導語:從一開始的Google搜尋,到現在的聊天機器人、大資料風控、證券投資、智慧醫療、自適應教育、推薦系統,無一不跟知識圖譜相關。它在技術領域的熱度也在逐年上升。 本文以通俗易懂的方式來講解知識圖譜相關的知識、尤其對從零開始搭建知識圖譜過程當中需要經歷的步驟以及每個階段需要考慮的問題都給予了比較詳細的解釋。 對於讀者,我們不要求有任何AI相關的背景知識。
文末有彩蛋:免費公開課《自然語言處理在金融領域中的應用》,本期我們特別邀請了NLP領域專家Sherlock Ho結合一線經驗給大家講述自然語言處理技術在金融領域中的工業級應用。
今天我們將帶你瞭解怎麼一步步搭建可落地的金融風控領域的知識圖譜系統:
首先需要說明的一點是,有可能不少人認為搭建一個知識圖譜系統的重點在於演演算法和開發。但事實並不是想象中的那樣,其實最重要的核心在於對業務的理解以及對知識圖譜本身的設計,這就類似於對於一個業務系統,資料庫表的設計尤其關鍵,而且這種設計絕對離不開對業務的深入理解以及對未來業務場景變化的預估。 當然,在這裡我們先不討論資料的重要性。

一個完整的知識圖譜的構建包含以下幾個步驟:1. 定義具體的業務問題 2. 資料的收集 & 預處理 3. 知識圖譜的設計 4. 把資料存入知識圖譜 5. 上層應用的開發,以及系統的評估。下麵我們就按照這個流程來講一下每個步驟所需要做的事情以及需要思考的問題。
1 定義具體的業務問題
在P2P網貸環境下,最核心的問題是風控,也就是怎麼去評估一個借款人的風險。線上上的環境下,欺詐風險尤其為嚴重,而且很多這種風險隱藏在複雜的關係網路之中,而且知識圖譜正好是為這類問題所設計的,所以我們“有可能”期待它能在欺詐,這個問題上帶來一些價值。

在進入下一個話題的討論之前,要明確的一點是,對於自身的業務問題到底需不需要知識圖譜系統的支援。因為在很多的實際場景,即使對關係的分析有一定的需求,實際上也可以利用傳統資料庫來完成分析的。所以為了避免使用知識圖譜而選擇知識圖譜,以及更好的技術選型,以下給出了幾點總結,供參考。

2 資料收集 & 預處理
下一步就是要確定資料源以及做必要的資料預處理。針對於資料源,我們需要考慮以下幾點:1. 我們已經有哪些資料? 2. 雖然現在沒有,但有可能拿到哪些資料? 3. 其中哪部分資料可以用來降低風險? 4. 哪部分資料可以用來構建知識圖譜?在這裡需要說明的一點是,並不是所有跟反欺詐相關的資料都必須要進入知識圖譜,對於這部分的一些決策原則在接下來的部分會有比較詳細的介紹。
對於反欺詐,有幾個資料源是我們很容易想得到的,包括使用者的基本資訊、行為資料、運營商資料、網路上的公開資訊等等。假設我們已經有了一個資料源的串列清單,則下一步就要看哪些資料需要進一步的處理,比如對於非結構化資料我們或多或少都需要用到跟自然語言處理相關的技術。 使用者填寫的基本資訊基本上會儲存在業務表裡,除了個別欄位需要進一步處理,很多欄位則直接可以用於建模或者新增到知識圖譜系統裡。對於行為資料來說,我們則需要透過一些簡單的處理,並從中提取有效的資訊比如“使用者在某個頁面停留時長”等等。 對於網路上公開的網頁資料,則需要一些資訊抽取相關的技術。
3 知識圖譜的設計
圖譜的設計是一門藝術,不僅要對業務有很深的理解、也需要對未來業務可能的變化有一定預估,從而設計出最貼近現狀並且效能高效的系統。在知識圖譜設計的問題上,我們肯定會面臨以下幾個常見的問題:1. 需要哪些物體、關係和屬性? 2. 哪些屬性可以做為物體,哪些物體可以作為屬性? 3. 哪些資訊不需要放在知識圖譜中?
基於這些常見的問題,我們從以往的設計經驗中抽象出了一系列的設計原則。這些設計原則就類似於傳統資料庫設計中的正規化,來引導相關人員設計出更合理的知識圖譜系統,同時保證系統的高效性。

接下來,我們舉幾個簡單的例子來說明其中的一些原則。 首先是,業務原則(Business Principle),它的含義是 “一切要從業務邏輯出發,並且透過觀察知識圖譜的設計也很容易推測其背後業務的邏輯,而且設計時也要想好未來業務可能的變化”。
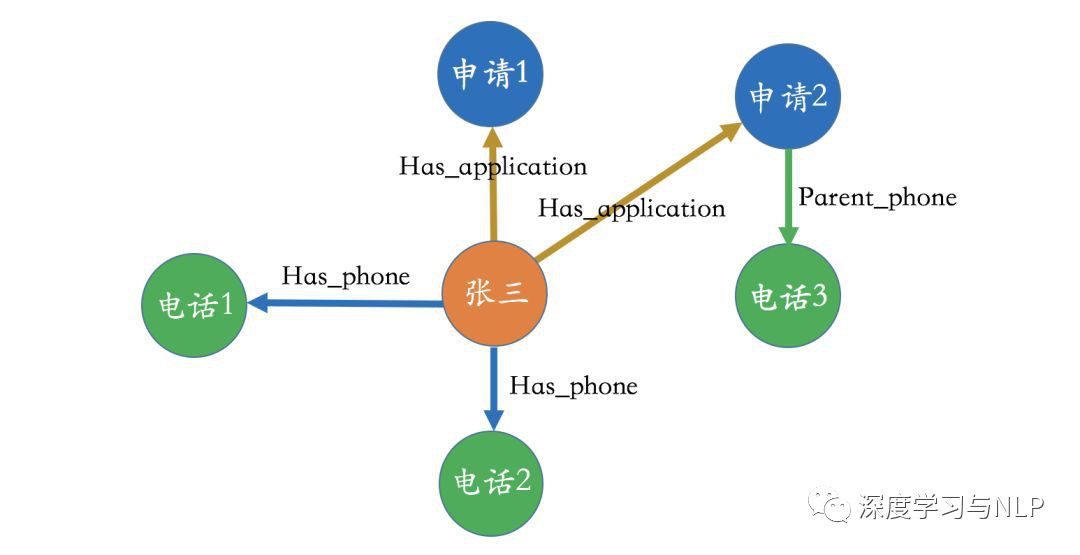
舉個例子,可以觀察一下下麵這個圖譜,並試問自己背後的業務邏輯是什麼。透過一番觀察,其實也很難看出到底業務流程是什麼樣的。做個簡單的解釋,這裡的物體-“申請”意思就是application,如果對這個領域有所瞭解,其實就是進件物體。在下麵的圖中,申請和電話物體之間的“has_phone”,“parent phone”是什麼意思呢?

接下來再看一下下麵的圖,跟之前的區別在於我們把申請人從原有的屬性中抽取出來並設定成了一個單獨的物體。在這種情況下,整個業務邏輯就變得很清晰,我們很容易看出張三申請了兩個貸款,而且張三擁有兩個手機號,在申請其中一個貸款的時候他填寫了父母的電話號。總而言之,一個好的設計很容易讓人看到業務本身的邏輯。
其他的原則不在這裡一一列出,感興趣的讀者可以關註一下“貪心科技”公眾號,可以檢視完整的內容。
4 把資料存入知識圖譜
儲存上我們要面臨儲存系統的選擇,但由於我們設計的知識圖譜帶有屬性,圖資料庫可以作為首選。但至於選擇哪個圖資料庫也要看業務量以及對效率的要求。如果資料量特別龐大,則Neo4j很可能滿足不了業務的需求,這時候不得不去選擇支援準分散式的系統比如OrientDB, JanusGraph等,或者透過效率、冗餘原則把資訊存放在傳統資料庫中,從而減少知識圖譜所承載的資訊量。 通常來講,對於10億節點以下規模的圖譜來說Neo4j已經足夠了。
5 上層應用的開發
等我們構建好知識圖譜之後,接下來就要使用它來解決具體的問題。對於風控知識圖譜來說,首要任務就是挖掘關係網路中隱藏的欺詐風險。從演演算法的角度來講,有兩種不同的場景:一種是基於規則的;另一種是基於機率的。鑒於目前AI技術的現狀,基於規則的方法論還是在垂直領域的應用中佔據主導地位,但隨著資料量的增加以及方法論的提升,基於機率的模型也將會逐步帶來更大的價值。
5.1 基於規則的方法論
首先,我們來看幾個基於規則的應用,分別是不一致性驗證、基於規則的特徵提取、基於樣式的判斷。
不一致性驗證
為了判斷關係網路中存在的風險,一種簡單的方法就是做不一致性驗證,也就是透過一些規則去找出潛在的矛盾點。這些規則是以人為的方式提前定義好的,所以在設計規則這個事情上需要一些業務的知識。比如在下麵的這個圖中,李明和李飛兩個人都註明瞭同樣的公司電話,但實際上從資料庫中判斷這倆人其實在不同的公司上班,這就是一個矛盾點。 類似的規則其實可以有很多,不在這裡一一列出。

基於樣式的判斷
這種方法比較適用於找出團體欺詐,它的核心在於透過一些樣式來找到有可能存在風險的團體或者子圖(sub-graph),然後對這部分子圖做進一步的分析。 這種樣式有很多種,在這裡舉幾個簡單的例子。 比如在下圖中,三個物體共享了很多其他的資訊,我們可以看做是一個團體,並對其做進一步的分析。

再比如,我們也可以從知識圖譜中找出強連通圖,並把它標記出來,然後做進一步風險分析。強連通圖意味著每一個節點都可以透過某種路徑達到其他的點,也就說明這些節點之間有很強的關係。

5.2 基於機率的方法
除了基於規則的方法,也可以使用機率統計的方法。 比如社群挖掘、標簽傳播、聚類等技術都屬於這個範疇。 對於這類技術,在本文裡不做詳細的講解,感興趣的讀者可以參考相關文獻。
社群挖掘演演算法的目的在於從圖中找出一些社群。對於社群,我們可以有多種定義,但直觀上可以理解為社群內節點之間關係的密度要明顯大於社群之間的關係密度。下麵的圖表示社群發現之後的結果,圖中總共標記了三個不同的社群。一旦我們得到這些社群之後,就可以做進一步的風險分析。
由於社群挖掘是基於機率的方法論,好處在於不需要人為地去定義規則,特別是對於一個龐大的關係網路來說,定義規則這事情本身是一件很複雜的事情。

標簽傳播演演算法的核心思想在於節點之間資訊的傳遞。這就類似於,跟優秀的人在一起自己也會逐漸地變優秀是一個道理。因為透過這種關係會不斷地吸取高質量的資訊,最後使得自己也會不知不覺中變得更加優秀。具體細節不在這裡做更多解釋。
相比規則的方法論,基於機率的方法的缺點在於:需要足夠多的資料。如果資料量很少,而且整個圖譜比較稀疏(Sparse),基於規則的方法可以成為我們的首選。尤其是對於金融領域來說,資料標簽會比較少,這也是為什麼基於規則的方法論還是更普遍地應用在金融領域中的主要原因。
6. 知識圖譜在其他行業中的應用
除了金融領域,知識圖譜的應用可以涉及到很多其他的行業,包括醫療、教育、證券投資、推薦等等。其實,只要有關係存在,則有知識圖譜可發揮價值的地方。 在這裡簡單舉一個證券領域中的應用。
在證券領域,我們經常會關心比如“一個事件發生了,對哪些公司產生什麼樣的影響?” 比如有一個負面訊息是關於公司1的高管,而且我們知道公司1和公司2有種很密切的合作關係,公司2有個主營產品是由公司3提供的原料基礎上做出來的。

其實有了這樣的一個知識圖譜,我們很容易回答哪些公司有可能會被這次的負面事件所影響。當然,僅僅是“有可能”,具體會不會有強相關性必須由資料來驗證。所以在這裡,知識圖譜的好處就是把我們所需要關註的範圍很快給我們圈定。接下來的問題會更複雜一些,比如既然我們知道公司3有可能被這次事件所影響,那具體影響程度有多大? 對於這個問題,光靠知識圖譜是很難回答的,必須要有一個影響模型、以及需要一些歷史資料才能在知識圖譜中做進一步推理以及計算。
7. 結語
知識圖譜是一個既充滿挑戰而且非常有趣的領域。只要有正確的應用場景,對於知識圖譜所能發揮的價值還是可以期待的。我相信在未來不到2,3年時間裡,知識圖譜技術會普及到各個領域當中。
免費公開課:
關註公眾號“貪心科技”,回覆關鍵字“公開課”獲得免費公開課地址。

貪心學院
融合了PBL的全新AI教育樣式
矽谷頂級AI科學家擔任學員導師
透過完成AI專案,獲得AI專案實操經驗
最終幫助學員成功邁入AI領域!
