點選上方“芋道原始碼”,選擇“置頂公眾號”
技術文章第一時間送達!
原始碼精品專欄
這次天池中介軟體效能大賽初賽和複賽的成績都正好是第五名,本次整理了複賽《單機百萬訊息佇列的儲存設計》的思路方案分享給大家,實現方案上也是決賽隊伍中相對比較特別的。
賽題回顧
-
實現一個行程內的佇列引擎,
單機可支援100萬佇列以上。 -
實現訊息put、get介面。
-
在規定時間內完成
資料傳送、索引校檢、資料消費三個階段評測。
評測邏輯
-
各個階段執行緒數在20~30左右。
-
傳送階段:訊息大小在50位元組左右,訊息條數在20億條左右,也即傳送總資料在100G左右。
-
索引校驗階段:會對所有佇列的索引進行隨機校驗;平均每個佇列會校驗1~2次。
-
順序消費階段:挑選20%的佇列進行全部讀取和校驗;
-
傳送階段最大耗時不能超過1800s;索引校驗階段和順序消費階段加在一起,最大耗時也不能超過1800s;超時會被判斷為評測失敗。
評測環境
-
測試環境為4c8g的ECS虛擬機器。
-
帶一塊300G左右大小的SSD磁碟。SSD效能大致如下:iops 1w左右;塊讀寫能力(一次讀寫4K以上)在200MB/s左右。
賽題分析
對於單機幾百的大佇列來說業務已有成熟的方案,Kafka和RocketMQ。
| 方案 | 幾百個大佇列 |
|---|---|
| Kafka | 每個佇列一個檔案(獨立儲存) |
| RocketMQ | 所有佇列共用一個檔案(混合儲存) |
若直接採用現有的方案,在百萬量級的小佇列場景都有極大的弊端。
| 方案 | 百萬佇列場景弊端 |
|---|---|
| Kafka獨立儲存 | 單個小佇列資料量少,批次化程度完全取決於記憶體大小,落盤時間長,寫資料容易觸發IOPS瓶頸 |
| RocketMQ混合儲存 | 隨機讀嚴重,一個塊中連續資料很低,讀速度很慢,消費速度完全受限於IOPS |
為了兼顧讀寫速度,我們最終採用了折中的設計方案:多個佇列merge,共享一個塊儲存。

設計核心思想
-
設計上要支援邊寫邊讀 -
多個佇列需要合併處理 -
單個佇列的資料儲存部分連續 -
索引稀疏,盡可能常駐記憶體
架構設計
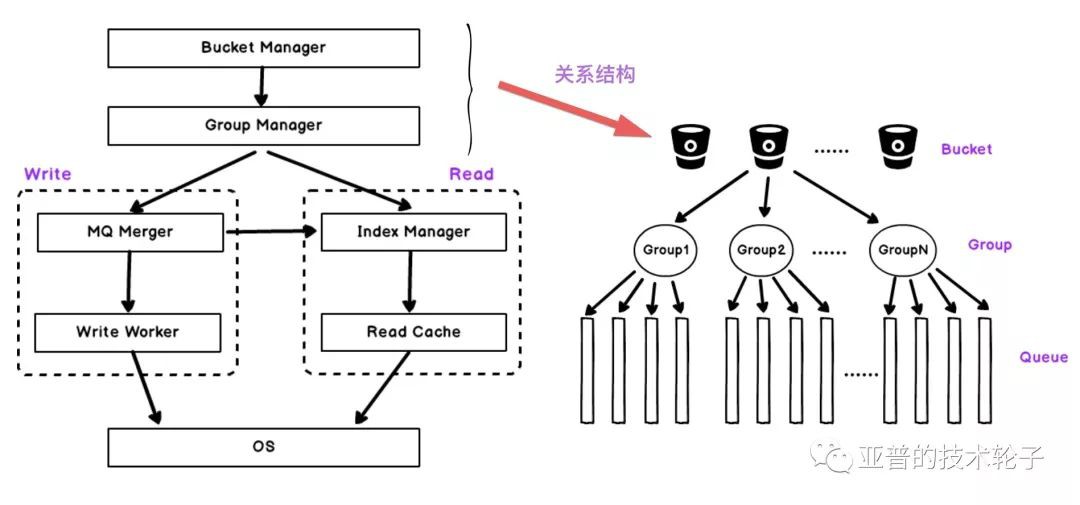
架構圖中Bucket Manager和Group Manager分別對百萬佇列進行分桶以及合併管理,然後左右兩邊是分別是寫模組和讀模組,資料寫入包括佇列merge處理,訊息塊落盤。讀模組包括索引管理和讀快取。(見左圖)
bucket、group、queue的關係:對訊息佇列進行bucket處理,每個bucket包含多個group,group是我們進行佇列merge的最小單元,每個group管理固定數量的佇列。(見右圖)
儲存設計

-
對百萬佇列進行分桶處理。
-
每個Bucket中分為多個Group,每個Group為一個讀寫單位,對佇列進行merge,同時更新索引和資料檔案。
-
單個Group裡對M個佇列進行合併,超過16k或者壓縮超過16K(可配置)進行索引更新和落盤。
-
索引部分針對每個Block塊建立一個L2二級索引,然後每16個L2建立一個L1一級索引。
-
資料檔案採用混合儲存,對Block塊順序儲存。
接下來對整個儲存每個階段的細節進行展開分析,包括佇列合併、索引管理和資料落盤。
MQ Merge
1. 百萬佇列資料Bucket Hash分桶

2. Bucket視角

-
每個Bucket分配多個Group
-
Group是管理多個佇列的最小單位
3. Group分配過程

-
每個bucket持有一把鎖,順序為佇列分配group,這裡我們假設merge的數量為4個佇列。
-
資料的達到是隨機的,根據佇列的先後順序加入當前Group。
-
當Group達到M個後便形成一個固定分組。相同佇列會在Group內進行合併,新的佇列資料將繼續分配Group接收。
4. Group視角的資料寫入

-
每個Group會分配Memtable的Block塊用於實時寫入。
-
當Block達到16k(可配置)時以佇列為單位進行資料排序,保證單個佇列資料連續。 -
位元組對齊,Memtable變為不可變的Immemtable準備落盤。
-
開闢新的Block接收資料寫入。
索引管理
1. L2二級索引
L2二級索引與資料儲存的位置息息相關,見下圖。為每個排序後的Block塊建立一個L2索引,L2索引的結構分為檔案偏移(file offset),資料壓縮大小(size),原始大小(raw size),因為我們是多個佇列merge,然後接下來是每個佇列相對於起始位置的delta offset以及訊息數量。
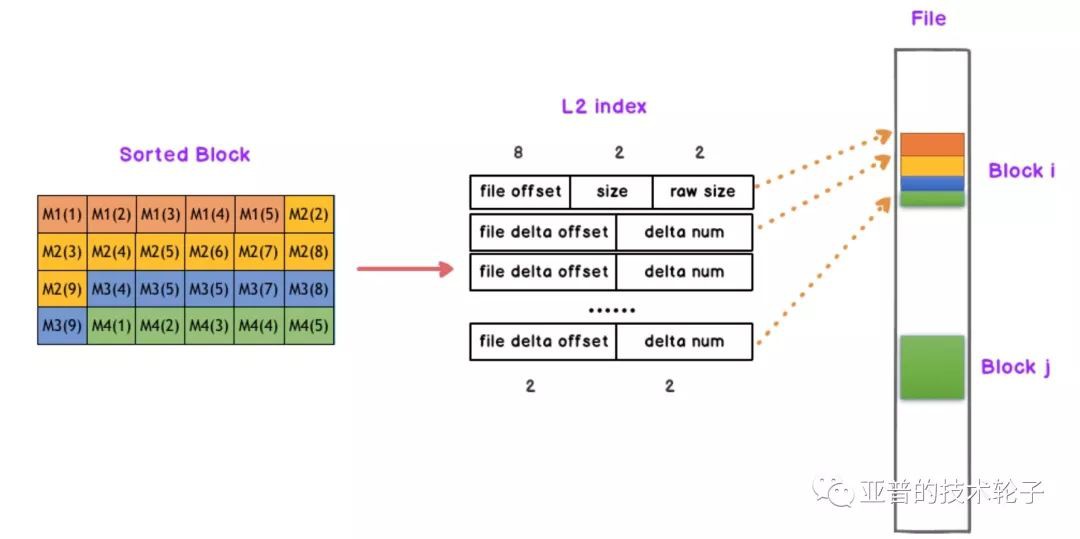
2. L1一級索引
為了加快查詢速度,在L2基礎上建立L1一級索引,每16個L2建立一個L1,L1按照時間先後順序存放。L1和L2的組織關係如下:

L1索引的結構非常簡單,file id對應訊息儲存的檔案id,以及16個Block塊中每個佇列訊息的起始序列號seq num。例如MQ1從序列號1000開始,MQ2從序列號2000開始等等。

3. Index Query
如何根據索引定位需要查詢的資料?
對L1先進行二分查詢,定位到上下界範圍,然後對範圍內的所有L2進行順序遍歷。

Data Flush
1. 同步Flush
當blcok超過指定大小後,根據桶的hashcode再進行一次mask操作將group中的佇列資料同步寫入到m個檔案中。
同步刷盤主要嘗試了兩種方案:Nio和Dio。Dio大約效能比Nio提升約5%。CPP使用DIO是非常方便的,然而作為Java Coder你也許是第一次聽說DIO,在Java中並沒有提供直接使用DIO的介面,可以透過JNA的方式呼叫。
DIO(DIRECT IO,直接IO),出於對系統cache和排程策略的不滿,使用者自己在應用層定製自己的檔案讀寫。DIO最大的優點就是能夠減少OS核心緩衝區和應用程式地址空間的資料複製次數,降低檔案讀寫時的CPU開銷以及記憶體的佔用。然而DIO的缺陷也很明顯,DIO在資料讀取時會造成磁碟大量的IO,它並沒有緩衝IO從PageCache獲取資料的優勢。
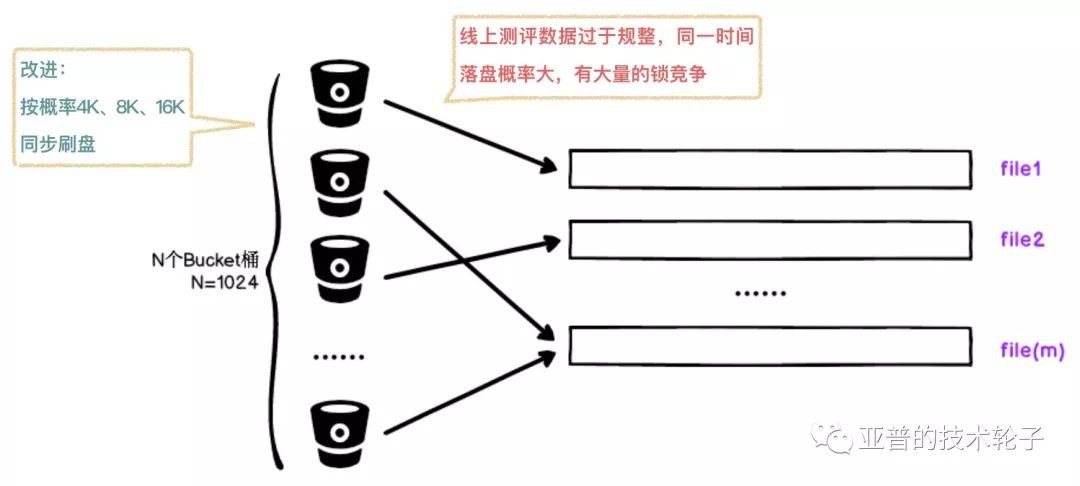
這裡就遇到一個問題,同樣配置的阿裡雲機器測試隨機資料同步寫入效能是非常高的,但是線上的評測資料都是58位元組,資料過於規整導致同一時間落盤的機率很大,出現了大量的鎖競爭。所以這裡做了一個小的改進:按機率隨機4K、8K、16K進行落盤,寫效能雖有一定提升,但是效果也是不太理想,於是採用了第二種思路非同步刷盤。
2. 非同步Flush
採用RingBuffer接收block塊,使用AIO對多個block塊進行Batch刷盤,減少IO Copy的次數。非同步刷盤寫效能有了顯著的提升。

以下是非同步Flush的核心程式碼:
while (gWriterThread) {
if (taskQueue->pop(task)) {
writer->mWriting.store(true);
do {
// 使用非同步IO
aiocb *pAiocb = aiocb_list[aio_size++];
memset(pAiocb, 0, sizeof(aiocb));
pAiocb->aio_lio_opcode = LIO_WRITE;
pAiocb->aio_buf = task.mWriteCache.mCache;
pAiocb->aio_nbytes = task.mWriteCache.mSize;
pAiocb->aio_offset = task.mWriteCache.mStartOffset;
pAiocb->aio_fildes = task.mBlockFile->mFd;
pAiocb->aio_sigevent.sigev_value.sival_ptr = task.mBlockFile;
task.mBlockFile->mWriting = true;
if (aio_size >= MAX_AIO_TASK_COUNT) {
break;
}
} while (taskQueue->pop(task));
if (aio_size > 0) {
if (0 != lio_listio(LIO_WAIT, aiocb_list, aio_size, NULL)) {
aos_fatal_log("aio error %d %s.", errno, strerror(errno));
}
for (int i = 0; i ((BlockFile *) aiocb_list[i]->aio_sigevent.sigev_value.sival_ptr)->mWriting = false;
free((void *) aiocb_list[i]->aio_buf);
}
aio_size = 0;
}
} else {
++waitCount;
sched_yield();
if (waitCount > 100000) {
usleep(10000);
}
}
}
讀快取設計
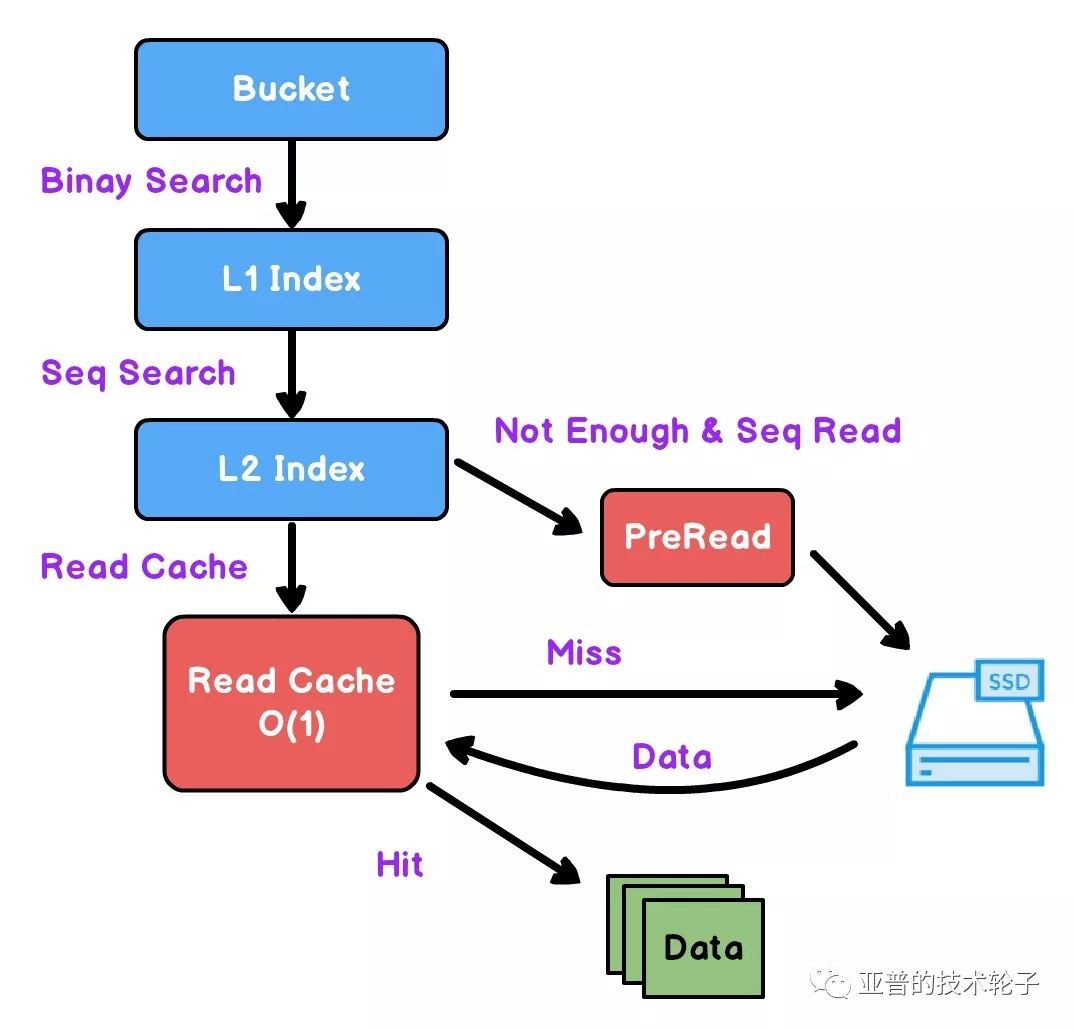
資料讀取流程
-
根據佇列Hash定位Bucket桶。
-
二分查詢定位L1索引和L2索引。
-
在一定時機會執行預讀取操作。
-
資料先從快取中做查詢,快取命中直接傳回,失效則回源到SSD。
整個流程主要有兩個最佳化點:預讀取和讀快取。
預讀取最佳化
1. 記錄上一次讀取(消費)的offset
主要有兩個作用:
-
加快查詢資料的速度。
-
用於判斷預讀取時機。
2. 預讀取時機
順序消費且已經消費到當前block尾,則進行預讀取操作。如何判斷順序消費?判斷上次消費的結束位置是否與這次消費的起始位置相等。
if (msgCount >= destCount) {
if (mLastGetSequeneNum == offsetCount &&
beginIndex + 1 beginOffsetCount + blockIndex.mMsgDeltaIndexCount <= offsetCount + msgCount + msgCount) {
MessageBlockIndex &nextIndex; = mL2IndexArray[beginIndex + 1];
// 預讀取
#ifdef __linux__
readahead(pManager->GetFd(hash), nextIndex.mFileOffset, PER_BLOCK_SIZE);
#endif
}
mLastGetSequeneNum = offsetCount + msgCount;
return msgCount;
}
Read Cache
關於read cache做了一些精巧的小設計,保證足夠簡單高效。
-
分桶(部分隔離),一定程度緩解快取餓死現象。 -
陣列 + 自旋鎖 + 原子變數實現了一個迴圈分配快取塊的方案。 -
雙向指標系結高效定位快取節點。
1. Read Cache全貌
Read Cache一共分為N=64(可配)個Bucket,每個Bucket中包含M=3200(可配)個快取塊,大概總計20w左右的快取塊,每個是4k,大約佔用800M的記憶體空間。

2. 核心資料結構

關於快取的核心資料結構,我們並沒有從佇列的角度出發,而是針對L2索引和快取塊進行了系結,這裡設計了一個雙向指標。判斷快取是否有效的核心思路:check雙向指標是否相等。
CacheItem cachedItem = (CacheItem *) index->mCache;
cachedItem->mIndexPtr == (void *) index;
3. 演演算法實現
3.1 Bucket分桶
-
獲取L2 Index。
-
根據Manager Hash % N,找到對應的快取Bucket。
-
L2還沒有對應快取塊,需要進行快取塊分配。

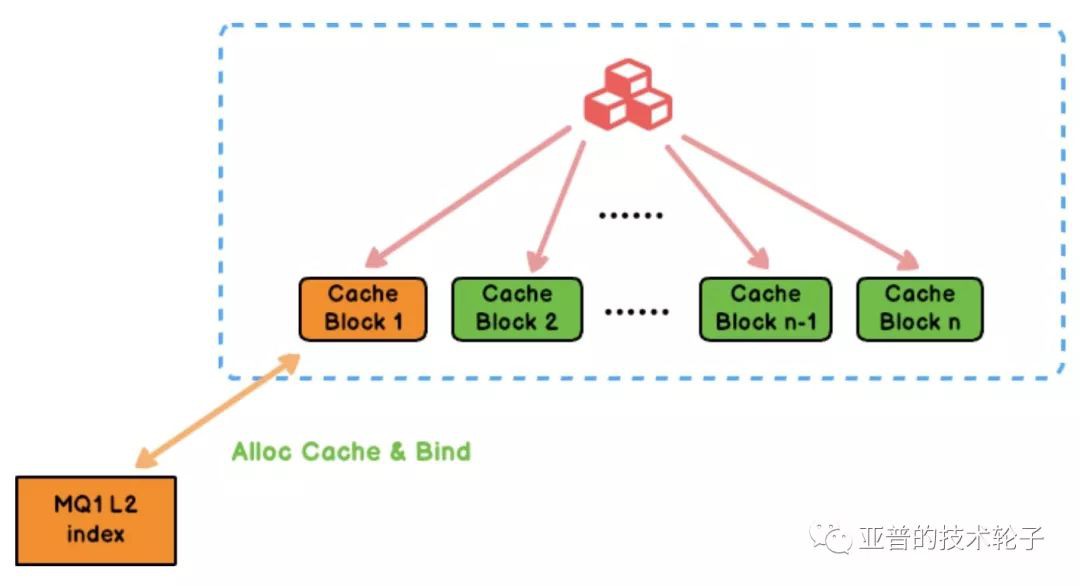
3.2 Alloc Cache Block
-
原子變數進行自加操作,同時對M=3200塊取模,
count.fetch_add(1) % M = index -
分配下標為index的Cache Block。
-
然後將對應的快取塊和我們的佇列的L2索引進行雙向指標系結,同時對快取塊資料進行資料填充。
3.3 Cache Hit
-
index->mCache == index->mCache->index,雙向指標相等,快取命中,然後做資料讀取。
3.4 Cache Page Replace
-
MQ1系結的快取塊已經被MQ2替換。
-
index->mCache != index->mCache->index,雙向指標已經不相等,快取失效。需要為MQ1分配新的快取塊。

-
原子變數進行自加操作,同時對M=3200塊取模, 例如:
count.fetch_add(1) % M = M-1,找到新的快取塊進行重新系結。說明:整個分配的邏輯是一個迴圈使用的過程,當所有的快取桶都被使用,那麼會從陣列首地址開始重新分配、替換。

4. Read Cache & LRU & PageCache 對比
開始我們嘗試了兩種讀快取方案:最簡單的LRU快取和直接使用PageCache讀取。PageCache所實現的其實是高階版的LRU快取。在順序讀的場景下,我們自己實現的讀快取(Cycle Cache Allocate,暫簡稱為CCA)與LRU、PageCache的優劣分析對比如下:
-
LRU針對每次操作進行調整,CCA針對快取塊需要分配時進行替換。
-
LRU從佇列角度建立對映表,CCA針對索引和快取塊雙向指標系結。
-
CCA中自旋鎖是針對每個快取塊加鎖,鎖粒度更小。LRU需要對整個連結串列加鎖。
-
達到同等命中率的情況下,CCA比Page Cache節省至少1~2倍的記憶體。
總結
創新點
-
針對百萬小佇列,實際硬體資源,兼顧讀寫效能,提出
多佇列Merge,保證佇列區域性連續的儲存方式。 -
針對佇列相對無關性及MQ連續讀取的場景,設計實現了O(1)的Read Cache,只需要約800M記憶體即可支援20W佇列的高效率的讀取,命中率高達85%。
-
支援多佇列Merge的索引儲存方案,
資源利用率低,約300~400MB索引即可支撐百萬佇列、100GB資料量高併發讀寫。
工程價值:
-
通用性、隨機性、健壯性較好,支援對任意佇列進行merge。
-
較少出現單佇列訊息太少而導致block塊未刷盤的情況,塊的填充會比較均勻。
-
不必等待單個佇列滿而進行批次刷盤,減少記憶體佔用,更多的記憶體可支援更多的佇列。
-
可以讀寫同步進行,常駐記憶體的索引結構也適合落盤,應對機器重啟、持久化等場景。
思考
-
為什麼沒有使用mmap?為什麼mmap寫入會出現卡頓?
-
如果你對 Dubbo 感興趣,歡迎加入我的知識星球一起交流。

目前在知識星球(https://t.zsxq.com/2VbiaEu)更新瞭如下 Dubbo 原始碼解析如下:
01. 除錯環境搭建
02. 專案結構一覽
03. 配置 Configuration
04. 核心流程一覽
05. 拓展機制 SPI
06. 執行緒池
07. 服務暴露 Export
08. 服務取用 Refer
09. 註冊中心 Registry
10. 動態編譯 Compile
11. 動態代理 Proxy
12. 服務呼叫 Invoke
13. 呼叫特性
14. 過濾器 Filter
15. NIO 伺服器
16. P2P 伺服器
17. HTTP 伺服器
18. 序列化 Serialization
19. 叢集容錯 Cluster
20. 優雅停機
21. 日誌適配
22. 狀態檢查
23. 監控中心 Monitor
24. 管理中心 Admin
25. 運維命令 QOS
26. 鏈路追蹤 Tracing
…
一共 60 篇++