宣告:本文翻譯自Conceptual Architecture of the Linux Kernel
摘要
Linux kernel成功的兩個原因:(1)靈活的架構設計使得大量的志願開發者能夠很容易加入到開發過程中;(2)每個子系統(尤其是那些需要改進的)都具備良好的可擴充套件性。正是這兩個原因使得Linux kernel可以不斷進化和改進。
一、Linux核心在整個計算機系統中的位置

分層結構的原則:the dependencies between subsystems are from the top down: layers pictured near the top depend on lower layers, but subsystems nearer the bottom do not depend on higher layers.
這種子系統之間的依賴性只能是從上到下,也就是在上圖中位於頂層的子系統依賴位於底層的子系統,反之則不行。
二、內核的作用
-
虛擬化(抽象),將計算機硬體抽象為一臺虛擬機器,供使用者行程(process)使用;行程執行時完全不需要知道硬體是如何工作的,只要呼叫Linux kernel提供的虛擬介面(virtual interface)即可。
-
多工處理,實際上是多個任務在並行使用計算機硬體資源,內核的任務是仲裁對資源的使用,製造每個行程都以為自己是獨佔系統的錯覺。
PS:行程背景關係切換就是要換掉程式狀態字、換掉頁表基地址暫存器的內容、換掉current指向的taskstruct實體、換掉PC——>也就換掉了行程開啟的檔案(透過taskstruct的files可以找到)、換掉了行程記憶體的執行空間(透過task_struct的mem可以找到);
三、Linux內核的整體架構
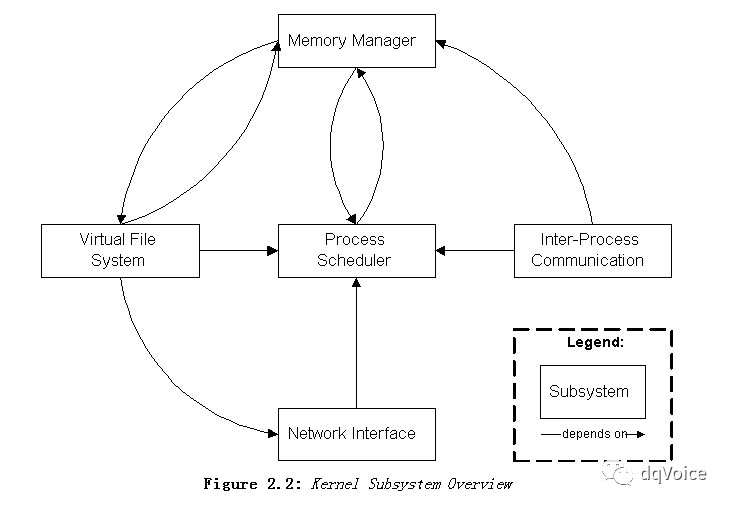
中心繫統是Process Scheduler(SCHED):所有其餘的子系統都依賴於Process Scheduler,因為其餘子系統都需要阻塞和恢復行程。當一個行程需要等待一個硬體動作完成時,相應子系統會阻塞這個行程;當這個硬體動作完成時,子系統會將這個行程恢復:這個阻塞和恢復動作都要依賴於Processor Scheduler完成。
上圖中的每一個依賴箭頭都有原因:
-
Process Scheduler依賴Memory manager:行程恢復執行時,需要依靠Memory Manager分配供它執行的記憶體。
-
IPC子系統依賴於Memory manager:共享記憶體機制是行程間通訊的一種方法,執行兩個行程利用同一塊共享的記憶體空間進行資訊傳遞。
-
VFS依賴於Network Interface:支援NFS網路檔案系統;
-
VFS依賴於Memory Manager:支援ramdisk 裝置
-
memory manager依賴於VFS,因為要支援swapping,可以將暫時不執行的行程換出到磁碟上的swap分割槽,進入掛起狀態。
四、高度模組化設計的系統,利於分工合作
-
只有極少數的程式員需要橫跨多個模組開展工作,這種情況確實會發生,僅發生在當前系統需要依賴另一個子系統時;
-
硬體裝置驅動(hardware device drivers)、檔案系統模組(logical filesystem modules)、網路裝置驅動(network device drivers)和網路協議模組(network protocol modules)這四個模組的可擴充套件性最高。
五、系統中的資料結構
-
Task List Process Scheduler 針對每個行程維護一個資料結構task_struct;所有的行程用連結串列管理,形成task list;process scheduler還維護一個current指標指向當前正在佔用CPU的行程。
-
Memory Map Memory Manager儲存每個行程的虛擬地址到物理地址的對映;並且也提供瞭如何換出特定的頁,或者是如何進行缺頁處理。這些資訊存放在資料結構mmstruct中。每個行程都有一個mmstruct結構,在行程的taskstruct結構中有一個指標mm指向次行程的mmstruct結構。 在mm_struct中有一個指標pgd,指向該行程的頁目錄表(即存放頁目錄首地址)——>當該行程被排程時,此指標被換成物理地址,寫入控制暫存器CR3(x86體系結構下的頁基址暫存器)
-
I-nodes VFS透過inodes節點表示磁碟上的檔案映象,inodes用於記錄檔案的物理屬性。每個行程都有一個filesstruct結構,用於表示該行程開啟的檔案,在taskstruct中有個files指標。使用inodes節點可以實現檔案共享。檔案共享有兩種方式:(1)透過同一個系統開啟檔案file指向同一個inodes節點,這種情況發生於父子行程間;(2)透過不同系統開啟檔案指向同一個inode節點,舉例有硬連結;或者是兩個不相關的指標開啟同一個檔案。
-
Data Connection 核心中所有的資料結構的根都在Process Scheduler維護的task list連結串列中。系統中每個行程的的資料結構task_struct中有一個指標mm指向它的記憶體對映資訊;也有一個指標files指向它開啟的檔案(使用者開啟檔案表);還有一個指標指向該行程開啟的網路套接字。
六、子系統架構
1. Process Scheduler 架構
(1)標的
process scheduler是Linux kernel中最重要的子系統。系統透過它來控制對CPU的訪問——不僅僅是使用者行程對CPU的訪問,也包括其餘子系統對CPU的訪問。
(2)模組
 排程策略模組(scheduling policy module):決定哪個行程獲得對CPU的訪問權;排程策略應該讓所有行程盡可能公平得共享CPU。
排程策略模組(scheduling policy module):決定哪個行程獲得對CPU的訪問權;排程策略應該讓所有行程盡可能公平得共享CPU。
-
體系結構相關模組(architecture-specific module)設計一組統一的抽象介面來遮蔽特定體系介面晶片的硬體細節。這個模組與CPU互動以阻塞和恢復行程。這些操作包括獲取每個行程需要儲存的暫存器和狀態資訊、執行彙編程式碼來完成阻塞或者恢復操作。
-
體系結構無關模組(architecture-independent module) 與排程策略模組互動將決定下一個執行的行程,然後呼叫體系結構相關的程式碼去恢復那個行程的執行。不僅如此,這個模組還會呼叫memory manager的介面來確保被阻塞的行程的記憶體對映資訊被正確得儲存起來。
-
系統呼叫介面模組(system call interface) 允許使用者行程訪問Linux Kernel明確暴露給使用者行程的資源。透過一組定義合適的基本上不變的介面(POSIX標準),將使用者應用程式和Linux內核解耦,使得使用者行程不會受到核心變化的影響。
(3)資料表示
排程器維護一個資料結構——task list,其中的元素時每個活動的行程task_struct實體;這個資料結構不僅僅包含用來阻塞和恢復行程的資訊,也包含額外的計數和狀態資訊。這個資料結構在整個kernel層都可以公共訪問。
(4)依賴關係、資料流、控制流
正如前面提到過的,排程器需要呼叫memory manager提供的功能,去為需要恢復執行的行程選擇合適的物理地址,正因為如此,所以Process Scheuler子系統依賴於記憶體管理子系統。當其他內核子系統需要等待硬體請求完成時,它們都依賴於行程排程子系統進行行程的阻塞和恢復。這種依賴性透過函式呼叫和訪問共享的task list資料結構來體現。所有的內核子系統都要讀或者寫代表當前正在執行行程的資料結構,因此形成了貫穿整個系統的雙向資料流。
除了核心層的資料流和控制流,OS服務層還給使用者行程提供註冊定時器的介面。這形成了由排程器對使用者行程的控制流。通常喚醒睡眠行程的用例不在正常的控制流範圍,因為使用者行程無法預知何時被喚醒。最後,排程器與CPU互動來阻塞和恢復行程,這又形成它們之間的資料流和控制流——CPU負責打斷當前正在執行的行程,並允許核心排程其他的行程執行。
2. Memory Manager 架構
(1)標的
記憶體管理模組負責控制行程如何訪問物理記憶體資源。透過硬體記憶體管理系統(MMU)管理行程虛擬記憶體和機器物理記憶體之間的對映。每一個行程都有自己獨立的虛擬記憶體空間,所以兩個行程可能有相同的虛擬地址,但是它們實際上在不同的物理記憶體區域執行。MMU提供記憶體保護,讓兩個行程的物理記憶體空間不互相干擾。記憶體管理模組還支援swap——將暫時不用的記憶體頁換出到磁碟上的swap分割槽,這種技術讓行程的虛擬地址空間大於物理記憶體的大小。虛擬地址空間的大小由機器字長決定。
(2)模組
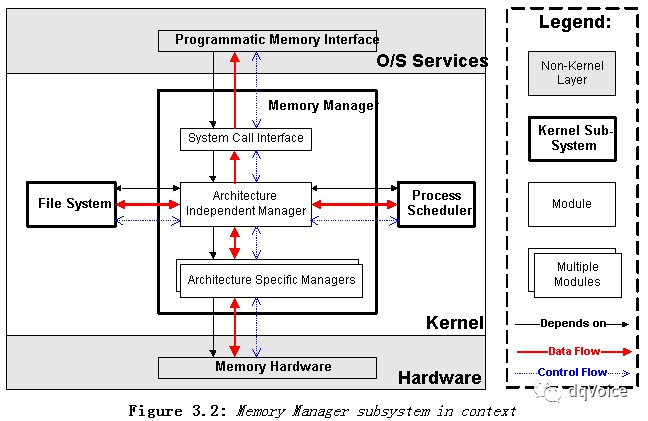
-
架構相關模組(architecture specific module)提供訪問物理記憶體的虛擬介面;
-
架構無關模組(architecture independent module)負責每個行程的地址對映以及虛擬記憶體交換。當發生缺頁錯誤時,由該模組負責決定哪個記憶體頁應該被換出記憶體——因為這個記憶體頁換出選擇演演算法幾乎不需要改動,所以這裡沒有建立一個獨立的策略模組。
-
系統呼叫介面(system call interface) 為使用者行程提供嚴格的訪問介面(malloc和free;mmap和ummap)。這個模組允許用行程分配和釋放記憶體、執行記憶體對映檔案操作。
(3)資料表示
記憶體管理存放每個行程的虛擬記憶體到物理記憶體的對映資訊。這種對映資訊存放在mmstruct結構實體中,這個實體的指標又存放在每個行程的taskstruct中。除了存放對映資訊,資料塊中還應該存放關於記憶體管理器如何獲取和儲存頁的資訊。例如:可執行程式碼能夠將可執行映象作為備份儲存;但是動態申請的資料則必須備份到系統頁中。(這個沒看懂,請高手解惑?)
最後,記憶體管理模組還應該存放訪問和技術資訊,以保證系統的安全。
(4)依賴關係、資料流和控制流
記憶體管理器控制物理記憶體,當page fault發生時,接受硬體的通知(缺頁中斷)—— 這意味著在記憶體管理模組和記憶體管理硬體之間存在雙向的資料流和控制流。記憶體管理也依賴檔案系統來支援swapping和記憶體對映I/O——這種需求意味著記憶體管理器需要呼叫對檔案系統提供的函式介面(procedure calls),往磁碟中存放記憶體頁和從磁碟中取記憶體頁。因為檔案系統請求非常慢,所以在等待記憶體頁被換入之前,記憶體管理器要讓行程需要進入休眠——這種需求讓記憶體管理器呼叫process scheduler的介面。由於每個行程的記憶體對映存放在行程排程器的資料結構中,所以在記憶體管理器和行程排程器之間也有雙向的資料流和控制流。使用者行程可以建立新的行程地址空間,並且能夠感知缺頁錯誤——這裡需要來自記憶體管理器的控制流。一般來說沒有使用者行程到記憶體管理器的資料流,但是使用者行程卻可以透過select系統呼叫,從記憶體管理器獲取一些資訊。
3. Virtual File System 架構
(1)標的
虛擬檔案系統為儲存在硬體裝置上資料提供統一的訪問介面。可以相容不同的檔案系統(ext2,ext4,ntf等等)。計算機中幾乎所有的硬體裝置都被表示為一個通用的裝置驅動介面。邏輯檔案系統促進與其他作業系統標準的相容性,並且允許開發者以不同的策略實現檔案系統。虛擬檔案系統更進一步,允許系統管理員在任何裝置上掛載任何邏輯檔案系統。虛擬檔案系統封裝物理裝置和邏輯檔案系統的細節,並且允許使用者行程使用統一的介面訪問檔案。
除了傳統的檔案系統標的,VFS也負責裝載新的可執行檔案。這個任務由邏輯檔案系統模組完成,使得Linux可以支援多種可執行檔案。
(2)模組
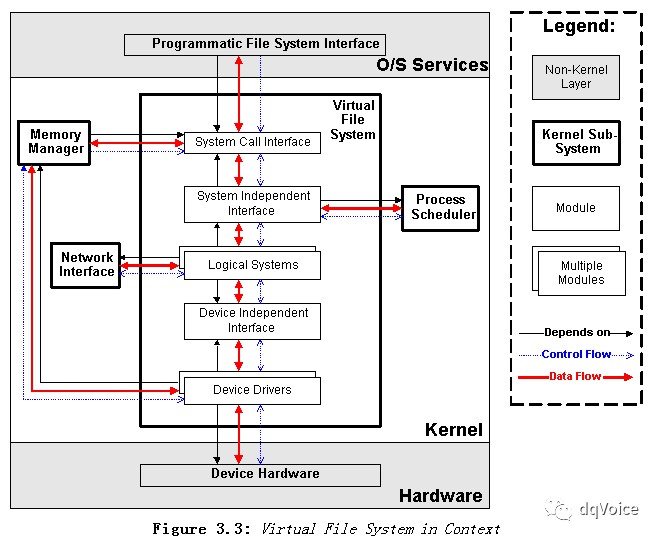
-
裝置驅動模組(device driver module)
-
裝置獨立介面模組(Device Independent Interface):提供所有裝置的同一檢視
-
邏輯檔案系統(logical file system):針對每種支援的檔案系統
-
系統獨立介面(system independent interface)提供硬體資源和邏輯檔案系統都無關的介面,這個模組透過塊裝置節點或者字元裝置節點提供所有的資源。
-
系統呼叫模組(system call interface)提供使用者行程對檔案系統的統一控制訪問。虛擬檔案系統為使用者行程遮蔽了所有特殊的特性。
(3)資料表示
所有檔案使用i-nodes表示。每個inode都記錄一個檔案在硬體裝置上的位置資訊。不僅如此,inode還存放著指向邏輯檔案系統模組和裝置驅動的的函式指標,這些指標能夠執行具體的讀寫操作。透過按照這種形式(就是面向物件中的虛函式的思想)存放函式指標,具體的邏輯檔案系統和裝置驅動可以向內核註冊自己而不需要核心依賴具體的模組特性。
(4)依賴關係、資料流和控制流
一個特殊的裝置驅動是ramdisk,這個裝置在主存中開闢一片區域,並把它當成永續性儲存裝置使用。這個裝置驅動使用記憶體管理模組完成任務,所以在VFS與對記憶體管理模組存在依賴關係(圖中的依賴關係反了,應該是VFS依賴於記憶體管理模組)、資料流和控制流。
邏輯檔案系統支援網路檔案系統。這個檔案系統像訪問本地檔案一樣,從另一臺機器上訪問檔案。為了實現這個功能,一種邏輯檔案系統透過網路子系統完成它的任務——這引入了VFS對網路子系統的一個依賴關係以及它們之間的控制流和資料流。
正如前面提到的,記憶體管理器使用VFS完成記憶體swap功能和記憶體對映I/O。另外,當VFS等待硬體請求完成時,VFS需要使用行程排程器阻塞行程;當請求完成時,VFS需要透過行程排程器喚醒行程。最後,系統呼叫介面允許使用者行程呼叫來存取資料。不像前面的子系統,VFS沒有提供給使用者註冊不明確呼叫的機制,所以沒有從VFS到使用者行程的控制流。
4. Network Interface 架構
(1)標的
網路子系統讓Linux系統能夠透過網路與其他系統相連。這個子系統支援很多硬體裝置,也支援很多網路協議。網路子系統將硬體和協議的實現細節都遮蔽掉,並抽象出簡單易用的介面供使用者行程和其他子系統使用——使用者行程和其餘子系統不需要知道硬體裝置和協議的細節。
(2)模組

-
網路裝置驅動模組(network device drivers)
-
裝置獨立介面模組(device independent interface module)提供所有硬體裝置的一致訪問介面,使得高層子系統不需要知道硬體的細節資訊。
-
網路協議模組(network protocol modules)負責實現每一個網路傳輸協議,例如:TCP,UDP,IP,HTTP,ARP等等~
-
協議無關模組(protocol independent interface)提供獨立於具體協議和具體硬體裝置的一致性介面。這使得其餘內核子系統無需依賴特定的協議或者裝置就能訪問網路。
-
系統呼叫介面模組(system calls interface)規定了使用者行程可以訪問的網路程式設計API
(3)資料表示
每個網路物件都被表示為一個套接字(socket)。套接字與行程關聯的方法和i-nodes節點相同。透過兩個task_struct指向同一個套接字,套接字可以被多個行程共享。
(4)資料流,控制流和依賴關係
當網路子系統需要等待硬體請求完成時,它需要透過行程排程系統將行程阻塞和喚醒——這形成了網路子系統和行程排程子系統之間的控制流和資料流。不僅如此,虛擬檔案系統透過網路子系統實現網路檔案系統(NFS)——這形成了VFS和網路子系統指甲的資料流和控制流。
七、結論
1、Linux內核是整個Linux系統中的一層。核心從概念上由五個主要的子系統構成:行程排程器模組、記憶體管理模組、虛擬檔案系統、網路介面模組和行程間通訊模組。這些模組之間透過函式呼叫和共享資料結構進行資料互動。、
2、Linux核心架構促進了他的成功,這種架構使得大量的志願開發人員可以合適得分工合作,並且使得各個特定的模組便於擴充套件。
-
可擴充套件性一:Linux架構透過一項資料抽象技術使得這些子系統成為可擴充套件的——每個具體的硬體裝置驅動都實現為單獨的模組,該模組支援核心提供的統一的介面。透過這種方式,個人開發者只需要和其他核心開發者做最少的互動,就可以為Linux核心新增新的裝置驅動。
-
可擴充套件性二:Linux核心支援多種不同的體系結構。在每個子系統中,都將體系結構相關的程式碼分割出來,形成單獨的模組。透過這種方法,一些廠家在推出他們自己的晶片時,他們的核心開發小組只需要重新實現核心中機器相關的程式碼,就可以講核心移植到新的晶片上執行。
參考文章:
-
http://oss.org.cn/ossdocs/linux/kernel/a1/index.html
-
http://www.cs.cmu.edu/afs/cs/project/able/www/paperabstracts/introsoftarch.html
-
http://www.fceia.unr.edu.ar/ingsoft/monroe00.pdf
-
核心原始碼:http://lxr.oss.org.cn/