
本文是一篇神經網路架構搜尋綜述文章,從 Search Space、Search Strategy、Performance Estimation Strategy 三個方面對架構搜尋的工作進行了綜述,幾乎涵蓋了所有近幾年的優秀工作。
■ 論文 | Neural Architecture Search: A Survey
■ 連結 | https://www.paperweekly.site/papers/2249
■ 作者 | Thomas Elsken / Jan Hendrik Metzen / Frank Hutter
引言
深度學習模型在很多工上都取得了不錯的效果,但調參對於深度模型來說是一項非常苦難的事情,眾多的超引數和網路結構引數會產生爆炸性的組合,常規的 random search 和 grid search 效率非常低,因此最近幾年神經網路的架構搜尋和超引數最佳化成為一個研究熱點。
本文從網路架構搜尋的三個方面進行了分類綜述,包括:
-
搜尋空間
-
搜尋策略
-
評價預估
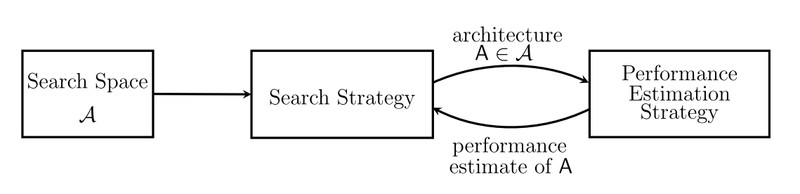
問題定義
網路架構和超引數最佳化的問題,有以下的特點:
1. 評價函式未知,是一個黑箱最佳化問題,因為評價往往是在 unseed dataset 上進行評價;
2. 非線性;
3. 非凸;
4. 混合最佳化,既有離散空間,又有連續空間;
5. 一次最佳化結果的評價非常耗時,大型的深度學習模型引數數以億計,執行一次結果需要幾周時間;
6. 在某些應用場景中,存在多個標的。比如:移動端的模型結構最佳化,既希望得到儘量高的準確率,又希望有非常好的模型計算效率。
搜尋空間
搜尋空間定義了最佳化問題的變數,網路結構和超引數的變數定義有所不同,不同的變數規模對於演演算法的難度來說也不盡相同。
早期很多工作都是用以遺傳演演算法為代表的進化演演算法對神經網路的超引數和權重進行最佳化,因為當時的神經網路只有幾層,每層十幾個神經元,也不存在複雜的網路架構,引數很有限,可直接進行最佳化。而深度學習模型一方面有著複雜的網路結構,另一方面權重引數通常都以百萬到億來計,進化演演算法根本無法最佳化。
但換個思路,假如我們找到了一組網路架構引數和對應的超引數,深度學習模型的效能其實是由這組引數來控制和決定的,所以只需要對複雜模型的架構引數和對應的超引數進行最佳化即可。
目前常見的一種網路架構是鏈狀結構,如下圖:
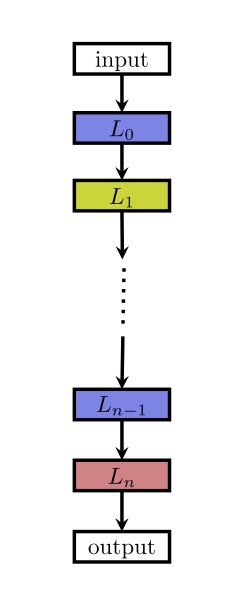
這種結構相當於一個 N 層的序列,每一層有幾種可選的運算元,比如摺積、池化等,每種運算元包括一些超引數,比如摺積尺寸、摺積步長等。
最近的一些工作受啟發於一些人工設計的網路架構,研究帶有多分支的網路,如下圖:

很多的深層 RNN 會有類似的結構,很多的網路結構雖然很深,但會有許多重覆 cell,將 cell 抽象出來之後,複雜的結構也會變得簡單,一方面可以減少最佳化變數數目,另一方面相同的 cell 在不同任務之間進行遷移,如下圖。

網路架構搜尋問題由於其高維度、連續和離散混合等諸多難點,在搜尋空間維度這塊如果可以做些降維,將會大大提升效果,Zoph 在 2018 年的工作用了 cell 這種方式相比於 2017 年的工作有 7 倍的加速。
搜尋策略
搜尋策略定義了使用怎樣的演演算法可以快速、準確找到最優的網路結構引數配置。常見的搜尋方法包括:隨機搜尋、貝葉斯最佳化、進化演演算法、強化學習、基於梯度的演演算法。其中,2017 年穀歌大腦的那篇強化學習搜尋方法將這一研究帶成了研究熱點,後來 Uber、Sentient、OpenAI、Deepmind 等公司和研究機構用進化演演算法對這一問題進行了研究,這個 task 算是進化演演算法一大熱點應用。
註:國內有很多家公司在做 AutoML,其中用到的一種主流搜尋演演算法是進化演演算法。
強化學習
強化學習是一種非常有意思的正規化,幾乎只要可以提煉出強化學習四要素,原問題就可以用強化學習來求解。
在 NAS 任務中,將架構的生成看成是一個 agent 在選擇 action,reward 是透過一個測試集上的效果預測函式來獲得(這個函式類似於工程最佳化問題中的 surrogate model,即代理模型)。這類工作整體的框架都是基於此,不同的點在於策略表示和最佳化演演算法。
一個工作是,用 RNN 來表示策略函式,初始化時先用策略梯度演演算法賦初值,然後用 PPO 來進行最佳化。另一個工作是,用簡單的 Q-learning 演演算法來訓練策略函式,序列地進行動作選擇,即選擇 layer 的型別和相關的超引數。
因為在 NAS 任務中,agent 與環境沒有互動,可以降階為無狀態的多臂老虎機(MAB)問題。 這裡的幾個工作都是近兩三年的新工作,後面會對這些 paper 進行專門解讀。
進化演演算法
進化演演算法是一大類演演算法,大概的框架也基本類似,先隨機生成一個種群(N 組解),開始迴圈以下幾個步驟:選擇、交叉、變異,直到滿足最終條件。最近幾年流行一種基於機率模型的進化演演算法 EDA (Estimation Distribution of Algorithm),基本的思路類似遺傳演演算法,不同的是沒有交叉、變異的環節,而是透過 learning 得到一個機率模型,由機率模型來 sample 下一步的種群。
用進化演演算法對神經網路超引數進行最佳化是一種很古老、很經典的解決方案,90 年代的學者用進化演演算法同時最佳化網路結構引數和各層之間的權重,因為當時的網路規模非常小,所以還能解決,但後續深度學習模型網路規模都非常大,無法直接最佳化。
進化演演算法是一種無梯度的最佳化演演算法(Derivative Free Optimization Algorithm),優點是可能會得到全域性最優解,缺點是效率相對較低,近兩年幾家高科技企業做 NAS 時都在用進化演演算法最佳化網路結構,同時用基於梯度的方法(BP)來最佳化權值。在 NAS 任務中,進化演演算法的交叉運算元和任務結合比較緊,被定義為一些類似新增、刪除層的操作,而非簡單的更改某一位編碼。
用進化演演算法解決 NAS 問題,不同的工作可能聚焦在不同的過程中,比如如何 sample 種群,如何 update 種群,如何生成子代種群等。這些工作將會被在後面的文章中進行解讀。
貝葉斯最佳化
貝葉斯最佳化(Bayesian Optimization)是超引數最佳化問題的常用手段,尤其是針對一些低維的問題,基於高斯過程(Gaussian Processes)和核方法(kernel trick)。對於高維最佳化問題,一些工作融合了樹模型或者隨機森林來解決,取得了不錯的效果。
除了常見的三大類方法,一些工作也在研究分層最佳化的思路,比如將進化演演算法和基於模型的序列最佳化方法融合起來,取各種方法的優勢。Real 在 2018 年的一個工作對比了強化學習、進化演演算法和隨機搜尋三類方法,前兩種的效果會更好一些。
評價預估
評價預估類似於工程最佳化中的代理模型(surrogate model),因為深度學習模型的效果非常依賴於訓練資料的規模,大規模資料上的模型訓練會非常耗時,對最佳化結果的評價將會非常耗時,所以需要一些手段去做近似的評估。
一種思路是用一些低保真的訓練集來訓練模型,低保真在實際應用可以有多種表達,比如訓練更少的次數,用原始訓練資料的一部分,低解析度的圖片,每一層用更少的濾波器等。用這種低保真的訓練集來測試最佳化演演算法會大大降低計算時間,但也存在一定的 bias,不過選擇最優的架構並不需要絕對數值,只需要有相對值就可以進行排序選優了。
另一種主流思路是借鑒於工程最佳化中的代理模型,在很多工程最佳化問題中,每一次最佳化得到的結果需要經過實驗或者高保真模擬(有限元分析)進行評價,實驗和模擬的時間非常久,不可能無限制地進行評價嘗試,學者們提出了一種叫做代理模型的回歸模型,用觀測到的點進行插值預測,這類方法中最重要的是在大搜索空間中如何選擇儘量少的點預測出最優結果的位置。
第三種主流思路是引數級別的遷移,用之前已經訓練好的模型權重引數對target問題進行賦值,從一個高起點的初值開始尋優將會大大地提高效率。在這類問題中,積累了大量的歷史尋優資料,對新問題的尋優將會起到很大的幫助,用遷移學習進行求解,是一個很不錯的思路。
另一種比較有意思的思路叫做單次(One-Shot)架構搜尋,這種方法將所有架構視作一個 one-shot 模型(超圖)的子圖,子圖之間透過超圖的邊來共享權重。
思考和評論
網路結構和超引數最佳化是自動機器學習(AutoML)中關鍵的一個環節,在上一個人工智慧時代,淺層神經網路比較火的時候,自動調參也有很多工作,只不過區別在於不僅僅對超引數進行最佳化,還對網路的權值一起進行了最佳化。
在這個人工智慧時代來臨之後,各種深度模型的效果非常好,重新點燃了這個方向的研究激情,加上強化學習的火熱,各種流派百家爭鳴。
這個領域中,今後比較有意思的研究點包括:
-
研究針對多工和多標的問題的 NAS;
-
研究更加靈活的搜尋變數表示,類似 cell 這種方便進行遷移的表示方式;
-
挖掘更多的、有難度的 benchmark;
-
遷移學習的引入,進一步提高效率。
本文作者是 Thomas Elsken,來自德國弗萊堡大學的博士生,他們組維護一個 AutoML 部落格 [1]。這篇綜述涵蓋了 NAS 任務近幾年幾乎所有的工作,總結地非常詳細。他們組裡還在撰寫一本 AutoML 的學術專著——AUTOML: METHODS, SYSTEMS, CHALLENGES [2]。
AutoML相關Paper Repo推薦:
1. awesome-automl-papers
https://github.com/hibayesian/awesome-automl-papers
2. awesome-architecture-search
https://github.com/markdtw/awesome-architecture-search
AutoML相關創業公司推薦:
1. 第四正規化
https://www.4paradigm.com/
2. 探智立方
http://iqubic.net/
3. 智易科技
https://www.zhiyi.cn/
4. 智鈾科技
https://www.wisutech.com/
5. 雲腦科技
http://www.cloudbrain.ai/
6. Sentient
https://www.sentient.ai/
當然,Google、Microsoft、Salesforce、阿裡雲也都有 AutoML 服務,很多大公司內部也都有自己的平臺,Uber、OpenAI、Deepmind 也都在 NAS 任務上做研究。從發展趨勢來看,AutoML 是未來人工智慧發展的一個重要方向,但目前現階段的研究成果成熟度和實際產品應用成熟度都存在巨大的提升空間。
相關連結
[1]. https://www.automl.org/
[2]. https://www.automl.org/book/

點選以下標題檢視更多論文解讀:
 #投 稿 通 道#
#投 稿 通 道#
讓你的論文被更多人看到
如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準:
• 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向)
• 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結
• PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱:
• 投稿郵箱:hr@paperweekly.site
• 所有文章配圖,請單獨在附件中傳送
• 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 獲取最新論文推薦
