導讀:本文作者深入瞭解高可用架構釋出的360的pika解讀後,發覺美圖團隊此前開源的twemproxy元件有更多先進的優勢,特國慶節總結了相關技術的解讀,全面介紹相關的系統服務體系及眾多強大的功能。作為網際網路的從業人士,有興趣瞭解Redis及 Memcached的高階使用的,可以詳細閱讀本文。
林添毅,美圖技術經理, 主要負責 NoSQL/訊息佇列/中介軟體和區塊鏈基礎服務相關研發。對分散式快取和高可用架構設計方面有較為深入地研究,帶領團隊完成了美圖快取以及訊息佇列服務化。在加入美圖之前,曾就職於新浪微博架構平臺從事基礎服務的研發。
摘要
美圖在 2017 年下半年開始計劃做 Redis/Memcached 資源 PaaS 平臺,而 PaaS 化之後面臨一個問題是如何實現資源縮容/擴容對業務無感,為瞭解決這個問題,美圖技術團隊於 17 年 11 月引入 twemproxy 作為資源閘道器。
但是長期的實踐中,其開源版本不能完全適應美圖的實際情況,其主要存在單執行緒模型無法利用多核,效能不佳;配置無法線上 Reload ;Redis 不支援主從樣式;無延時指標等問題,所以美圖技術團隊對其進行了相應的改造。我們基於之上實現了多行程以及配置線上更新的功能,同時增加了一些延時的相關監控指標。
本文將為大家詳細講解 twemproxy 實現以及相應地改造,希望能給其他的技術團隊提供一些可以借鑒的經驗。
為什麼要選擇 twemproxy
twemproxy 是一款由 twitter 開源的 Redis/Memcached 代理,主要標的是減少後端資源的連線數以及為快取橫向擴充套件能力。 twemproxy 支援多種 hash 分片演演算法,同時具備失敗節點自動剔除的功能。除此之外,其他比較成熟的開源解決方案還有 codis,codis 具備線上的 auto-scale 以及友好的後臺管理,但整體的功能更接近於 Redis Cluster,而不是代理。美圖這邊需要的是一個 Redis 和 Memcached 協議類 PaaS 服務的代理(閘道器),所以我們最終選擇了 twemproxy。
twemproxy 實現
twemproxy 主要的功能是解析使用者請求後轉發到後端的快取資源,成功後在把響應轉發回客戶端。
程式碼實現的核心是三種連線物件:
-
proxy connection, 用來監聽使用者建立連線的請求,建立連線成功後會對應產生一個客戶端連線;
-
client connection,由建連成功後產生,使用者讀寫資料都是透過 client;connection 解析請求後,根據 key 和雜湊規則選擇一個 server 進行轉發;
-
server connection,轉發使用者請求到快取資源並接收和解析響應資料轉回 client connection,client connection 將響應傳回到使用者。
三種連線的資料流向如下圖:
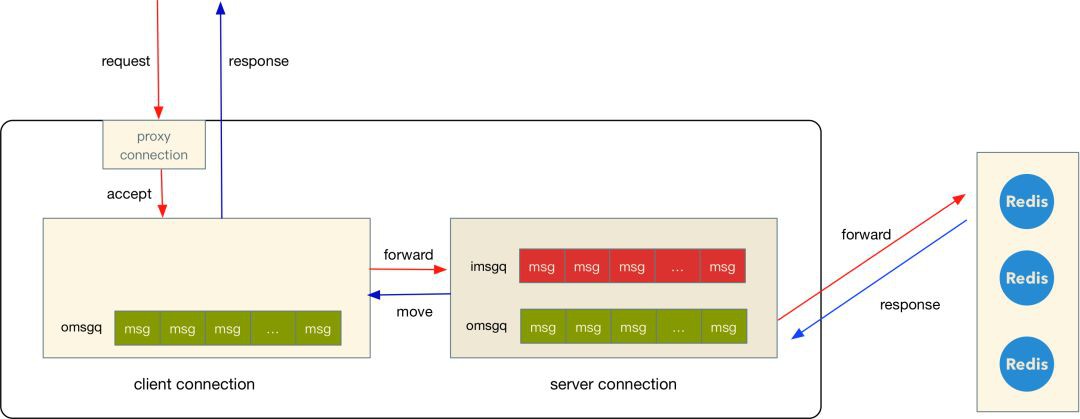
(上圖的 client connection 之所以沒有 imsgq 是因為請求解析完可以直接進入 server 的 imsgq)
-
使用者透過 proxy connection 建立連線,產生一個 client connection;
-
client connection 開始讀取使用者的請求資料,並將完整的請求根據 key 和設定的雜湊規則選擇 server, 然後將這個請求存放到 server 的 imsgq;
-
接著 server connection 傳送 imsgq 請求到遠端資源,傳送完成之後(寫 tcp buffer) 就會將 msg 從 imsgq 遷移到 omsgq,響應回來之後從 omsgq 佇列裡面找到這個對應的 msg 以及 client connection;
-
最後將響應內容放到 client connection 的 omsgq,由 client connection 將資料發送回客戶端。
上面提到的使用者請求和資源響應的資料都是在解析之後放到記憶體的 buf 裡面,在 client 和 server 兩種連線的內部流轉也只是指標的複製(官網 README 裡面提到的 Zero Copy)。這也是 twemproxy 單執行緒模型在小包場景能夠達到 10w qps 的原因之一,幾乎不複製記憶體。
但對於我們來說,當前開源版本存在幾個問題:
-
單執行緒模型無法利用多核,效能不夠好,極端情況下代理和資源需要 1:1 部署;
-
配置無法線上 Reload,twitter 內部版本應該是支援的,單元測試裡面有針對 reload 的 case,PaaS 場景需要不斷更新配置;
-
Redis 不支援主從樣式(Redis 在作為快取的場景下確實沒必要使用主從),但部分場景需要;
-
資料指標過少,延時指標完全沒有。
多行程版本
針對以上的幾個問題,美圖的開源版本都做了一些修改,最核心的功能是多行程和配置線上 reload。改造後整體行程模型類似 Nginx, 簡單示意圖如下:

master 的功能就是管理 worker 行程,不接收和處理使用者請求。如果 worker 行程異常退出,那麼 master 則會自動拉起新的行程來替代掛掉的老行程。除此之外,master 還會接收來自使用者的幾種訊號:
-
SIGHUP, 重新載入新配置
-
SIGTTIN,提高日誌級別, 級別越高日誌越詳細
-
SIGTTOU,降低日誌級別,級別越低日誌越少
-
SIGUSR1,重新開啟日誌檔案
-
SIGTERM,優雅退出,等到一段時間後退出
-
SIGINT,強制退出
同時還增加了幾個全域性配置:

除了worker_shutdown_timeout其他幾個配置應該比較好理解。worker_shutdown_timeout 是配置老 worker 在收到退出訊號後多長時間退出。這個配置是跟多行程實現相關的引數,我們是透過啟動新行程替代老行程的方式來實現配置以及行程數目的線上修改,所以這個配置就是用來指定老行程的保留時間。
reuse port
在 reuse port 之前,多執行緒/行程服務監聽建連請求一般有兩種方式:
-
由一個執行緒負責接收所有的新連線,其他執行緒服務只負責建立連線之後的處理。這種方式的問題是在短連線場景下,這個 accept 執行緒很容易成為瓶頸(單核我們這邊測試一般是在 4w+/s 左右);
-
所有的執行緒/行程都同時 accept 同一個監聽的檔案控制代碼。 這種方式的問題是在高負載的場景下,不同執行緒/行程的喚醒會不均勻,另外會有驚群的效果(accept/epoll 在新版本核心中也有解決驚群問題)。
reuse port 的主要作用就是允許多個 socket 同時監聽同一個埠,同時不會存在建立連線不均勻的問題。 使用 reuse port 也相當簡單,只需要把監聽透過一個埠的 socket 都設定上 reuse port 標識即可。

雖然 reuse port 是在 linux 3.9 才被合併進來,但有 backport 到更早之前的版本(至少我們在使用的 2.6.32 是有的),很多部落格在這點上有些誤導。另外,在 reload 時候也不能簡單將老的監聽關閉,會導致 tcp backlog 裡面這些三次握手成功但未 accept 的連線丟失,業務在這些連線上傳送資料則會收到 rst 包。
我們解決這個問題的方式是讓監聽連線都在 master 行程上面建立和維護,worker 行程只是在 fork 之後直接繼承監聽的連線,所以在 reload 的時候 master 就可以將老 worker 裡面的監聽連線遷移到新的 worker, 來保證 tcp backlog 裡面的資料不會丟失。
具體程式碼見: nc_process.c#L172, 這種方式能夠在行程數不變或者增多的場景下保證 backlog 裡面的資料不會丟,行程數縮減時還是會丟失一些。
Redis 主從樣式
在原生的 twemproxy 裡面是不支援 Redis 主從樣式的,這個應該主要是因為 twemproxy 把 Redis/Memcached 當做是快取而不是儲存,所以這種主從結構實際上是沒有必要的,運維也比較簡單。但是對於我們內部業務來說,有些並不是全部都是作為快取,所以就需要這種主從結構。配置也比較簡單:

如果檢測到 server 的名字為 master 則認為該實體為主,一個池子裡面只允許一個主,否則認為配置不合法。
統計指標
個人覺得 twemproxy 存在的另外一個問題是延時指標完全缺失,這個對於排查問題以及監控報警是比較不利的。針對這個問題,我們增加了兩種延時指標:
-
request latency, 指的是客戶端請求到傳回的延時, 包含 twemproxy 內部以及 server 的耗時,這個指標更加接近業務的耗時;
-
server latency, 指的是 twemproxy 請求 server 的耗時,這個可以理解為 Redis/Memcached server 的耗時。
在偶發問題的場景下,根據兩種延時可以定位是 twemproxy、server 還是客戶端的問題(比如 GC)導致慢請求,另外也可以慢請求的比例進行監控報警。這兩種指標是透過 bucket 的方式來記錄的,比如 <1ms 的數目,<10ms 的數目等等。
仍然存在的問題
-
在 worker 數目減少的場景下,被銷毀的老 Worker 的 tcp backlog 會丟失會導致一些連線超時;
-
unix socket 沒有 reuse port 類似的機制,所以實際上還是單行程但可以支援線上 reload;
-
不支援 Memcached 二進位制協議,幾年前有人提供相關 PR 但一直都沒有進入 master;
-
客戶端的最大連線數有配置但實際上不生效,這個功能我們後續會加上;
-
命令支援不全(主要是沒有 key 以及一些 blocking 的指令);
-
reload 期間新老行程的配置不一致會可能會導致臟資料。
效能壓測
以下資料是在長連線小包場景下壓測得出,主要是驗證多行程版本是否跟預期的一致。沒有其他硬體到達瓶頸之前,效能可以隨著 CPU 核數線性增長。
壓測環境如下:
-
CentOS 6.6
-
CPU Intel E5-2660 32 邏輯核
-
記憶體 64G
-
兩張千兆網絡卡做 bond0

單個 worker 場景和 twemproxy 改造之前的效能差不多,在 10w 左右。隨著 worker 數目增加,後面效能和 worker 基本是保持線上增長,符合預期。8 核以上的瓶頸是 bond0 樣式下包接收不均勻導致單網絡卡效能達到瓶頸,資料無法作為參考。上面的資料也是我們自己環境的壓測資料,大家可以自行驗證。如果是多網絡卡需要註意系結中斷或者多佇列到多個 CPU, 避免 CPU0 軟中斷處理成為瓶頸。
最後
多行程版本的 twemproxy 實現上算是比較簡單,但過程中發現並修複不少 twemproxy 細節問題(一部分是使用方報告),比如 mbuf 一旦分配就不會收縮導致記憶體上漲之後不再下降的問題等等。很多功能細節我們也在不斷最佳化,我們也只維護 Github 上的一個版本。
程式碼地址: https://github.com/meitu/twemproxy
除此之外,我們團隊目前也開源其他一些專案:
-
golang 版本的 kafka consumer group
-
php 版本的 kafka consumer group
-
基於以太坊的 DPoS 實現
後續還會開源更多的東西,歡迎大家多多關註~
最後感謝相關程式碼貢獻者: @ruoshan @karelrooted @Huang-lin @git-hulk
取用
1 twitter/twemproxy https://github.com/twitter/twemproxy
2 meitu/twemproxy https://github.com/meitu/twemproxy
3 twmeporxy binary memcached https://github.com/twitter/twemproxy/tree/binary_memcache
4 soreuseport: TCP/IPv4 implementation https://lwn.net/Articles/542718/
5 The SO_REUSEPORT socket option https://lwn.net/Articles/542629/
相關閱讀:

高可用架構
改變網際網路的構建方式

長按二維碼 關註「高可用架構」公眾號
