百度《資料分析之道》目錄:
-
什麼是資料分析(道)
–資料分析是什麼?
–什麼是做好資料分析的關鍵?
–分析要思考業務,尤其接地氣
–分析要言之有物,行之有效
-
資料分析方法(術)
-
常見統計陷阱
內容摘要:
1)資料分析是什麼?
-
字面拆解: 資料 + 分析
-
有骨有肉方成一個人
–分析是骨架(主)
–資料是血肉(附) -
常見錯誤
–只有資料:機器報表不行麼?
–只有分析:你是瞎猜的吧?
2)什麼是做好資料分析的關鍵?
-
資料分析的核心:思路 > 方法
–思路:業務調研+邏輯思考+創新靈感+可行建議
–方法:彙總統計,Make it Simple(切忌喧兵奪主) -
資料分析的價值與定位
–百度的T序列不重視資料分析(資料分析的能力難以評價)
–麥肯錫一個分析報告賣了上千萬(僅有簡單統計)
–資料分析對一個企業有巨大價值,作用於業務發展的前(探索)期或階段性改進期(顛覆創新),先有資料分析,才能定業務模型,再後是建模最佳化(機器學習) -
資料分析人才
–同樣的資料,仁者見仁智者見智,分析人才的不可複製性
–做好資料分析的人不一定能當老大,但至少能當軍師

資料分析 之道


資料分析是什麼?
字面拆解: 資料 + 分析
有骨有肉方成一個人
–分析是骨架(主)
–資料是血肉(附)
常見錯誤
–只有資料:機器報表不行麼?
–只有分析:你是瞎猜的吧?

什麼是做好資料分析的關鍵?
資料分析的核心:思路 > 方法
–思路:業務調研+邏輯思考+創新靈感+可行建議
–方法:彙總統計,Make it Simple(切忌喧兵奪主)
資料分析的價值與定位
–百度的T序列不重視資料分析(資料分析的能力難以評價)
–麥肯錫一個分析報告賣了上千萬(僅有簡單統計)
–資料分析對一個企業有巨大價值,作用於業務發展的前(探索)期或階段性改進期(顛覆創新),先有資料分析,才能定業務模型,再後是建模最佳化(機器學習)
資料分析人才
–同樣的資料,仁者見仁智者見智,分析人才的不可複製性
–做好資料分析的人不一定能當老大,但至少能當軍師

分析要思考業務,尤其要接地氣
資料分析要輕方法,重調研
–方法上,基本統計即可
–調研上,親臨一線去詢問、瞭解實際情況,切近“資料空想”
–只有熟悉業務,才能提供有價值的分析和建議

客戶流失僅僅是推廣效果不夠理想嗎?

分析要言之有物,行之有效
資料分析,我們真的是僅僅想分析麼? 價值
–分析報告的及格線是“言之有物” — 事實
–優秀線是“振聾發聵”或“醍醐灌頂” — 分析
–滿分線是產生了切實有效的行動方案 — 建議
分析實體:我們處於市場領先地位,針對次位的競爭對手近期發展進行資料分析
–及格線:競爭對手發展勢頭很猛,市場份額怎樣變化
–優秀線:雖然競爭對手近期勢頭髮展很猛,但實際上他突出的優勢在X,劣勢在Y,未來可能會採取什麼行動,同時市場上的其它競爭對手也不容忽視
–滿分線:針對於競爭對手的可能動作,我們有如下方面需要改進:加強優勢A、B、C,與X達成進一步戰略合作關係,並收購Y等等

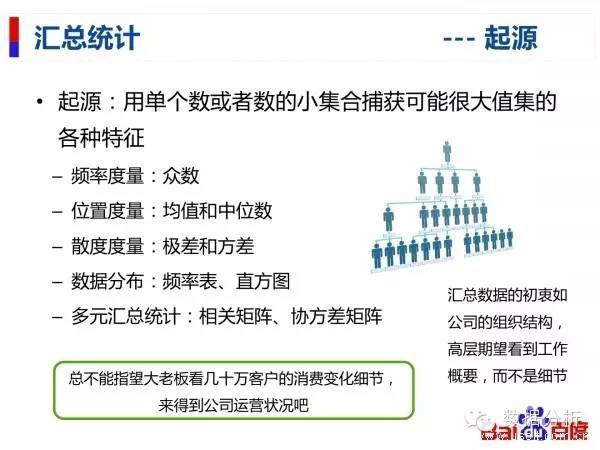
彙總統計
起源:用單個數或者數的小集合捕獲可能很大值集的各種特徵
–頻率度量:眾數
–位置度量:均值和中位數
–散度度量:極差和方差
–資料分佈:頻率表、直方圖
–多元彙總統計:相關矩陣、協方差矩陣

彙總資料指標的設計,源於非常樸素的思想
標準差:想設計一個指標,可以用來衡量資料集合的發散性,經過如下思考
–每個樣本的偏差累加就可以衡量 (real num – mean)加和
–偏差較大的值應該具有更大的權重 (real num – mean)^2
–集合中數字越多,方差越大,應該與集合大小無關 Mean((real num – mean)^2)
–量綱與原始資料不同,無法比 Sqrt(Mean((real num – mean)^2))
–最終結果,RMSE

彙總統計 — 需要多少樣本
在美國總統選舉的各種民意測驗中,關於支援率的一個常用標準是置信度為95%(誤差在+-2.5%以內,置信區間寬度為5%),那麼要達到這樣的標準需要多少人呢?
計算出N=1067,至少要一千個樣本以上,才能滿足需求
–Z0.025=1.96, 透過R陳述句 qnorm(0.025, low=F)得到
–n是樣本數量,n越大,置信區間越小
–p是真實的機率,p=0.5時候,p(1-p)最小,所需n最大
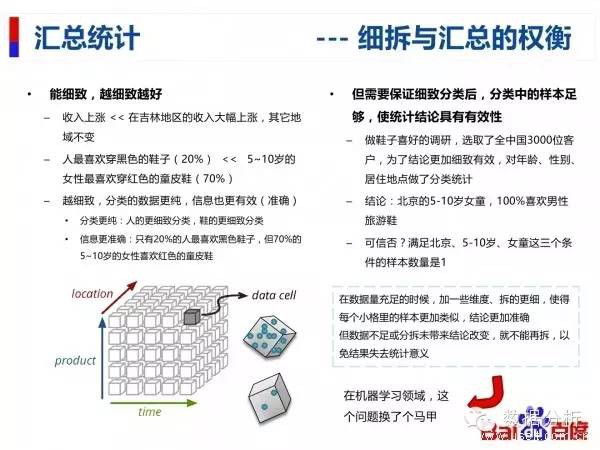
彙總統計 — 細拆與彙總的權衡
在資料量充足的時候,加一些維度、拆的更細,使得每個小格裡的樣本更加類似,結論更加準確但資料不足或分拆未帶來結論改變,就不能再拆,以免結果失去統計意義。

OLAP 概念 — 彙總統計的極致工具

機器學習 — 模型為什麼work?
為什麼存在實體“毛澤東抽煙比林彪不抽煙活的久”,還要勸人不要抽煙?
–機率分佈問題,“人事”與“天命”
–雖然選擇健康的生活方式(盡人事),我們也得聽天命(自己是正態曲線的好尾巴,還是壞尾巴),但是天命整體分佈可以變得更好(正態曲線的中軸向好的一面偏移)
如果沒有附加的抽煙資訊,如何從一組壽齡資料中作預測?
–標的:MSE做為評價指標,MSE越小越好
–方法:資料為正態分佈的話,中位數(即波峰)做為預測值使得MSE最小
透過如上兩點,證明抽煙資訊對預測是有效的,如果一個人抽煙,那麼我們預測他活到70歲,否則75歲
如果再多一個酗酒的資訊呢?



精心挑選的平均數
實體:小區業主申請減稅 vs 賣房子
當資料分佈呈現正態分佈特點(鐘形的曲線)時,均值、中位數、眾數都落在相同的點上。而資料分佈成有偏差的特徵(類似於滑梯)時,那麼均值、眾數、中位數就相差甚遠了。
以書思今,學以致用
–分佈與平均數一樣重要
–兩個特例往往使得資料的統計結果產生很大的變化

無所不能的圖形
同樣一份資料,2010年的前6個月,使用產品的客戶數量由最初的2w,以每個月100個的速度增長。

缺失或不匹配的比較
實體1(缺失的比較)
–臨床顯示,本藥品在10分鐘內可以殺死5w個感冒病毒
–資料因為缺失了比較物件,而毫無意義
實體2(不匹配的比較)
–美國海軍的死亡率是0.9%, 而同時期紐約市民的死亡率是1.6%,得出結論參軍是很安全的。
–比較物件不明確、或者根本不可比,也是常見的
以書思今,學以致用
–為什麼評估策略效果要有對照組?

偏差的抽樣
實體
–10個硬幣拋1000次,總會出現10個正面或9個正面的情況
–全國人民喜聞樂見油價上漲,水價聽證會大家紛紛反饋價格上漲影響不大
–採用有偏差的樣本,可以產生任何人需要的任何結果
在抽樣統計的時候,要充分思考抽樣的過程對樣本造成了怎樣的偏差,以及這個偏差對我們的結論有什麼影響
以書思今,學以致用
–分層抽樣

掛羊頭賣狗肉的推理
實體
–公司與工會發生了摩擦,於是公司進行了一項“調查”來統計多少職員對工會不滿。公司公佈了這樣的結論:“大多數(78%)的職員反對工會,所以有必要取消工會。”
–360打官司老敗訴,騰訊打官司總勝訴,周鴻禕:“真的是東方不敗!與騰訊強大的法務相比,我們實力不濟,自愧不如!”
最普遍的表現是將看上去極像,而完全不同的兩件事混淆在一起,得出了似是而非的推理。
笑一下
–小品《賣拐》中“腳麻”的橋段






轉自: Useit知識庫;原文連結:http://www.useit.com.cn/thread-11532-1-1.html;
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
END
關聯閱讀:
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
80%的運營註定了打雜?因為你沒有搭建出一套有效的使用者運營體系
合作請加qq:365242293
更多相關知識請回覆:“ 月光寶盒 ”;
資料分析(ID : ecshujufenxi )網際網路科技與資料圈自己的微信,也是WeMedia自媒體聯盟成員之一,WeMedia聯盟改寫5000萬人群。

