本文主要翻譯並改編自lwn文章 https://lwn.net/Articles/736534/。
有一位讀者郭健在閱讀本文後,對我們的翻譯提供了勘誤,所以重發此文,並對這位讀者表示感謝,勘誤部分做了標紅。如果大家還有其他問題,歡迎發郵件到boyu點mt at alibaba-inc.com。
像linux這樣的作業系統, 一個非常有價值的東西就是提供了一套具體裝置的抽象介面,比如我們常提到的字元裝置, 塊裝置,網路裝置,點陣圖顯示器等等。其中塊裝置非常重要,尤其隨著持久化儲存的不斷發展以及未來持久化記憶體的持續增長,塊裝置抽象的應用場景將越來越廣泛。所以今天就讓我們來剖析和解讀一下塊裝置介面。
首先定義一下什麼是“塊層”(block layer)。一般當我們提到“塊層”時,是指Linux核心中應用程式和檔案系統用來訪問多種不同的儲存裝置的模組介面。那麼究竟哪些程式碼構成了塊層呢?一個不動腦子的答案就是在linux kernel原始碼中block子目錄下的所有程式碼都是塊層。 這一堆程式碼可以看做提供了兩個抽象層,他們合作緊密,但是又有所不同。這兩層目前在社群並沒有統一的叫法,我們姑且叫他們bio層和request層。本文主要介紹bio層,而request層則會在另外一篇文章中介紹。
塊層之上
在深入瞭解bio層之前,還是有必要瞭解一下塊裝置之上的層。這裡提到的”上“,是指離使用者態更近一些,而離硬體更遠一些。下圖表述了塊層在核心中的位置。

訪問塊裝置通常是透過/dev目錄下檔案來實現,例如/dev/sda這樣的就是塊裝置,它們在核心中被對映成S_IFBLK屬性的inodes。這些檔案並不代表真正的塊裝置,而更像是軟連結,我們可以透過它們代表的’major:minor’這樣的數字來找到真正的塊裝置。在內核的inode結構體中,i_bdev這個成員被用來指向一個代表真實裝置的結構體struct block_device。而這個struct block_device中的bd_inode則指向了另外一個inode,這個inode才和這個塊裝置的I/O真正相關。

當裝置沒有使用O_DIRECT開啟的時候, 這個bd_inode(實現在fs/block_dev.c, fs/buffer.c等)的主要角色是提供page cache。像一個正常被開啟的檔案一樣,這個inode節點的page同意被用於對這個裝置進行緩衝讀,預讀,緩衝寫,延遲寫等等。當這個裝置被以O_DIRECT的方式開啟的時候,讀寫則會直接到塊裝置。一般來說,當一個檔案系統掛載一個塊裝置時,檔案系統的讀寫操作通常都是直接訪問塊裝置。但是對於另外一些檔案系統(比如我們經常用到的ext *系列),它們則會用bd_inode的page cache來管理一些檔案系統的元資料。
這裡需要重點提到一個與塊裝置特別相關的open標誌是O_EXCL。塊裝置透過這個flag來確定每個塊裝置最多可以有一個“持有人”。當我們試圖持有一個塊裝置(例如,在核心中使用blkdev_get()或類似的呼叫)的時候,如果在我們之前已經有另外一個不同的持有者已經擁有了該裝置,那麼我們的持有請求將會失敗。一般的檔案系統試圖掛載裝置的時候會使用這個open標誌,從而確保自己是獨佔裝置的。所以如果檔案系統以O_EXCL的方式成功開啟了裝置,那麼從此以後它就會成為這個裝置的持有者。如果這以後再有檔案系統嘗試去mount的話, 就會失敗。這裡有一點比較有趣的是,使用O_EXCL並不會阻止在沒有O_EXCL的情況下開啟塊裝置,因此它其實並不會阻止併發寫入,而僅僅是阻止了其他檔案系統以獨佔方式開啟裝置。
無論以哪種方式訪問塊裝置,有一點是一致的,都是bio層在向上提供的主要介面, 包括傳送讀取或寫入請求,或者其他一些請求比如”discard”,並最終將答覆傳回給上層。
bio層
linux上是用結構體gendisk來代表塊裝置, 這個結構體並不包含很多實用的資訊,而主要是作為上面的檔案系統和下麵的裝置層之間的介面。在gendisk之上是一個或多個struct block_device,也就是前文提到的/dev中的inode連結。 當一個gendisk有多個分割槽時,它會和多個block_device結構關聯。所以我們會有一個block_device代表整個gendisk(比如/dev/sda),也有可能還有一些其他的block_device代表gendisk中的分割槽(比如/dev/sda1, /dev/sda2, …)。
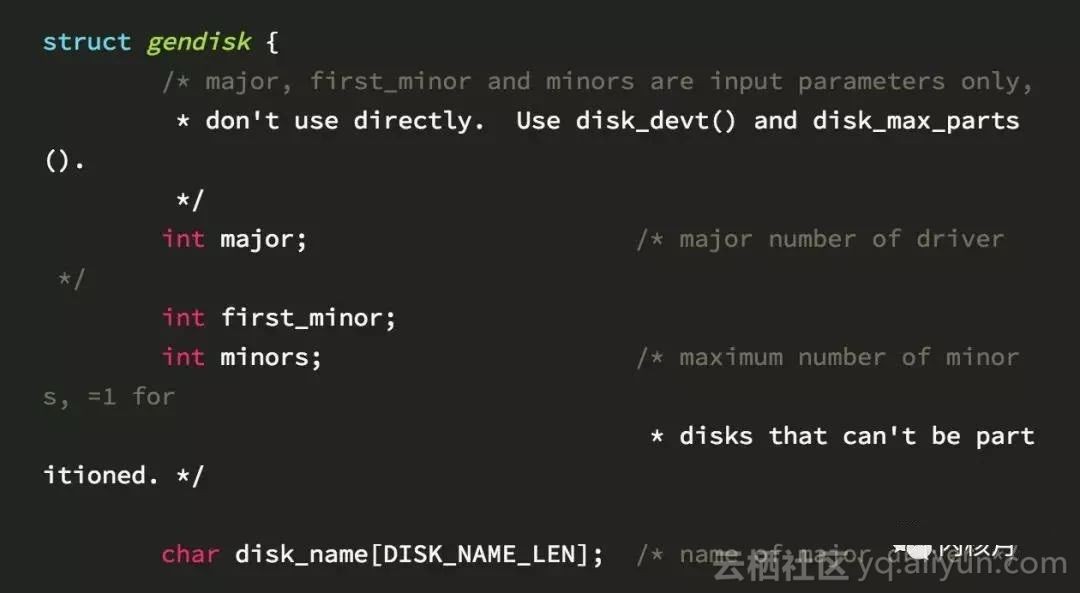
在bio層裡面還有一個結構體叫做struct bio。
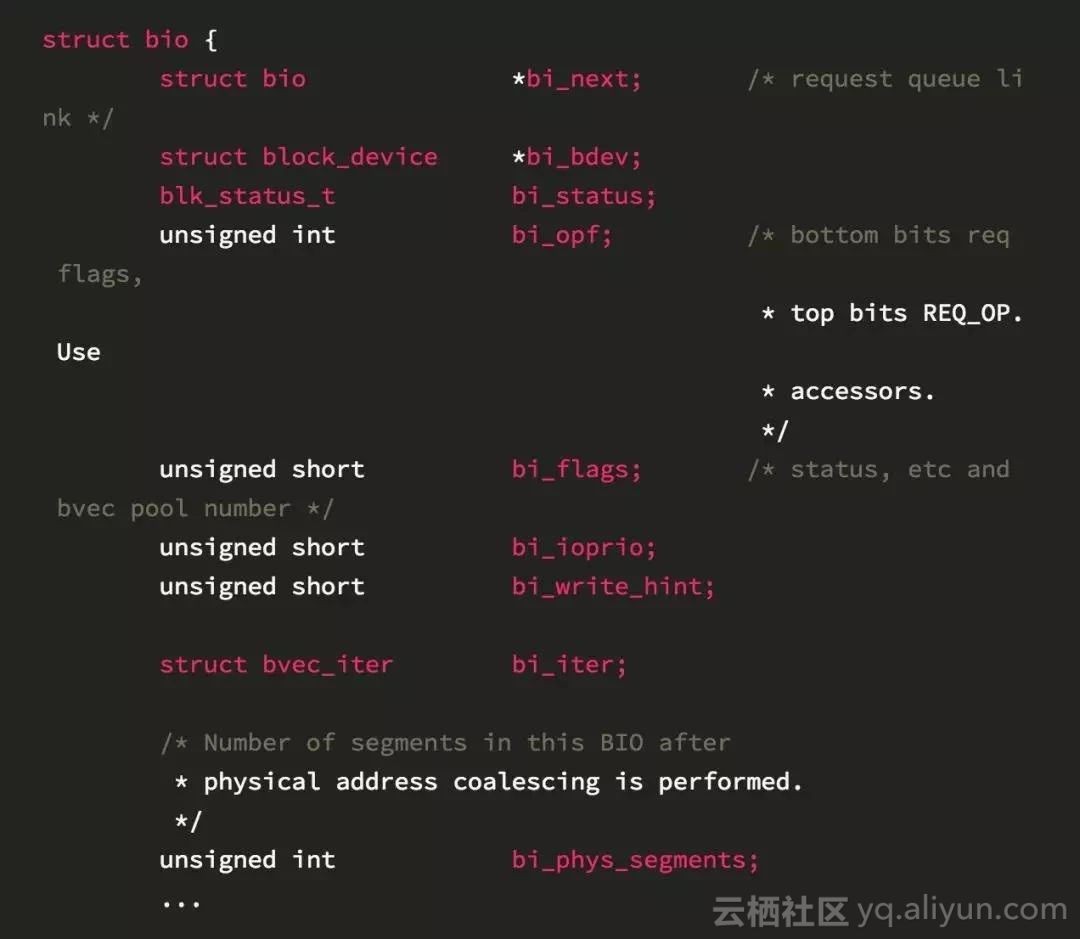
它代表來自block_device的讀取和寫入請求, 以及其他一些控制請求。這些請求從block_device發出, 經過gendisk再到裝置驅動。 一個bio結構體裡面主要包括具體的塊裝置資訊,塊裝置中的偏移量,請求大小,請求型別(讀或寫)以及放置資料的記憶體位置。在Linux 4.14之前,bio中透過指向struct block_device的指標來標識標的裝置。4.14以後,struct block_device被替換成一個指向struct gendisk的指標以及一個可以由bio_set_dev()設定的分割槽號。考慮到gendisk結構的核心作用,這樣的改動更自然一些。
一旦bio構造完成,我們就可以透過呼叫generic_make_request或者submit_bio來發起bio請求。但是一般情況下我們並不會等待請求完成,而只是將其插入佇列以便後續處理,所以整個過程是非同步的。不過這裡有一點需要註意,在一些場景下generic_make_request()仍然可能由於等待記憶體可用(比如它可能會等待先前的請求在完成以後從佇列中摘除,從而騰出佇列中的空間)而在短時間內阻塞。在這種場景下,如果在bi_opf欄位中設定了REQ_NOWAIT標誌,那麼generic_make_request()就不會等待,而是把bio設定為BLK_STS_AGAIN或者BLK_STS_NOTSUPP,然後直接傳回。不過在撰寫本文時,這個功能的實現還有一些問題。
bio層和request層之間的契約以及互動協議很簡單,主要的動作就是讓裝置透過呼叫blk_queue_make_request()並傳入自己的make_request_fn函式。如果裝置傳入了自己的make_request_fn,genric_make_request()會呼叫它從而完成bio的傳送工作。當一個bio代表的I/O請求完成以後,這個請求的bi_status欄位設定為成功或失敗,同時bio_endio()會被呼叫來結束這個bio。
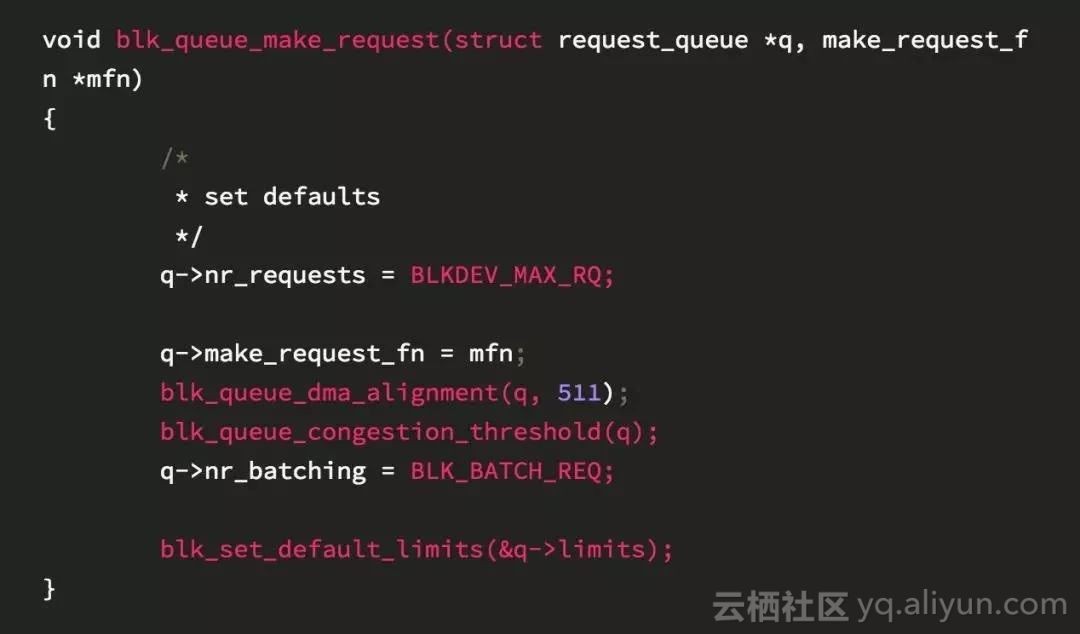
除了上面提到的處理bio的讀寫請求之外,bio層最值得展開的兩件事情是避免遞迴的技巧以及佇列的插入和拔出,接下來讓我們分別闡述一下。
避免遞迴
在使用虛擬塊裝置,比如md(軟RAID),dm(lvm2)的時候,我們會將一個塊裝置疊在另一個塊裝置上面,在這種場景下一個塊裝置的bio會被修改併發到下一層塊裝置的bio裡面去,實現起來很簡單,但是執行起來會給核心棧的使用造成極大的負擔。在2.6.22之前,由於檔案系統已經使用了很大一部分核心棧,核心棧上限溢位可能會有很嚴重的問題。為瞭解決這個問題,generic_make_request()會檢測是否被遞迴呼叫並作相應的處理。在發生遞迴的時候它不將bio傳遞到下一層,而只是內部(透過使用current->bio_list )對bio進行排隊。只有當父bio完成的時候,它才會提交這個請求。由於前面提到generic_make_request()一般不會等待bio完成才傳回,所以不立即處理bio也沒啥問題。
這個避免遞迴的方案在大部分場景下是可以工作的,但卻在一些特殊場景可能會導致死鎖。讓我們再次描述一下這個場景,在generic_make_request呼叫make_request_fn的時候,看到之前有bio提交,就等待這個先前提交的bio完成。那麼如果等待的那個bio還在current->bio_list佇列上怎麼辦?很明顯這兩個bio都存在問題,就導致了死鎖。
在實際情況中,一個bio等待另一個bio的場景是非常微妙的,所以一般這種死鎖都是透過測試發現的, 而不是程式碼檢查,我們在這裡舉一個可能導致死鎖的例子。當一個bio提交的時候, 如果遇到了大小限制或者對齊要求,make_request_fn就會把這個bio分成2個(bio層透過bio_split,bio_chain來實現),但是這個操作需要為第二個bio分配記憶體空間。怎麼分配記憶體呢?我們知道當系統沒記憶體的時候,申請記憶體總是危險的,linux通常的做法是寫臟頁來釋放記憶體, 但是如果寫臟頁也需要記憶體的話,那麼很可能就死鎖了。所以這裡標準的做法是使用mempool預先分配一些記憶體,然後我們直接從mempool中分配從而避免記憶體分配的死鎖問題。看上去不錯,是麼?在bio這個場景下這個解法的問題來了。由於bio從mempool分配可能會需要等待以前的使用者傳回他們使用的mempool記憶體,而這個等待的依賴關係又會是某些之前的bio,所以可能會再次導致generic_make_request()死鎖。我的天哪,核心程式設計簡直就是在和各種死鎖,各種記憶體不足做鬥爭中。。。
為了避免這個死鎖,核心研發人員做了很多嘗試。其中一個想法就是大家在呼叫ps時看到的那些bioset行程。該機制特別關註上述死鎖場景,它為每個用於bio分配的mempool分配一個“rescuer”執行緒。如果bio分配不成功,那麼所有當前行程的current->bio_list中的來自同一個bioset的所有bios將會被交給bioset執行緒進行處理。這種方法相當醜陋,因為我們需要建立了一些幾乎從不被使用的執行緒,而這些執行緒在核心中的存在僅僅是為瞭解決這個特定的死鎖場景。而其他大多數的死鎖情況也涉及將bios分成兩個或更多的部分,但是它們並不總是涉及到mempool的分配問題。一股淡淡的憂傷啊!
不過一個好訊息是最近的核心已經很少依賴這個特性了,並且已經在儘量避免建立不需要的bioset執行緒。在Linux 4.11中,研發人員對generic_make_request()做了修改並引入了更通用的替代方案。這個方案系統執行開銷較少,只是對驅動有一定的要求。具體來說,當bio被拆分時,其中一半應該直接提交到generic_make_request()並被立刻處理,而另一半則可以以其他適當的方式進行處理。這無疑給了generic_make_request()更多的控制權,它可以根據所提交的塊裝置堆疊深度對所有bio進行排序,並優先處理底層塊裝置的bio。這個簡單的做法解決了所有令人討厭的死鎖問題。真是換個思路海闊天空啊!
裝置佇列插入
Device queue plugging,這個詞一直沒想好怎麼翻譯,就這樣吧!
通常情況下儲存裝置對單次請求進行操作的開銷比較大,因此將一批請求集中在一起並作為一個單元提交它會更有效率。當裝置相對較慢時,通常請求佇列中會有很多未處理的請求,這樣該佇列的存在也提供了很多機會來合併請求。反過來當裝置速度很快或者當一個慢速裝置空閑時,找到合併請求並批次處理的機會就會少很多,那麼無腦的嘗試合併則會很浪費時間和精力。所以為瞭解決這個問題,Linux塊層創造了一個“插入/拔出”(plug/unplug)的概念。
一開始,佇列是空的並且是被插入(plug)的。所以在向空佇列提交請求的時候以及今後的一段時間內,不會有任何請求流入底層裝置,這樣由檔案系統提交的bio們就可以有充足的機會進行合併。而當檔案系統提交了足夠的bio以後,它會顯式的進行拔出操作(unlug),或者在一個很短的時間以後被預設拔出,拔出以後IO開始下發。Linux內核的bio層就是透過這樣的plug/unplug方式來保證I/O請求能夠被批次下發,並且希望找到一個合適的提交I/O請求的數量並達到最終的效能提升。在核心研發早期,每個塊裝置只有一個plug/unplug佇列,這樣導致多CPU場景下的佇列爭搶問題非常嚴重。在Linux 2.6.39版本,Linux核心合併進了一個新的plug/unlug機制,這個機制允許每個行程在自己的背景關係中進行佇列的插入工作,從而在CPU多核的擴充套件性上得到了明顯的提升。具體的新機制是這樣工作的。
當塊裝置的檔案系統或其他客戶端提交請求I/O時,它通常在generic_make_request()前呼叫blk_start_plug(),結束之後再呼叫blk_finish_plug()。blk_start_plug主要的作用是初始化current-> plug,該資料結構包含一個blk_plug_cb的佇列(還有一個結構請求佇列,我們將在下一篇文章中詳細介紹)。由於這個佇列都是歸屬於行程的,因此可以在無鎖環境下新增相應的條目。 這樣make_request_fn就可以對傳過來的bio做靈活的處理,比如如果它認為批處理請求更有優勢,那麼它可以選擇將bio新增到佇列中。當呼叫blk_finish_plug()時,或者行程呼叫schedule()時(例如等待互斥鎖或等待記憶體分配時),current-> plug中儲存的每個bio將會被處理。

機制看上去很簡單,但是這裡有兩個有意思的設計值得大家思考。
第一個,為什麼在發生schedule()的時候需要處理plug佇列呢?因為如果行程被阻塞,佇列就會被立刻處理,這樣可以防止其他行程等待這個行程正在準備提交的bio,防止前面提到的死鎖。
第二個,為什麼在行程級別維護這樣的佇列?因為一個行程提交的bio基本都是有關係的,而有關係的bio可以很容易得被檢測和合併在一起,另外一點就是相關操作都可以是無鎖的。想象一下如果這個不是行程級別的話,在操作bio的時候,肯定需要一個自旋鎖或者一個原子變數來保護佇列的操作。而透過每個行程的自有佇列,我們可以無鎖的建立每個行程自己的bio串列,然後只用一次spinlock將它們全部合併到最終的塊裝置公共佇列中。
總結
總之,bio層是一個很薄的層,它的主要功能是以bio的形式接受I/O請求,並將它們直接傳遞給相應的make_request_fn()函式。它提供了各種支援功能,以簡化bio的分拆和排程,同時透過plug/unplug來最佳化效能。它還執行一些其他簡單的任務,例如更新/proc/vmstat中的pgpgin和pgpgout統計資訊等等。
當然作為承上啟下的模組,他另外一個重要工作是讓在它下麵的模組的工作能夠繼續下去,有時下一層是一個驅動程式,例如drbd(分散式複製塊裝置)或brd(基於RAM的塊裝置);有時下一層是一個中間層,例如由md和dm提供的虛擬裝置;還有一些可能是我們最常見的塊層的剩餘部分,我們稱之為“請求層”(request layer)。這一層的一些錯綜複雜的內容將在另外一篇文章中展開。
