
作者丨蘇劍林
單位丨廣州火焰資訊科技有限公司
研究方向丨NLP,神經網路
個人主頁丨kexue.fm
話說自稱搞了這麼久的 NLP,我都還沒有真正跑過 NLP 與深度學習結合的經典之作——Seq2Seq。這兩天興緻來了,決定學習並實踐一番 Seq2Seq,當然最後少不了 Keras 實現了。
Seq2Seq 可以做的事情非常多,我這挑選的是比較簡單的根據文章內容生成標題(中文),也可以理解為自動摘要的一種。選擇這個任務主要是因為“文章-標題”這樣的語料對比較好找,能快速實驗一下。
Seq2Seq簡介
所謂 Seq2Seq,就是指一般的序列到序列的轉換任務,比如機器翻譯、自動文摘等等,這種任務的特點是輸入序列和輸出序列是不對齊的,如果對齊的話,那麼我們稱之為序列標註,這就比 Seq2Seq 簡單很多了。所以儘管序列標註任務也可以理解為序列到序列的轉換,但我們在談到 Seq2Seq 時,一般不包含序列標註。
要自己實現 Seq2Seq,關鍵是搞懂 Seq2Seq 的原理和架構,一旦弄清楚了,其實不管哪個框架實現起來都不複雜。早期有一個第三方實現的 Keras 的 Seq2Seq 庫 [1],現在作者也已經放棄更新了,也許就是覺得這麼簡單的事情沒必要再建一個庫了吧。可以參考的資料還有去年 Keras 官方部落格中寫的 A ten-minute introduction to sequence-to-sequence learning in Keras [2]。
基本結構
假如原句子為 X=(a,b,c,d,e,f),標的輸出為 Y=(P,Q,R,S,T),那麼一個基本的 Seq2Seq 就如下圖所示。
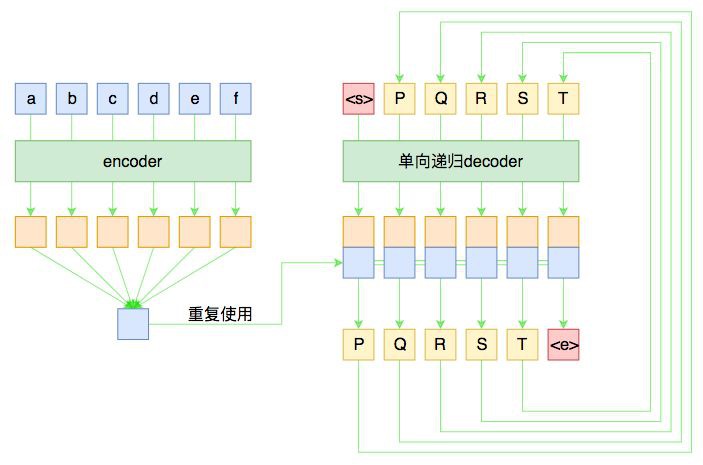
▲ 基本的Seq2Seq架構
儘管整個圖的線條比較多,可能有點眼花,但其實結構很簡單。左邊是對輸入的 encoder,它負責把輸入(可能是變長的)編碼為一個固定大小的向量,這個可選擇的模型就很多了,用 GRU、LSTM 等 RNN 結構或者 CNN+Pooling、Google 的純 Attention 等都可以,這個固定大小的向量,理論上就包含了輸入句子的全部資訊。
而 decoder 負責將剛才我們編碼出來的向量解碼為我們期望的輸出。與 encoder 不同,我們在圖上強調 decoder 是“單向遞迴”的,因為解碼過程是遞迴進行的,具體流程為:
1. 所有輸出端,都以一個通用的
2. 將
3. 將 P 輸入 decoder,得到新的隱藏層向量,再次與 encoder 的輸出混合,送入分類器,分類器應輸出 Q;
4. 依此遞迴,直到分類器的結果輸出
這就是一個基本的 Seq2Seq 模型的解碼過程,在解碼的過程中,將每步的解碼結果送入到下一步中去,直到輸出
訓練過程
事實上,上圖也表明瞭一般的 Seq2Seq 的訓練過程。由於訓練的時候我們有標註資料對,因此我們能提前預知 decoder 每一步的輸入和輸出,因此整個結果實際上是“輸入 X 和 Y,預測 Y[1:],即將標的 Y 錯開一位來訓練。
而 decoder 同樣可以用 GRU、LSTM 或 CNN 等結構,但註意再次強調這種“預知未來”的特性僅僅在訓練中才有可能,在預測階段是不存在的,因此 decoder 在執行每一步時,不能提前使用後面步的輸入。
所以,如果用 RNN 結構,一般都只使用單向 RNN;如果使用 CNN 或者純 Attention,那麼需要把後面的部分給 mask 掉(對於摺積來說,就是在摺積核上乘上一個 0/1 矩陣,使得摺積只能讀取當前位置及其“左邊”的輸入,對於 Attention 來說也類似,不過是對 query 的序列進行 mask 處理)。
敏感的讀者可能會察覺到,這種訓練方案是“區域性”的,事實上不夠端到端。比如當我們預測 R 時是假設 Q 已知的,即 Q 在前一步被成功預測,但這是不能直接得到保證的。一般前面某一步的預測出錯,那麼可能導致連鎖反應,後面各步的訓練和預測都沒有意義了。
有學者考慮過這個問題,比如文章 Sequence-to-Sequence Learning as Beam-Search Optimization [3] 把整個解碼搜尋過程也加入到訓練過程,而且還是純粹梯度下降的(不用強化學習),是非常值得借鑒的一種做法。不過區域性訓練的計算成本比較低,一般情況下我們都只是使用區域性訓練來訓練 Seq2Seq。
Beam Search
前面已經多次提到瞭解碼過程,但還不完整。事實上,對於 Seq2Seq 來說,我們是在建模:
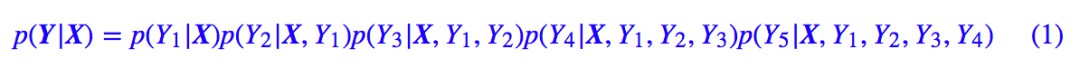
顯然在解碼時,我們希望能找到最大機率的 Y,那要怎麼做呢?
如果在第一步 p(Y1|X) 時,直接選擇最大機率的那個(我們期望是標的 P),然後代入第二步 p(Y2|X,Y1),再次選擇最大機率的 Y2,依此類推,每一步都選擇當前最大機率的輸出,那麼就稱為貪心搜尋,是一種最低成本的解碼方案。但是要註意,這種方案得到的結果未必是最優的,假如第一步我們選擇了機率不是最大的 Y1,代入第二步時也許會得到非常大的條件機率 p(Y2|X,Y1),從而兩者的乘積會超過逐位取最大的演演算法。
然而,如果真的要列舉所有路徑取最優,那計算量是大到難以接受的(這不是一個馬爾可夫過程,動態規劃也用不了)。因此,Seq2Seq 使用了一種折中的方法:Beam Search。
這種演演算法類似動態規劃,但即使在能用動態規劃的問題下,它還比動態規劃要簡單,它的思想是:在每步計算時,只保留當前最優的 topk 個候選結果。比如取 topk=3,那麼第一步時,我們只保留使得 p(Y1|X) 最大的前 3 個 Y1,然後分別代入 p(Y2|X,Y1),然後各取前三個 Y2,這樣一來我們就有 個組合了,這時我們計算每一種組合的總機率,然後還是隻保留前三個,依次遞迴,直到出現了第一個
個組合了,這時我們計算每一種組合的總機率,然後還是隻保留前三個,依次遞迴,直到出現了第一個
Seq2Seq提升
前面所示的 Seq2Seq 模型是標準的,但它把整個輸入編碼為一個固定大小的向量,然後用這個向量解碼,這意味著這個向量理論上能包含原來輸入的所有資訊,會對 encoder 和 decoder 有更高的要求,尤其在機器翻譯等資訊不變的任務上。因為這種模型相當於讓我們“看了一遍中文後就直接寫出對應的英文翻譯”那樣,要求有強大的記憶能力和解碼能力,事實上普通人完全不必這樣,我們還會反覆翻看對比原文,這就導致了下麵的兩個技巧。
Attention
Attention 目前基本上已經是 Seq2Seq 模型的“標配”模組了,它的思想就是:每一步解碼時,不僅僅要結合 encoder 編碼出來的固定大小的向量(通讀全文),還要往回查閱原來的每一個字詞(精讀區域性),兩者配合來決定當前步的輸出。

▲ 帶Attention的Seq2Seq
至於 Attention 的具體做法,筆者之前已經撰文介紹過了,請參考一文讀懂「Attention is All You Need」| 附程式碼實現。Attention 一般分為乘性和加性兩種,筆者介紹的是 Google 系統介紹的乘性的 Attention,加性的 Attention 讀者可以自行查閱,只要抓住 query、key、value 三個要素,Attention 就都不難理解了。
先驗知識
回到用 Seq2Seq 生成文章標題這個任務上,模型可以做些簡化,並且可以引入一些先驗知識。比如,由於輸入語言和輸出語言都是中文,因此 encoder 和 decoder 的 Embedding 層可以共享引數(也就是用同一套詞向量)。這使得模型的引數量大幅度減少了。
此外,還有一個很有用的先驗知識:標題中的大部分字詞都在文章中出現過(註:僅僅是出現過,並不一定是連續出現,更不能說標題包含在文章中,不然就成為一個普通的序列標註問題了)。這樣一來,我們可以用文章中的詞集作為一個先驗分佈,加到解碼過程的分類模型中,使得模型在解碼輸出時更傾向選用文章中已有的字詞。
具體來說,在每一步預測時,我們得到總向量 x(如前面所述,它應該是 decoder 當前的隱層向量、encoder 的編碼向量、當前 decoder 與 encoder 的 Attention 編碼三者的拼接),然後接入到全連線層,最終得到一個大小為 |V| 的向量 y=(y1,y2,…,y|V|),其中 |V| 是詞表的詞數。y 經過 softmax 後,得到原本的機率:

這就是原始的分類方案。引入先驗分佈的方案是,對於每篇文章,我們得到一個大小為 |V| 的 0/1 向量 χ=(χ1,χ2,…,χ|V|),其中 χi=1 意味著該詞在文章中出現過,否則 χi=0。將這樣的一個 0/1 向量經過一個縮放平移層得到:
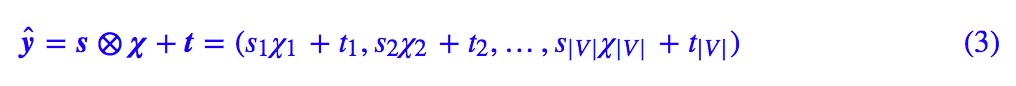
其中 s,t 為訓練引數,然後將這個向量與原來的 y 取平均後才做 softmax:
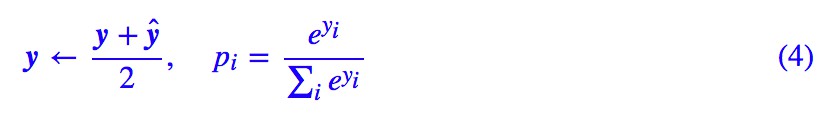
經實驗,這個先驗分佈的引入,有助於加快收斂,生成更穩定的、質量更優的標題。
Keras參考
又到了快樂的開源時光~
基本實現
基於上面的描述,我收集了 80 多萬篇新聞的語料,來試圖訓練一個自動標題的模型。簡單起見,我選擇了以字為基本單位,並且引入了 4 個額外標記,分別代表 mask、unk、start、end。而 encoder 我使用了雙層雙向 LSTM,decoder 使用了雙層單向 LSTM。具體細節可以參考原始碼:
https://github.com/bojone/seq2seq/blob/master/seq2seq.py
我以 6.4 萬文章為一個 epoch,訓練了 50 個 epoch 之後,基本就生成了看上去還行的標題:
文章內容:8 月 28 日,網路爆料稱,華住集團旗下連鎖酒店使用者資料疑似發生洩露。從賣家釋出的內容看,資料包含華住旗下漢庭、禧玥、桔子、宜必思等 10 餘個品牌酒店的住客資訊。洩露的資訊包括華住官網註冊資料、酒店入住登記的身份 資訊及酒店開房記錄,住客姓名、手機號、郵箱、身份證號、登入賬號密碼等。賣家對這個約 5 億條資料打包出售。第三方安全平臺威脅獵人對資訊出售者提供的三萬條資料進行驗證,認為資料真實性非常高。當天下午,華住集團發 宣告稱,已在內部迅速開展核查,並第一時間報警。當晚,上海警方訊息稱,接到華住集團報案,警方已經介入調查。
生成標題:《酒店使用者資料疑似發生洩露》
文章內容:新浪體育訊 北京時間 10 月 16 日,NBA 中國賽廣州站如約開打,火箭再次勝出,以 95-85 擊敗籃網。姚明漸入佳境,打了 18 分 39 秒,8 投 5 中,拿下 10 分 5 個籃板,他還蓋帽 1 次。火箭以兩戰皆勝的戰績圓滿結束中國行。
生成標題:《直擊:火箭兩戰皆勝火箭再勝 廣州站姚明10分5板》
當然這隻是兩個比較好的例子,還有很多不好的例子,直接用到工程上肯定是不夠的,還需要很多“黑科技”最佳化才行。
mask
在 Seq2Seq 中,做好 mask 是非常重要的,所謂 mask,就是要遮掩掉不應該讀取到的資訊、或者是無用的資訊,一般是用 0/1 向量來乘掉它。Keras 自帶的 mask 機制十分不友好,有些層不支援 mask,而普通的 LSTM 開啟了 mask 後速度幾乎下降了一半。所以現在我都是直接以 0 作為 mask 的標記,然後自己寫個 Lambda 層進行轉化的,這樣速度基本無損,而且支援嵌入到任意層,具體可以參考上面的程式碼。
要註意我們以往一般是不區分 mask 和 unk(未登入詞)的,但如果採用我這種方案,還是把未登入詞區分一下比較好,因為未登入詞儘管我們不清楚具體含義,它還是一個真正的詞,至少有佔位作用,而 mask 是我們希望完全抹掉的資訊。
解碼端
程式碼中已經實現了 beam search 解碼,讀者可以自行測試不同的 topk 對解碼結果的影響。
這裡要說的是,參考程式碼中對解碼的實現是比較偷懶的,會使得解碼速度大降。理論上來說,我們每次得到當前時刻的輸出後,我們只需要傳入到 LSTM 的下一步迭代中去,就可以得到下一時刻的輸出,但這需要重寫解碼端的 LSTM(也就是要區分訓練階段和測試階段,兩者共享權重),相對複雜,而且對初學者並不友好。所以我使用了一個非常粗暴的方案:每一步預測都重跑一次整個模型,這樣一來程式碼量最少,但是越到後面越慢,原來是 ?(n) 的計算量變成了 。
。
最後的話
又用 Keras 跑通了一個例子,不錯不錯,堅定不移高舉 Keras 旗幟~
自動標題任務的語料比較好找,而且在 Seq2Seq 任務中屬於難度比較低的一個,適合大家練手,想要入坑的朋友趕緊上吧。
參考文獻
[1]. https://github.com/farizrahman4u/seq2seq
[2]. https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
[3]. Sam Wiseman and Alexander M Rush. Sequence-to-sequence learning as beam-search optimization. In EMNLP, 2016.

點選以下標題檢視作者其他文章:
 #投 稿 通 道#
#投 稿 通 道#
讓你的論文被更多人看到
如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準:
• 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向)
• 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結
• PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱:
• 投稿郵箱:hr@paperweekly.site
• 所有文章配圖,請單獨在附件中傳送
• 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視作者部落格
