
作者丨知乎DeAlVe
學校丨某211碩士生
研究方向丨樣式識別與機器學習
介紹
主成分分析(PCA)和自編碼器(AutoEncoders, AE)是無監督學習中的兩種代表性方法。
PCA 的地位不必多說,只要是講到降維的書,一定會把 PCA 放到最前面,它與 LDA 同為機器學習中最基礎的線性降維演演算法,SVM/Logistic Regression、PCA/LDA 也是最常被拿來作比較的兩組演演算法。
自編碼器雖然不像 PCA 那般在教科書上隨處可見,但是在早期被拿來做深度網路的逐層預訓練,其地位可見一斑。儘管在 ReLU、Dropout 等神器出現之後,人們不再使用 AutoEncoders 來預訓練,但它延伸出的稀疏 AutoEncoders,降噪 AutoEncoders 等仍然被廣泛用於表示學習。2017 年 Kaggle 比賽 Porto Seguro’s Safe Driver Prediction 的冠軍就是使用了降噪 AutoEncoders 來做表示學習,最終以絕對優勢擊敗了手工特徵工程的選手們。
PCA 和 AutoEncoders 都是非機率的方法,它們分別有一種對應的機率形式叫做機率 PCA (Probabilistic PCA) 和變分自編碼器(Variational AE, VAE),本文的主要目的就是整理一下 PCA、機率 PCA、AutoEncoders、變分 AutoEncoders 這四者的關係。
先放結論,後面就圍繞這個表格展開:

降維的線性方法和非線性方法
降維分為線性降維和非線性降維,這是最普遍的分類方法。
PCA 和 LDA 是最常見的線性降維方法,它們按照某種準則為資料集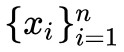 找到一個最優投影方向 W 和截距 b,然後做變換
找到一個最優投影方向 W 和截距 b,然後做變換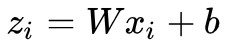 得到降維後的資料集
得到降維後的資料集 。因為是一個線性變換(嚴格來說叫仿射變換,因為有截距項),所以這兩種方法叫做線性降維。
。因為是一個線性變換(嚴格來說叫仿射變換,因為有截距項),所以這兩種方法叫做線性降維。
非線性降維的兩類代表方法是流形降維和 AutoEncoders,這兩類方法也體現出了兩種不同角度的“非線性”。流形方法的非線性體現在它認為資料分佈在一個低維流形上,而流形本身就是非線性的,流形降維的代表方法是兩篇 2000 年的 Science 論文提出的:多維放縮(multidimensional scaling, MDS)和區域性線性嵌入(locally linear embedding, LLE)。不得不說實在太巧了,兩種流形方法發表在同一年的 Science 上。
AutoEncoders 的非線性和神經網路的非線性是一回事,都是利用堆疊非線性啟用函式來近似任意函式。事實上,AutoEncoders 就是一種神經網路,只不過它的輸入和輸出相同,真正有意義的地方不在於網路的輸出,而是在於網路的權重。
降維的生成式方法和非生成式方法
兩類方法
降維還可以分為生成式方法(機率方法)接非生成式方法(非機率方法)。
教科書對 PCA 的推導一般是基於最小化重建誤差或者最大化可分性的,或者說是透過提取資料集的結構資訊來建模一個約束最最佳化問題來推導的。事實上,PCA 還有一種機率形式的推導,那就是機率 PCA,PRML 裡面有對機率 PCA 的詳細講解,感興趣的讀者可以去閱讀。需要註意的是,機率 PCA 不是 PCA 的變體,它就是 PCA 本身,機率 PCA 是從另一種角度來推導和理解 PCA,它把 PCA 納入了生成式的框架。
設是我們拿到的資料集,我們的目的是得到資料集中每個樣本的低維表示,其中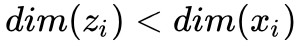 。
。
降維的非生成式方法不需要機率知識,而是直接利用資料集的結構資訊建模一個最最佳化問題,然後求解這個問題得到對應的。
降維的生成式方法認為資料集是對一個隨機變數 x 的 n 次取樣,而隨機變數 x 依賴於隨機變數 z ,對 z 進行建模:

再對這個依賴關係進行建模:
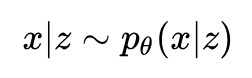
有了這兩個公式,我們就可以表達出隨機變數 x 的分佈:

隨後我們利用資料集對分佈的引數 θ 進行估計,就得到這幾個分佈。好了,設定了這麼多,可是降維降在哪裡了呢,為什麼沒有看到?
回想一下降維的定義:降維就是給定一個高維樣本 xi ,給出對應的低維表示 zi ,這恰好就是 p(z|x) 的含義。所以我們只要應用 Bayes 定理求出這個機率即可:

這樣我們就可以得到每個樣本點 xi 上的 z 的分佈 p(z|x=xi) ,可以選擇這個分佈的峰值點作為 zi,降維就完成了。
Q:那麼問題來了,生成式方法和非生成式方法哪個好呢?
A:當然是非生成式方法好了,一兩行就能設定完,君不見生成式方法你設定了一大段?
應該會有很多人這樣想吧?事實也的確如此,上面這個回答在一定意義上是正確的。如果你只是為了對現有的資料進行降維,而沒有其他需求,那麼簡單粗暴的非生成式方法當然是更好的選擇。
那麼,在什麼情況下,或者說什麼需求下,生成式方法是更好的選擇更好呢?答案就蘊含在“生成式”這個名稱中:在需要生成新樣本的情況下,生成式方法是更好的選擇。
生成式方法的應用場景
相似圖片生成就是一種最常見的應用場景,現在我們考慮生成 MNIST 風格的手寫體數字。假設 xi 代表一張圖片,是整個 MNIST 資料集,我們該怎樣建模才能生成一張新圖片呢?
最容易想到的方法就是:對進行 KDE(核密度估計)得到 x 的分佈 p(x),如果順利的話 p(x) 應該是一個 10 峰分佈,一個峰代表一個數字,從對應的峰中取樣一個樣本 ,它就代表了相應的數字。
,它就代表了相應的數字。
是不是看起來很簡單,然而 x 的維度太高(等於 MNIST 的解析度, 28×28=784 ),每一維中包含的資訊又十分有限,直接對進行 KDE 完全沒有可行性,所以更好的方法是先對資料集進行降維得到,然後再對進行 KDE,再從 p(z) 中取樣 並透過逆變換得到
並透過逆變換得到![]() 。
。
這樣做當然也是可以的,但是依然存在嚴重的問題。上面的方法相當於把新樣本生成拆分成了降維、KDE 和取樣這三個步驟。降維這一步驟可以使用 PCA 或者 AutoEncoders 等方法,這一步不會有什麼問題。
存在嚴重問題的步驟是 KDE 和取樣。回想一下 KDE 其實是一種懶惰學習方法,每來一個樣本 x ,它就會計算一下這個樣本和資料集中每一個樣本 xi 的核距離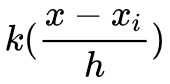 ,然後估計出這一點的密度。
,然後估計出這一點的密度。
這就意味著我們需要把 z 所屬的空間劃分成網格,估計每個網格點上的密度,才能近似得到 p(z) ,計算複雜度是 O(n*grid_scale),而 grid_scale 關於 z 的維數是指數級的,這個計算複雜度是十分恐怖的。即使得到了近似的 p(z) ,從這樣一個沒有解析形式的分佈中取樣也是很困難的,依然只能求助於網格點近似。因此,KDE 和取樣這兩步無論是計算效率還是計算精度都十分堪憂。
這時候就要求助於生成式方法了。註意到生成式方法中建模了 pθ(z) 和 pθ(x|z),一旦求出了引數 θ,我們就得到了變數 z 的解析形式的分佈。只要從 pθ(z) 中取樣出一個![]() ,再取
,再取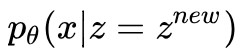 的峰值作為我們的
的峰值作為我們的![]() ,新樣本生成就完成了。
,新樣本生成就完成了。
在需要生成新樣本時,非生成式方法需要對 z 的機率分佈進行代價巨大的數值逼近,然後才能從分佈中取樣;生成式方法本身就對 z 的機率分佈進行了建模,因此可以直接從分佈中進行取樣。所以,在需要生成新樣本時,生成式方法是更好的選擇,甚至是必然的選擇。
機率PCA和變分AutoEncoders
下麵簡單整理一下這四種降維方法。註意一些術語,編碼=降維,解碼=重建,原資料=觀測變數,降維後的資料=隱變數。
PCA
原資料:

編碼後的資料:

解碼後的資料:
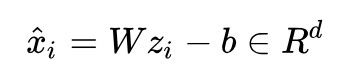
重建誤差:

最小化重建誤差,就可以得到 W 和 b 的最優解和解析解,PCA 的求解就完成了。
補充說明:
PCA 中的 p=2 ,即最小化二範數意義下的重建誤差,如果 p=1 的話我們就得到了魯棒 PCA (Robust PCA)。而最小化誤差的二範數等價於對高斯噪聲的 MLE,最小化誤差的一範數等價於對拉普拉斯噪聲的 MLE。
因此,PCA 其實是在假設存在高斯噪聲的條件下對資料集進行重建,這個高斯誤差就是我們將要在下麵機率 PCA 一節中提到的 ϵ。你看,即使不是機率 PCA,其中也隱含著機率的思想。
編碼和解碼用到的 W 和 b 是一樣的,即編碼過程和解碼過程是對稱的,這一點與下麵要講的 AutoEncoders 是不同的。
求解上述最最佳化問題可以得到 ,這恰好是樣本均值的相反數。也就是說,PCA 中截距項的含義是讓每個樣本都減去樣本均值,這正是“樣本中心化”的含義。
,這恰好是樣本均值的相反數。也就是說,PCA 中截距項的含義是讓每個樣本都減去樣本均值,這正是“樣本中心化”的含義。
既然我們已經知道求出來的截距就是樣本均值,所以乾脆一開始就對樣本進行中心化,這樣在使用 PCA 的時候就可以忽略截距項 b 而直接使用 ,變數就只剩下 W 了。教科書上講解 PCA 時一般都是上來就說“使用 PCA 之前需要進行樣本中心化”,但是沒有人告訴我們為什麼要這樣做,現在大家應該明白為什麼要進行中心化了吧。
,變數就只剩下 W 了。教科書上講解 PCA 時一般都是上來就說“使用 PCA 之前需要進行樣本中心化”,但是沒有人告訴我們為什麼要這樣做,現在大家應該明白為什麼要進行中心化了吧。
AutoEncoders
原資料:

編碼後的資料:

解碼後的資料:

重建誤差:

最小化重建誤差,利用反向傳播演演算法可以得到 的區域性最優解&數值解,AutoEncoders 的求解完成。
的區域性最優解&數值解,AutoEncoders 的求解完成。
補充說明: 這裡可以使用任意範數,每一個範數都代表我們對資料的一種不同的假設。為了和 PCA 對應,我們也取 p=2。
σ(·) 是非線性啟用函式。AutoEncoder 一般都會堆疊多層,方便起見我們只寫了一層。
W 和![]() 完全不是一個東西,這是因為經過非線性變換之後我們已經無法將樣本再用原來的基 W 進行表示了,必須要重新訓練解碼的基
完全不是一個東西,這是因為經過非線性變換之後我們已經無法將樣本再用原來的基 W 進行表示了,必須要重新訓練解碼的基![]() 。甚至,AutoEncoders 的編碼器和解碼器堆疊的層數都可以不同,例如可以用 4 層來編碼,用 3 層來解碼。
。甚至,AutoEncoders 的編碼器和解碼器堆疊的層數都可以不同,例如可以用 4 層來編碼,用 3 層來解碼。
機率PCA
隱變數邊緣分佈:

觀測變數條件分佈:
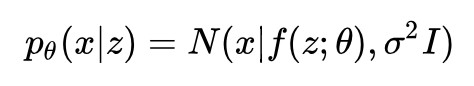
確定函式:

x 的生成過程:

因為 p(z) 和 pθ(x|z) 都是高斯分佈,且 pθ(x|z) 的均值 f(z;θ) = Wz+μ 是 z 的線性函式,所以這是一個線性高斯模型。線性高斯模型有一個非常重要的性質: pθ(x) 和 pθ(z|x) 也都是高斯分佈。千萬不要小瞧這個性質,這個性質保證了我們能夠使用極大似然估計或者EM演演算法來求解PCA。
如果沒有這個性質的話,我們就只能藉助變分法(變分 AE 採用的)或者對抗訓練(GAN 採用的)來近似 pθ(x) 和 pθ(z|x)$ 了。有了這個優秀的性質之後,我們至少有三種方法可以求解機率 PCA:

是一個形式已知,僅引數未知的高斯分佈,因此可以用極大似然估計來求解 θ。

也是一個形式已知,僅引數未知的高斯分佈,因此可以用 EM 演演算法來求解 θ,順便還能得到隱變數 zi 。
如果你足夠無聊,甚至也可以引入一個變分分佈 qΦ(z|x) 來求解機率 PCA,不過似乎沒什麼意義,也算是一種方法吧。
一旦求出了 θ,我們就得到了所有的四個機率:

有了這四個機率,我們就可以做這些事情了:
1. 降維:給定樣本 xi ,就得到了分佈 pθ(z|x=xi) ,取這個分佈的峰值點 zi 就是降維後的資料;
2. 重建:給定降維後的樣本 zi ,就得到了分佈 pθ(x|z=zi),取這個分佈的峰值點 xi 就是重建後的資料;
3. 生成:從分佈 p(z) 中取樣一個,就得到了分佈 ,取這個分佈的峰值點就是新生成的資料;
,取這個分佈的峰值點就是新生成的資料;
4. 密度估計:給定樣本 xi ,就得到了這一點的機率密度 pθ(x=xi) 。
PCA 只能做到 1 和 2,對 3 和 4無力,這一點我們已經分析過了。
Q:為什麼隱變數要取單位高斯分佈(標準正態分佈)?
A:這是兩個問題。
subQ1:為什麼要取高斯分佈?
subA1:為了求解方便,如果不取高斯分佈,那麼 pθ(x) 有很大的可能沒有解析解,這會給求解帶來很大的麻煩。還有一個原因,回想生成新樣本的過程,要首先從 p(z) 中取樣一個![]() ,高斯分佈取樣簡單。
,高斯分佈取樣簡單。
subQ2:為什麼是零均值單位方差的?
subA2:完全可以取任意均值和方差,但是我們要將 p(z) 和 pθ(x|z) 相乘,均值和方差部分可以挪到 f(z;θ) 中,所以 p(z) 的均值和方差取多少都無所謂,方便起見就取單位均值方差了。
Q:pθ(x|z) 為什麼選擇了高斯分佈呢?
A:因為簡單,和上一個問題的一樣。還有一個直覺的解釋是 pθ(x|z) 認為 x 是由 f(z:θ) 和噪聲 ϵ 加和而成的,如果 ϵ 是高斯分佈的話,恰好和 PCA 的二範數重建誤差相對應,這也算是一個佐證吧。
Q:pθ(x|z) 的方差為什麼選擇了各向同性的![]() 而不是更一般的 ∑ 呢?
而不是更一般的 ∑ 呢?
A:方差可以選擇一般的 ∑ ,但是![]() 個引數一定會給求解帶來困難,所匯出的方法雖然也是線性降維,但它已經不是 PCA 了,而是另外的方法(我也不知道是什麼方法)。方差也可以選擇成一個的各向異性的對角陣 λ,這樣只有 d 個引數,事實上這就是因子分析,另一種線性降維方法。只有當方差選擇成各向同性的對角陣
個引數一定會給求解帶來困難,所匯出的方法雖然也是線性降維,但它已經不是 PCA 了,而是另外的方法(我也不知道是什麼方法)。方差也可以選擇成一個的各向異性的對角陣 λ,這樣只有 d 個引數,事實上這就是因子分析,另一種線性降維方法。只有當方差選擇成各向同性的對角陣![]() 時,匯出來的方法才叫主成分分析,這個地方 PRML 裡有介紹。
時,匯出來的方法才叫主成分分析,這個地方 PRML 裡有介紹。
變分AutoEncoders
隱變數邊緣分佈:

觀測變數條件分佈:

確定函式:

x 的生成過程:

因為 f(z;θ) 是 z 的非線性函式,所以這不再是一個線性高斯模型。觀測變數的邊緣分佈:

沒有解析形式。這就意味著我們無法直接使用極大似然估計來求解引數 θ。更加絕望的是,隱變數的後驗分佈:

也沒有解析形式(這是當然,因為分母沒有解析形式了)。這就意味著我們也無法透過 EM 演演算法來估計引數和求解隱變數。
那麼,建出來的模型該怎麼求解呢?這就需要上變分推斷(Variational Inference),又稱變分貝葉斯(Variational Bayes)了。本文不打算細講變分推斷,僅僅講一下大致的流程。
變分推斷會引入一個變分分佈 qΦ(z|x) 來近似沒有解析形式的後驗機率 pθ(z|x) 。在變分 AE 的原文中,作者使用了 SGD 來同時最佳化引數 θ 和 Φ。一旦求出了這兩個引數就可以得到這些機率:

註意因為 pθ(x) 和 pθ(z|x) 沒有解析形式,所以即使求出了 θ 我們也無法獲得這兩個機率。但是,正如上面說的, qΦ(z|x) 就是 pθ(z|x) 的近似,所以需要用pθ(z|x) 的地方都可以用 qΦ(z|x) 代替。
有了這三個機率,我們就可以做這些事情了:
1. 降維:給定樣本 xi ,就得到了分佈 qΦ(z|x=xi) ,取這個分佈的峰值點 zi 就是降維後的資料;
2. 重建:給定降維後的樣本 zi ,就得到了分佈 pθ(x|z=zi),取這個分佈的峰值點 xi 就是重建後的資料;
3. 生成:從分佈 p(z) 中取樣一個,就得到了分佈,取這個分佈的峰值點就是新生成的資料。
與機率 PCA 不同的是,這裡無法解析地得到 pθ(xi) ,進行密度估計需要進行另外的設計,透過取樣得到,計算代價還是比較大的,具體步驟變分 AE 的原文中有介紹。
AutoEncoders 只能做到 1 和 2,對 3 無力。
對比
1. 從 PCA 和 AutoEncoders 這兩節可以看出,PCA 實際上就是線性 Autoencoders。兩者無論是編碼解碼形式還是重建誤差形式都完全一致,只有是否線性的區別。線性與否給最佳化求解帶來了不同性質:PCA 可以直接得到最優的解析解,而 AutoEncoders 只能透過反向傳播得到區域性最優的數值解。
2. 從機率 PCA 和變分 AutoEncoders 這兩節可以看出,機率 PCA 和變分 AutoEncoders 的唯一區別就是 f(z;θ) 是否是 z 的線性函式,但是這個區別給最佳化求解帶來了巨大的影響。在機率 PCA 中,f(z;θ) 是線性的,所以我們得到了一個線性高斯模型,線性高斯模型的優秀性質是牽扯到的 4 個機率都是高斯分佈,所以我們可以直接給出邊緣分佈和編碼分佈的解析形式,極大似然估計和 EM 演演算法都可以使用,一切處理都非常方便。
在變分AutoEncoders中,f(z;θ) 是非線性的,所以邊緣分佈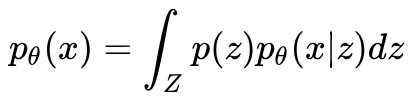 不再有解析形式,極大似然估計無法使用;編碼分佈
不再有解析形式,極大似然估計無法使用;編碼分佈 也不再有解析形式,EM 演演算法無法使用,我們只能求助於變分推斷,得到編碼分佈的近似 qΦ(z|x) ,再利用別的技巧得到邊緣分佈 pθ(x) 的估計。
也不再有解析形式,EM 演演算法無法使用,我們只能求助於變分推斷,得到編碼分佈的近似 qΦ(z|x) ,再利用別的技巧得到邊緣分佈 pθ(x) 的估計。
3. 從 PCA 和機率 PCA 兩小節可以看出,PCA 和機率 PCA 中 x 都是 z 的線性函式,只不過機率 PCA 顯式地把高斯噪聲 ϵ 寫在了運算式中;PCA 沒有顯式寫出噪聲,而是把高斯噪聲隱含在了二範數重建誤差中。
4. 從 AutoEncoders 和變分 AutoEncoders 這兩節可以看出,AE 和 VAE 的最重要的區別在於 VAE 迫使隱變數 z 滿足高斯分佈 p(z)=N(z|0,I) ,而 AE 對 z 的分佈沒有做任何假設。
這個區別使得在生成新樣本時,AE 需要先數值擬合 p(z) ,才能生成符合資料集分佈的隱變數,而 VAE 直接從 N(z|0,I) 中取樣一個 z ,它天然就符合資料集分佈。事實上,這是因為在使用變分推斷進行最佳化時,VAE 迫使 z 的分佈向 N(z|0,I) 靠近,不過本文中沒有講最佳化細節,VAE 的原文中有詳細的解釋。
5. PCA 求解簡單,但是都是線性降維,提取資訊的能力有限;非線性的 AE 提取資訊的能力強,但是求解複雜。要根據不同的場景選擇不同的降維演演算法。
6. 要生成新樣本時,不能選擇 PCA 或 AE,而是要選擇機率 PCA 或 VAE。
總結
本文將降維按照是否線性、是否生成式劃分,將 PCA、機率 PCA、AutoEncoders 和變分 AutoEncoders 納入了這個劃分框架中,並分析了四種演演算法的內在聯絡。

點選以下標題檢視其他相關文章:
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視最新論文推薦
