

在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @TwistedW。在異常檢測模組下,如果沒有異常(負例樣本)來訓練模型,應該如何實現異常檢測?本文提出的模型——GANomaly,便是可以實現在毫無異常樣本訓練下對異常樣本做檢測。
如果你對本文工作感興趣,點選底部閱讀原文即可檢視原論文。
關於作者:武廣,合肥工業大學碩士生,研究方向為影象生成。
■ 論文 | GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training
■ 連結 | https://www.paperweekly.site/papers/2293
■ 原始碼 | https://github.com/samet-akcay/ganomaly
異常檢測(Anomaly Detection)是計算機視覺中的一個經典問題,生活中大部分的資料是正常資料,有很少一部分屬於異常資料,在很少的異常下如何檢測出異常是一個困難的課題,甚至不知道什麼是異常,只知道不屬於正常的就算異常的話又如何檢測異常呢?GANomaly 便是可以實現在毫無異常樣本訓練下對異常樣本做檢測,我們一起來讀一下。
論文引入
在計算機視覺上大部分的檢測任務的前提是需要大量的標記資料做訓練,這雖然在成本上耗費巨大,但是在實驗效果上確實有很大的突破,目前的標的檢測技術已經上升到近乎實時檢測的效果了,背後的人力和成本也是可想而知的。
在龐大的標的檢測背景下,異常檢測算是一個特立獨行的分支,雖然只是判斷正常和異常兩種情況(二分類問題),但是往往異常樣本特別的少,如果從特徵提取上區分正常和異常的話,由於訓練樣本過少或者說是訓練樣本比例太不平衡(正常樣本特別多)往往會導致實驗結果上不盡如人意。
異常檢測的發展在深度學習的浪潮下得到了很快的發展,基於 CNN,RNN、LSTM 技術上已經取得了一定的成效。隨著 GAN 的提出,對抗的思想越來越引人註意,利用 GAN 做異常檢測的文章在實驗上有了一定的突破,從 AnoGAN [1] 學習到正常樣本的分佈,一旦送入異常樣本資料發生改變從而檢測出異常,這種方法的侷限性很強,往往也會帶來計算成本的昂貴(需要嚴格的控制先驗分佈 z)。在此基礎上,為了找到更好用作生成的先驗分佈 z,在 AnoGAN 的基礎上提出了 Efficient-GAN-Anomaly [2] 同樣由於做個一次重新對映導致計算成本上也是龐大的。
GANomaly 算是在前兩篇文章的基礎上做了一次突破,不再比較影象分佈了,而是轉眼到影象編碼的潛在空間下進行對比。對於正常的資料,編碼解碼再編碼得到的潛在空間和第一次編碼得到的潛在空間差距不會特別大。但是,在正常樣本訓練下的 AE 用作從未見過的異常樣本編碼解碼時,再經歷兩次編碼過程下往往潛在空間差距是大的。
當兩次編碼得到的潛在空間差距大於一定閾值的時候,我們就判定樣本是異常樣本,這就是 GANomaly 的思路。我們以此對比一下以 GAN 為發展下的異常檢測模型,模型結果如下,上述已對其做了一定的分析。

GANomaly 的優勢總結一下:
-
半監督異常檢測:編碼器-解碼器-編碼器流水線內的新型對抗自動編碼器,捕獲影象和潛在向量空間內的訓練資料分佈;
-
功效:一種有效且新穎的異常檢測方法,可在統計和計算上提供更好的效能。
GANomaly模型
我們還是先看一下模型框架:

GANomaly 模型框架是蠻清晰的,整個框架由三部分組成:
GE(x),GD(z) 統稱為生成網路,可以看成是第一部分。這一部分由編碼器 GE(x) 和解碼器 GD(z) 構成,對於送入資料 x 經過編碼器 GE(x) 得到潛在向量 z,z 經過解碼器 GD(z) 得到 x 的重構資料 x̂ 。
模型的第二部分就是判別器 D,對於原始影象 x 判為真,重構影象 x̂ 判為假,從而不斷最佳化重構影象與原始影象的差距,理想情況下重構影象與原始影象無異。
模型的第三部分是對重構影象 x̂ 再做編碼的編碼器 E(x̂) 得到重構影象編碼的潛在變數 ẑ。
在訓練階段,整個模型均是透過正常樣本做訓練。也就是編碼器 GE(x),解碼器 GD(z) 和重構編碼器 E(x̂),都是適用於正常樣本的。
當模型在測試階段接受到一個異常樣本,此時模型的編碼器,解碼器將不適用於異常樣本,此時得到的編碼後潛在變數 z 和重構編碼器得到的潛在變數 ẑ 的差距是大的。我們規定這個差距是一個分值 ,透過設定閾值 ϕ,一旦 A(x)>ϕ 模型就認定送入的樣本 x 是異常資料。
,透過設定閾值 ϕ,一旦 A(x)>ϕ 模型就認定送入的樣本 x 是異常資料。
網路損失
對於模型的最佳化,全是透過正常樣本實現的,網路損失也可分為三部分。標準 GAN 的損失大家相比都很清楚了,這裡不重覆寫。對於第一部分的生成網路下,文章給定了一個重構誤差損失,用於在畫素層面上減小原始影象和重構影象的差距。

對於第二部分判別器下,設定了一個特徵匹配誤差,用於在影象特徵層方面做最佳化,這部分損失其實已經在很多文章中都用到過。

對於第三部分重構影象編碼得到的潛在變數 ẑ ,這部分對於正常資料而言,希望得到的 ẑ 與原始資料直接編碼得到的 z 無差別最好,也就是對於最好的得分判斷,對於正常資料而言理想狀態下希望 。當然這是最理想的狀態,但是對於正常資料還是希望 A(x) 越小越好,所以引入了一個潛在變數間的誤差最佳化。
。當然這是最理想的狀態,但是對於正常資料還是希望 A(x) 越小越好,所以引入了一個潛在變數間的誤差最佳化。

訓練過程中只有正例樣本參與,模型只對正例樣本可以做到較好的編碼解碼,所以送入負例樣本在編解碼下會出現編碼得到的潛在變數差異大從而使得差距分值 A(x) 大,判斷為異常。對於模型,整個損失函式可以表示為:

這裡的 ωadv,ωcon,ωenc 是調節各損失的引數,可以根據具體實驗設定。
模型測試
模型測試過程中以正負樣例 D̂ 混合輸入,對於測試樣本下的得分 S 可記為 具體的判斷異常分數進行一個歸一化處理將其整合到 [0,1] 之間。
具體的判斷異常分數進行一個歸一化處理將其整合到 [0,1] 之間。

這裡的![]() 就是最終的異常得分,對於正常樣本理論上希望
就是最終的異常得分,對於正常樣本理論上希望 ,對於異常樣本理論上希望
,對於異常樣本理論上希望 。需要一個閾值 ϕ 來衡量這個標準,經過原始碼分析,一般的 ϕ=0.2 可以根據實際專案需要對 ϕ 做調整。
。需要一個閾值 ϕ 來衡量這個標準,經過原始碼分析,一般的 ϕ=0.2 可以根據實際專案需要對 ϕ 做調整。
GANomaly實驗
實驗在 MNIST,CIFAR10 上選取部分類別做正樣本,選取一些類別作異常樣本,測試模型是否能夠檢測出異常樣本並給出準確率。文章的衡量標準是以 AUC 為判斷。實驗對比了三種以 GAN 做異常檢測的模型以及 VAE 的結果,透過 AUC 分析可以看出 GANomaly 取得了不錯的優勢。

實驗還對大件行李異常資料集(University Baggage Anomaly Dataset – (UBA))做了實驗,資料集包括 230275 個影象塊,影象從完整的 X 射線影象中提取,異常類別(122803)有 3 個子類 – 刀(63,496),槍(45,855)和槍元件(13,452),對於另一個資料集選擇了槍械檢測(FFOB)。

對於潛在變數的選取,以及超參的確定也透過實驗選取:

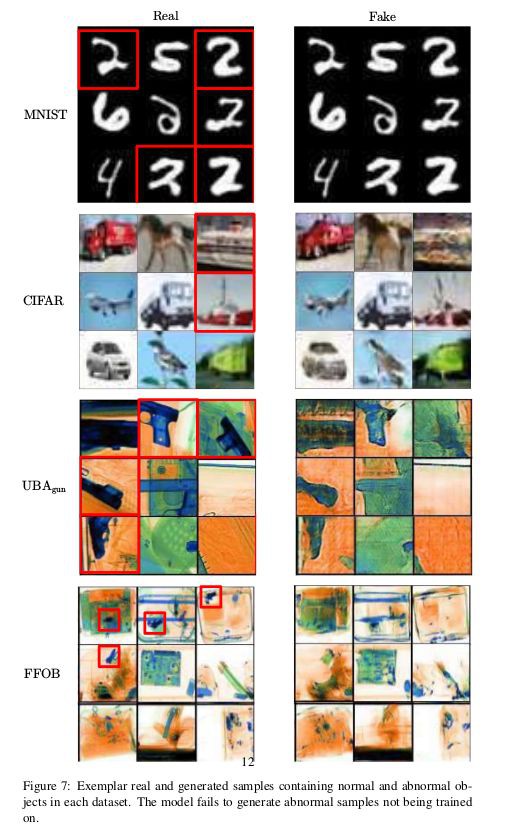
最後來看一下正常樣本和異常樣本重構的對比,可以看出異常樣本在重構上已經和原始有了較大的差別了,所以編碼得到的潛在變數自然會產生差異,從而判斷出異常。
總結
GANomaly 以編碼器-解碼器-編碼器設計模型,透過對比編碼得到的潛在變數和重構編碼得到的潛在變數差異,從而判斷是否為異常樣本。文章在無異常樣本訓練模型的情況下實現了異常檢測,對於很多場景都有很強的實際應用意義。個人感覺文章對於異常分數的計算和判斷可再進一步最佳化,從而實現更好的異常檢測效果。
參考文獻
[1]. Thomas Schlegl, Philipp Seebock, Sebastian M. Waldstein, Ursula Schmidt-Erfurth, and Georg Langs. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 10265 LNCS:146– 147, 2017.
[2]. Houssam Zenati, Chuan Sheng Foo, Bruno Lecouat, Gaurav Manek, and Vijay Ramaseshan Chandrasekhar. Efficient gan-based anomaly detection. arXiv preprint arXiv:1802.06222, 2018.
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:
 #投 稿 通 道#
#投 稿 通 道#
讓你的論文被更多人看到
如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準:
• 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向)
• 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結
• PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱:
• 投稿郵箱:hr@paperweekly.site
• 所有文章配圖,請單獨在附件中傳送
• 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 下載論文 & 原始碼
