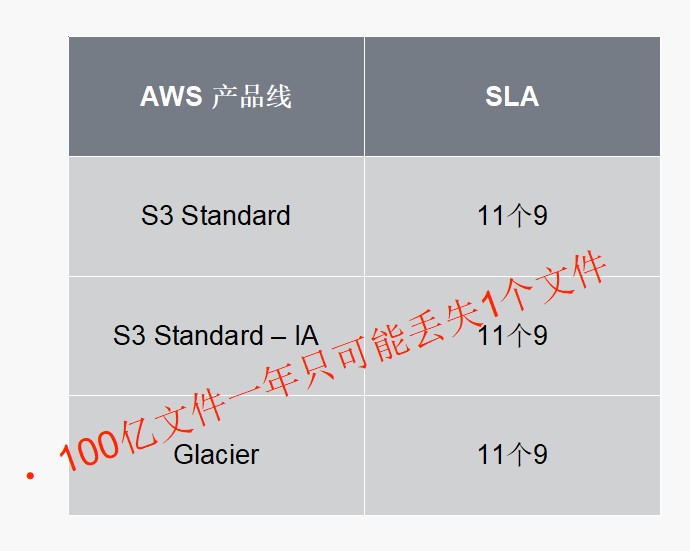
可靠性影響因素有幾個:
一、磁碟年故障率;顯然導致資料丟失,除了說程式Bug、運維 事故認為因素之外,主要就是磁碟故障,故障率越高可靠性越差。
二、複製因子,系統使用的副本數越多,顯然儲存可靠性越高
三、壞盤恢復時間,對於多副本系統中,壞盤請求導致資料副本的丟失,如果能夠越快恢復,可靠性越高。
四、系統中磁碟數量。
五、系統複製組數量。考慮如下兩個極端設計。
第一種設計,是在包含999塊磁碟的3備份儲存系統中,同時壞三塊盤情況下的資料丟失機率,它的可靠性還是比較高的。

而第二種設計,是我們把資料隨機打散掉999塊磁碟中,所有資料都可能在其他所有盤中,這樣資料丟失的機率就是1,也就是說資料一定會丟失,複製組太多或者太少,其實都有一定的弊端,太多可靠性就會下降。而接下來是系統中磁碟的數量,磁碟數量越多可靠性越低,這是為什麼呢?因為從全世界範圍內來看,肯定每天都有資料的丟失。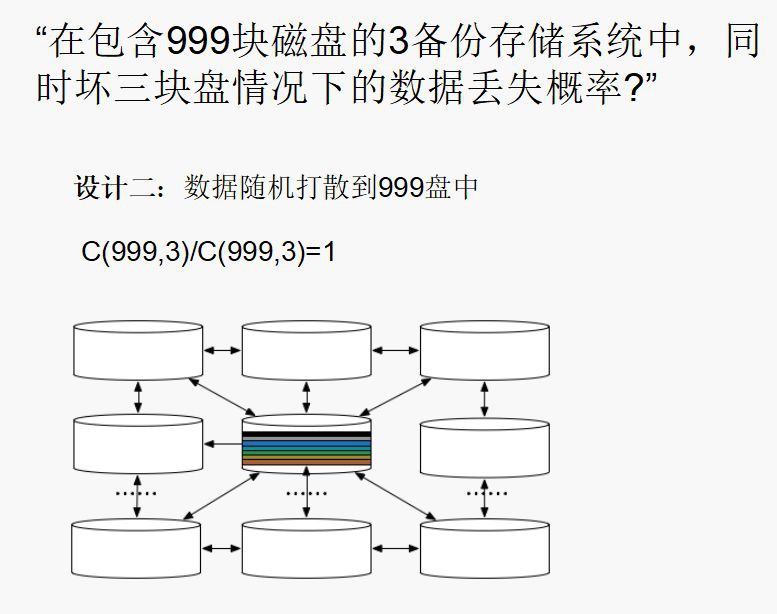
對於 NEFS 而言,在系統的硬體規劃中,2個交換機堆疊,下聯3個Rack,每個Rack放置9臺儲存機器,一個Zone 27臺機器;可用性考慮,2個副本放置在一個Zone,另外一個放置在另外一個Zone。為了加快恢復時間,設計考慮就是利用所有機器、磁碟的IO、頻寬進行恢復;一個磁碟上的Partition的副本打散在所有其他機器磁碟上(比如一個Zone的27臺機器上,每臺機器36塊盤)。從我們系統來說,一個磁碟上Partition的數量就是能夠打散在所有這些盤上即可。不要太小,太小會導致複製組 變大,所以一個Partition大概也就20GB左右。普通情況下,為了保障對外服務能力。但磁碟、機器 能夠參與恢復可能控制在10%差不多了。隨意最終結果看一塊8TB的盤,在1~2個小時恢復基本可以做到的。


成本
從直觀層面來說,多幾個副本是提高可靠性的唯一方式。但是從根源上來說,我們需要提高的是複製因子,也就是壞多少塊和這份資料直接相關盤的情況下會導致資料丟失。所以從這個層面來拓展,分散式儲存系統為了提高可靠性,基本可以透過兩種方式來達到目的:
1: 合適的多副本
多副本是比較顯而易見的,是透過客戶端或者服務端進行資料的多備份寫入。
2: EC 糾刪碼冗餘技術。
原理就是透過不同的幾份資料,透過矩陣換算得到冗餘資料塊,在出現壞塊情況下,透過其他幾份資料計算還原得到丟失的資料。 EC糾刪碼技術這裡不多作展開。

在NEFS系統中我們EC的實現原理:
EC基本單位:以Parititon下的data file 為EC的基本單位,一般來說一個data file 為1GB。
EC策略:比如10+4 的策略的話:將1GB 檔案拆分為10份資料塊,並計算出4份校驗塊。
1.容忍任意4個Block的丟失(看上去資料拆分更多更佳容易丟失資料,但是要壞容忍壞4副本,隨意一般來說EC的可靠性會比三副本可靠性高幾個數量級)
2.儲存開銷: 1.4x = 14/10
3.任意一個塊損壞,需要透過網路讀取10個Block進行恢復
當然也可以根據實際的情況,做更多的EC測測的選擇,更多的暫時不多做介紹,因為EC還在設計實現中,不太好說過多。

以上是對 NEFS 整個物件儲存系統在一些細節以及架構上的介紹,下麵主要說明一下在開發過程中我們對效能最佳化和質量保障做的一些工作。
效能最佳化和質量保障
效能最佳化
問題分析&解決
因為 NEFS 一直線上上使用,去年系統切進百分之百流量時,發生了機器負載過高,夜高峰記憶體使用量達到80%的情況,隨後採取臨時措施記憶體得以降低,後面是最佳化後的結果。
採取的臨時措施是降低GOGC的值,原來預設是100,我們調整為50後,預計golang GC的 頻率變高,釋放記憶體速度變快。雖然有一定的效果,但也帶來了一定問題:由於要清理的記憶體量較大GC 顛簸嚴重,停頓上百秒,並且線上有很多失敗請求,線上每個行程有兩百多個執行緒創建出來。所以這個調整是治標不治本。
後來我們對問題進行分析,發現在請求數量上升過程中,磁碟 IO 變高,處於系統呼叫狀態的協程變多了,執行緒數上升,記憶體佔用升高,這是現狀。請求數量上升,記憶體佔用更多,GOGC 更為頻繁,CPU 繁忙,導致GOGC 很慢,導致請求堆積,進一步加劇內記憶體佔用。所以要解決的有兩點問題:記憶體佔用問題以及整個過程中不能讓執行緒數量過多。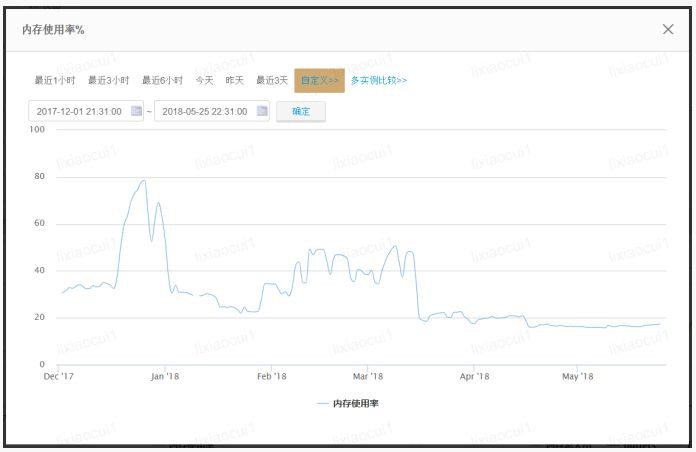

pprof 是golang自帶的效能調優工具,該工具收集程式執行時資訊,並給出記憶體佔用較大的函式呼叫。透過該工具我們發現關鍵路徑上有很多記憶體複製。
最佳化一是減少程式讀請求路徑上記憶體複製,改了之後發現對記憶體的使用並沒有很好的效果,只能降低10%左右。
再分析發現 thrift 中的資料記憶體複製在請求較多的情況下佔用記憶體較多。TFramedTransport 先把資料序列化後再複製,這裡做一個最佳化,序列化之後,不需要把內容複製到buffer中在flush。在我們的場景是可以相容的。改動完之後記憶體降低50%。
第二個問題執行緒數量會隨著讀請求的增多而增多。因此我們對 IO 做了兩層併發控制,一個是外層請求數量會控制併發,第二是磁碟IO併發控制,用來降低執行緒數量,減少機器的負載。
對IO併發控制則設定為60,單個最大併發度不超過200,併發度不能過小,因為過小會造成等待時間過長,很多請求會超時,當時也是做了測試,比如併發度為1的時候,我們發現排隊時間會達到5秒甚至超過10秒,當併發度為120的時候 wait tiem 會很小,60的時候也會很小。

場景&分析
場景主要是線上發現讀請求較多情況下,使用者請求延遲非常大,是 IO 延遲的數倍,並且併發越高延遲明顯增加。線下做了壓測發現,如果在 寫入併發達到20時,延遲高達幾百毫秒,但實際上刷盤時候就只有100毫秒。我們使用golang的trace工具跟蹤一個請求的生命週期是非常合適的。圖一顯示了一分鐘內,請求響應時間的統計,並且給出了分位點。圖二顯示了響應時間大於0.1秒的請求。所以透過trace工具,可以很快的看到當前系統是否正常。回到之前我們說的問題,trace可以在請求的生命週期內埋點,打印出每一步的延遲。這樣可以排查出耗時的步驟從而進行最佳化。

質量保障
NEFS 測試
單元測試和系統測試,應該是在系統開發過程中大家都會做的,構建思路也比較清晰。go提供的test測試框架可以方便的進行常規測試,耦合問題可以透過mockgen工具來解決。系統測試人可以從外部進行壓測、功能驗證; 也可以透過gofail 來控制鍵路徑上的異常傳回,整合測試做的事情,系統測試都可以做。但是如果每次系統測試,都需要構造相同的異常場景,把所有的點都測試一遍,費時費力。輕量級的系統測試是需要的,因此NEFS還做了整合測試。
整合測試在構建過程中需要考慮些什麼?
1.採用何種方式啟動ps,mds?我們可以用協程的方式,也可以用行程的方式執行,最初寫的時候還是以協程的方式做的,但是協程方式有一個問題,比如我想把這個 ps 掛掉,讓它下線,協程就很不方便了。因此這樣的方式後來沒有採用,最後我們採用行程的方式來啟動 ps 和 mds。
2.各元件之間網路通訊方式?採用net namespace的正規化
3.如何解耦ps,mds與zk,db的依賴?使用memzk,以及嵌入式的sqlite
4.程式處理異常如何模擬?使用gofail
5.客戶端fsi如何使用?FSI 是 NEFS 提供客戶端的 jar 包,而NEFS 的 Server 端使用 GO 編寫,因此我們最終做了一個解決方案:在 FSI 起一個 http Server,供測試所用。

NEFS質量保障
go的技術棧 提供了非常多便捷的工具,可以用來提高我們的程式碼質量
1、系統各個指標的收集 是監控 系統健康狀況的重要手段,也是發現問題和排查問題所需的必不可少的資訊。比如qps的收集、垃圾回收資料量的收集等
2、之前系統中存在不少問題,取用megacheck進行更高質量的程式碼檢查。程式碼最佳化中會有這樣的提示:複製slice的時候,使用何種操作更為簡便
mds/topology/pickup.go:143:3: should replace loop with nodes = append(nodes, dataNodes…)
3、go中還有輔助檢測race的工具,可以在整合測試中開啟


以上就是對 NEFS 的介紹,以及我們在真實開發過程中遇到的一些問題,歡迎有意向、有興趣加入網易儲存團隊的小夥伴們,一起參與設計研發的工作!
Q&A;
提問:李老師你好,我有一個問題,剛才說到刪除不刷盤,到底是什麼意思?
李小翠:這是我們做刪除操作的時候,一般物件儲存系統不會真的把那個物理檔案刪除,直接寫入一條刪除標記,對於刪除記錄我們不做sync操作。
提問:還有一個問題,中間有說近來併發比較大,最佳化到thrift協議裡面去的最佳化,我看你們最後還是做了一個快取,那個快取跟TCP快取有什麼區別嗎?
李小翠:其實原來它是為了把所有資料都收集下來,完全寫成一幀。
提問:thrift的演演算法,不管你寫多少都會快取成一個……
李小翠:對,比如我在這裡進行一個快取,這個資料很大,比如原來這個是128,現在資料有256,是不是要重新搞一個256的記憶體,然後把128的釋放?會有這種記憶體的開銷。當我們讀特別多的時候,這個開銷就會放大。所以我們這裡做buffer,就是為了幾個位元組的時候都拼起來,做成一幀再寫入。再大的時候就沒有必要了,是為了防止buffer變長的一個開銷。
提問:你好,使用者那一側怎麼找到那個小紅鍵呢?鏈路怎麼走?
李小翠:因為我們在寫入完成後會傳回一個FID給使用者,由partitionID和InternalID組成,internalID在partition中是遞增的。透過FID可以確定資料所在的位置
提問:剛才還涉及到機房問題,使用者資料過來的時候其實都是隱藏在後面的,使用者進來可能是最外一層,怎麼知道是哪個Pool?
李小翠:Pool的相關資訊儲存在mds中,Pool是一個邏輯上的概念,是面向nefs伺服器的,mds會記錄user和pool的對應關係。使用者角度是沒有pool的概念的。
提問:我有一個問題,你提到做磁碟的(英文),還包括刪除以後只是寫一條追加記錄,等後面有GC的過程,可能這個GC是跟(英文)一起做的,這方面的介紹您介紹的比較少,我想知道如果要做這個(英文)怎麼管理?這是一個自動的過程還是運維的過程?
李小翠:這是一個自動的過程,我們會有一個預值,比如多久開始對它做資料恢復。因為PS上面很多(英文),假設一個副本是放在1、2、3PS上,這個3掛掉了,MDS會針對當前負載資訊選擇一個PS,讓它作為第三個副本,讓它去恢復,整個過程都是MDS控制的。還有leader的變更也是由MDS做的,因為複製協議會有這樣一種情況,就是寫都是從leader過的,假設你的PS上有幾百個leader,都是申請到這個PS上,這個負載就會非常大。所以我們會讓leader盡可能分佈在不同的PS上面,因為原來沒有這種設計,會出現不均衡,也是根據當前每個PS上leader的數量,對他進行均衡以及leader的切換,這都是在後臺每隔5分鐘做一個檢查,是以這種樣式來的。
提問:資料刪除你們什麼時候做清理?
李小翠:資料刪除先有一個記錄,在晚上的時候做清理,因為需要讀取資料,所以白天做可能對使用者請求有影響。我們做GC怎麼做的呢?比如我們掃描這個資料,看這裡面資料的比例,比如如果達到0.8我們就進行回收,垃圾回收是走複製協議的,因為所有的複製協議是基於位元組一致的基礎之上。對於這裡面非垃圾資料會根據資料協議進行重寫,寫完了就會把這個資料刪掉。
提問:刪除資料你們是晚上批次去做?
李小翠:是的。
提問:我有一個問題,我覺得你這個架構跟(英文)特別像,但是有一點不同,你中間有原資料重組,有MDS,如何實現高可用呢?
李小翠:實際上我們會部署三個,然後進行選組,我們會做備份,另外兩臺是處於備狀態,其他掛掉了會由它做備份。
提問:為什麼不做成分散式叢集?只有一個在執行,有一個掛了以後再把另外一個接進來?
李小翠:對,是這樣的。
長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。
微信掃一掃
使用小程式