小螞蟻說:
2018年上半年,螞蟻金服決定基於 Istio 訂製自己的 ServiceMesh 解決方案,併在6月底正式對外公佈了 SOFAMesh,詳情可直接點選之前的文章檢視: 大規模微服務架構下的Service Mesh探索之路 。
在 SOFAMesh 的開發過程中,針對遇到的實際問題,我們給出了一套名為 x-protocol 的解決方案,本文將會對這個解決方案進行詳細的講解,後面會有更多內容,歡迎持續關註本系列文章。
前言
x-protocol 的定位是雲原生、高效能、低侵入性的通用 Service Mesh 落地方案,依託 Kubernetes 基座,利用其原生的服務註冊和服務發現機制,支援各種私有 RPC 協議低成本、易擴充套件的接入,快速享受 Service Mesh 所帶來的紅利。
具體解決的問題包括:
-
多通訊協議支援問題,減少開發工作量,簡單快捷的接入新協議
-
儘量提升效能,提供更靈活的效能與功能的平衡點選擇,滿足特定高效能場景
-
相容現有 SOA 體系,提供透過介面進行訪問的方式,實現不修改業務程式碼也能順利接入 Service Mesh
-
支援單行程多服務的傳統 SOA 程式,可以在微服務改造之前,先受益於 Service Mesh 帶來的強大功能
在本系列文章中,我們將對此進行詳細的講解,首先是“DNS通用定址方案”。
SOFA 開源網站:
http://www.sofastack.tech/
背景和需求
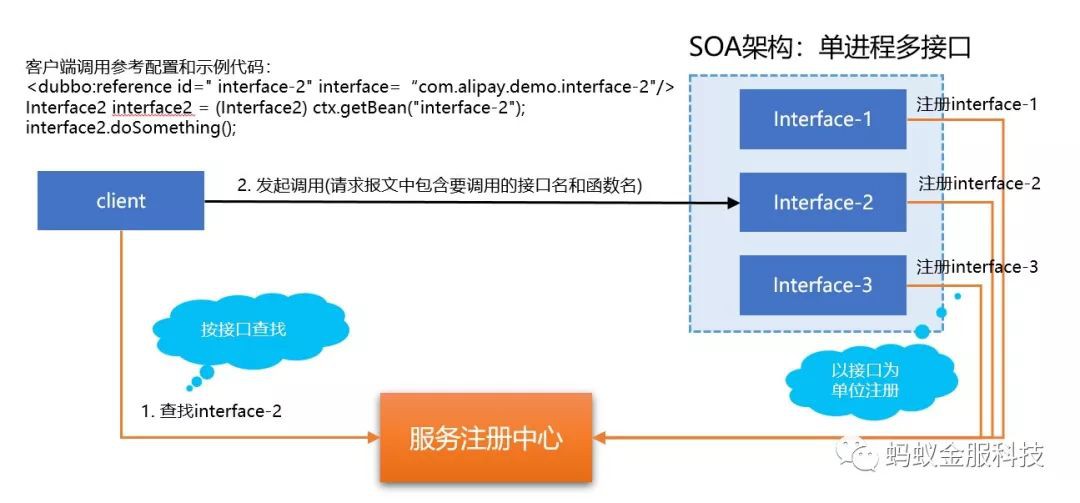
SOA的服務模型
在 SOFAMesh 計劃支援的 RPC 框架中,SOFARPC、HSF、Dubbo 都是一脈相承的 SOA 體系,也都支援經典的SOA服務模型,通常稱為”單行程多服務”,或者叫做”單行程多介面”。(備註:由於服務一詞使用過於頻繁,下文都統一稱為介面以便區分)
SOA 標準的服務註冊,服務發現和呼叫流程如下:
-
在單個 SOA 應用行程內,存在多個介面
-
服務註冊時,以介面為單位進行多次獨立的服務註冊
-
當客戶端進行呼叫時,按照介面進行服務發現,然後發起呼叫
當我們試圖將這些 SOA 架構的應用搬遷到 ServiceMesh 時,就會遇到服務模型的問題:微服務是單服務模型,也就是一個行程裡面只承載一個服務。以 k8s 的服務註冊為例,在單行程單服務的模型下,服務名和應用名可以視為一體,k8s 的自動服務註冊會將應用名作為服務註冊的標示。
這就直接導致了 SOA 模型和微服務模型的不匹配問題:
-
SOA 以介面為單位做服務註冊和服務發現,而微服務下是服務名
-
SOA 是”單行程多介面”,而微服務是”單行程單服務”
一步接一步的需求
-
先上車後補票
最理想的做法當然是先進行微服務改造,實現微服務拆分。但是考慮到現有應用數量眾多,我們可能更願意在大規模微服務改造之前,先想辦法讓這些應用可以執行在 ServiceMesh 下,提前受益於 ServiceMesh 帶來的強大功能。因此,我們需要找到一個合適的方案,讓 ServiceMesh 支援沒有做微服務改造依然是”單行程多介面”形式的傳統 SOA 應用,所謂”先上車後補票”。 -
不修改程式碼
考慮到原有的 SOA 應用,相互之間錯綜複雜的呼叫關係,最好不要修改程式碼,即保持客戶端依然透過介面名來訪問的方式。當然,SOA 架構的客戶端 SDK 可能要進行改動,將原有的透過介面名進行服務發現再自行負載均衡進行遠端呼叫的方式,精簡為標準的 ServiceMesh 呼叫(即走Sidecar),因此修改SDK依賴包和重新打包應用是不可避免。 -
支援帶特殊字元的介面名
k8s 的服務註冊,Service 名是不能攜帶”.“號的。而 SOA 架構下,介面名有時出於管理方便,有可能是加了域名字首,如“com.alipay.demo.interface-2”。為了實現不修改原有程式碼,就只能想辦法支援這種帶特殊字元的介面名。
參考 Kubernetes 和 Istio
在進一步討論解決方案之前,我們先來看一下kubernetes 和 istio 中的標準請求定址方式。
(備註:過程稍顯複雜,涉及到k8s/istio的一些底層細節。但是瞭解這個過程對後續的理解非常重要,也可以幫助大家瞭解k8s和k8s的工作原理,強烈推薦閱讀。)
k8s下的DNS定址方式
在k8s下,如圖所示,假定我們部署了一個名為 userservice 的應用,有三個實體,分別在三個 pod 中。則應用部署之後,k8s 會為這個應用分配 ClusterIP 和域名,併在DNS中生成一條DNS記錄,將域名對映到ClusterIP:

當部署在 k8s 下的某個充當客戶端的應用發起請求時,如圖中的 HTTP GET請求,標的 URL 地址為 “http://userservice/id/1000221″。請求的定址方式和過程如下:
-
首先進行域名解析,分別嘗試解析“userservice”/“userservie.default.svc.cluster.local”等域名,得到 ClusterIP
-
然後客戶端發出請求的報文,標的地址為ClusterIP,源地址為當前客戶端所在的 pod IP(簡單起見,埠先忽略)
-
請求報文隨即被 kube-proxy 攔截,kube-proxy 根據 ClusterIP,拿到ClusterIP 對應的多個實際服務實體所在的 pod ip,取其中一個,修改標的地址為這個pod IP
-
請求報文最終就被髮送到服務實體所在的pod IP
應答回來的方式類似,userservice發出的應答報文會被 kube-proxy 攔截並修改為傳送到客戶端所在的 pod IP。
我們詳細看一下請求和應答全稱的四個請求包的具體內容(簡單起見繼續忽略埠):
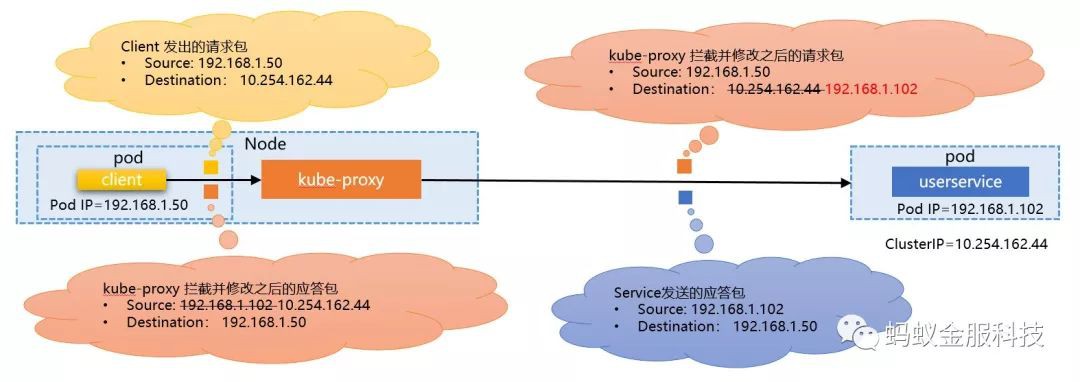
重點關註請求和應答報文的源地址和標的地址:
-
客戶端發出的請求,為“客戶端到 ClusterIP”
-
kube-proxy 攔截到請求後,將請求修改為“客戶端到伺服器端”
-
伺服器端收到請求時,表現為“客戶端到伺服器端”,ClusterIP 被kube-proxy 遮蔽
-
伺服器端傳送應答,因為收到的請求看似來自客戶端,因此應答報文為”伺服器端到客戶端”
-
應答報文被 kube-proxy 攔截,將應答修改為 “ClusterIP到伺服器端”
-
客戶端收到應答,表現為“ClusterIP 到伺服器端”,伺服器端 IP 被 kube-proxy 遮蔽
kube-proxy 在客戶端和伺服器端之間攔截並修改請求和應答的報文,聯通兩者,但各自遮蔽了一些資訊:
-
在客戶端看來它是在和 ClusterIP 互動,userservice 的具體伺服器端實體對客戶端是無感知的
-
在伺服器端看來,客戶端是直接在和它互動,ClusterIP 的存在對伺服器端是無感知的
更深入一步,看 kube-proxy 在兩個攔截和修改報文中的邏輯處理關係,即kube-proxy是如何在收到應答時正確的找回原有的 ClusterIP:

-
在攔截並修改請求報文之後,kube-proxy 會儲存報文修改的5元組對應關係(5元組指源 IP 地址,源埠,協議,目的地 IP 地址,目的地埠)
-
在收到應答報文後,根據應答報文中的5元組,在儲存的5元組對應關係中,找到對應資訊,得到原有的 ClusterIP 和埠,然後修改應答報文
總結,透過上述k8s下的定址方式,客戶端只需傳送帶簡單定址資訊的請求(如 “http://userservice/id/1000221” 中的“userservice” ),就可以定址到正確的伺服器端。這期間有兩個關註點:
-
透過 DNS,建立了域名和 ClusterIP 的關係。
對於客戶端,這是它能看到的內容,非常的簡單,域名、DNS 是非常容易使用的。 -
而透過 kube-proxy 的攔截和轉發,又打通了ClusterIP 和伺服器端實際的Pod IP
對於客戶端,這些是看不到的內容,不管有多複雜,都是k8s在底層完成,對客戶端,或者說使用者透明。
以客戶端的視角看來,這個DNS定址方式非常的簡單直白:

Istio的 DNS 定址方式
Istio的請求定址方式和普通 kubernetes 非常相似,原理相同,只是 kube-proxy被 sidecar 取代,然後 sidecar 的部署方式是在 pod 內部署,而且客戶端和伺服器端各有一個 sidecar。其他基本一致,除了圖中紅色文字的部分:
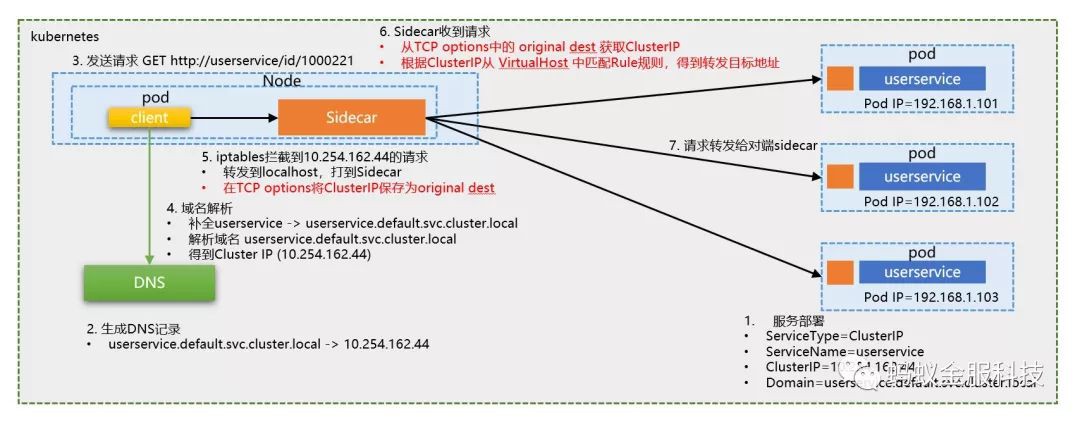
-
iptables 在劫持流量時,除了將請求轉發到 localhost 的 Sidecar 處外,還額外的在請求報文的 TCP options 中將 ClusterIP 儲存為 original dest。
-
在 Sidecar (Istio 預設是 Envoy)中,從請求報文 TCP options 的 original dest 處獲取 ClusterIP
透過TCP options 的 original dest,iptables就實現了在劫持流量到Sidecar的過程中,額外傳遞了 ClusterIP 這個重要引數。Istio為什麼要如此費力的傳遞這個 ClusterIP 呢?
看下圖就知道了,這是一個 Virtual Host 的示例, Istio 透過 Pilot 將這個規則傳送給 Sidecar/Envoy ,依靠這個資訊來匹配路由請求找到處理請求的cluster:

domains中,除了列出域名外,還有一個特殊的IP地址,這個就是 k8s 服務的 ClusterIP!因此,Sidecar可以透過前面傳遞過來的 ClusterIP 在這裡進行路由匹配(當然也可以從報文中獲取 destination 然後透過域名匹配)。
總結,Istio 延續了 k8s 的定址方式,客戶端同樣只需傳送帶簡單定址資訊的請求,就可以定址到正確的伺服器端。這期間同樣有兩個關註點:
-
透過DNS,建立了域名和ClusterIP的關係。
-
透過 ClusterIP 和 Pilot 下發給 Virtual Host 的配置,Sidecar 可以完成路由匹配,將 ClusterIP 和標的伺服器關聯起來
同樣,對於客戶端,這些是看不到的內容。
因此,以客戶端的視角看來,Isito的這個DNS定址方式同樣的簡單直白!
DNS通用定址方案具體介紹
解決問題的思路
在詳細講述了 k8s 和 istio 的 DNS 定址方案之後,我們繼續回到我們的主題,我們要解決的問題:
如何在不修改程式碼,繼續使用介面的情況下,實現在 Service Mesh 上執行現有的 Dubbo/HSF/SOFA 等傳統 SOA 應用?
這裡有一個關鍵點:k8s 的服務註冊是以基於 Service 或者說基於應用(app name),而我們的客戶端程式碼是基於介面的。因此,在 Virtual Host 進行路由匹配時,是不能透過域名匹配的。當然,這裡理論上還有一個思路,就是將介面註冊為 k8s Service。但是,還記得要支援介面特殊字元的需求嗎?帶點號的介面名,k8s 是不能接受它作為 Service Name 的,直接堵死了將介面名註冊到 k8s Service 的道路。
這樣,我們就只有一條路可以走了:效仿 istio 的做法,透過 ClusterIP 匹配!
而要將介面名(如”com.alipay.demo.interface-1”)和 ClusterIP 關聯,最簡單直接的方式就是打通DNS :
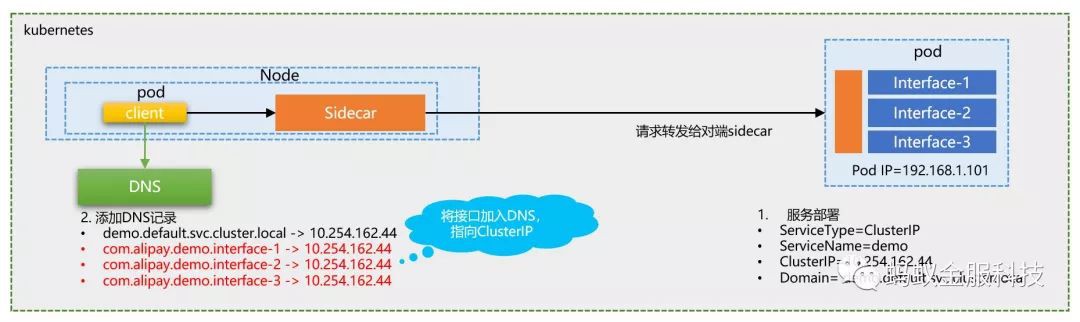
只需要在DNS記錄中,增加介面到 ClusterIP 的對映,然後就可以完全延續Istio的標準做法!其他的步驟,如域名解析到ClusterIP,iptables攔截並傳遞ClusterIP,sidecar讀取ClusterIP並匹配路由,都完全可以重用原有方案。
具體實現方案
實現時,我們選擇了使用 CoreDNS 作為 k8s 的 DNS 解決方案,然後透過 Service Controller 操作 CoreDNS 的記錄來實現 DNS 解析。
為了收集到 SOA 應用的介面資訊,我們還提供了一個 Register Agent 給 Service Controller 收集資訊。

詳細的實現方案,不在本文中重覆講述,請參閱我們之前的分享文章 SOFAMesh 的通用協議擴充套件 中的 DNS 定址方案一節。
(備註:暫時修改 CoreDNS 記錄的方式是直接修改 CoreDNS 的底層資料,不夠優雅。未來將修改為透過 CoreDNS 的 Dynamic updates API 介面進行,不過 CoreDNS 的這個API還在開發中,需要等待完成。)
單行程多介面問題的解決
上面的解決方案,在解決透過介面實現訪問的同時,也將”單行程多介面”的問題一起解決了:
-
原 SOA 應用上 k8s 時,可以註冊為標準的 k8s Service,獲取 ClusterIP。此時使用應用名註冊,和介面無關。
-
透過操作 CoreDNS,我們將該 SOA 應用的各個介面都新增為 DNS 記錄,指向該應用的 ClusterIP
-
當客戶端程式碼使用不同的介面名訪問時,DNS解析出來的都是同一個 ClusterIP,後續步驟就和介面名無關了
欠缺微服務改造帶來的限制
需要特別指出的是,DNS 通用定址方案雖然可以解決使用介面名訪問和支援單行程多介面的問題,但是這種方案只是完成了“定址”,也就是打通端到端的訪問通道。由於應用沒有進行微服務改造,部署上是依然一個應用(體現為一個行程,在 k8s 上體現為一個 Service)中包含多個介面,本質上:
-
服務註冊依然是以應用名為基礎,對應的 k8s service 和 service 上的 label也是應用級別
-
因此提供的服務治理功能,也是以 k8s 的 Service 為基本單位,包括灰度,藍綠,版本拆分等所有的 Vesion Based Routing 功能
-
這意味著,只能進行應用級別的服務治理,而不能繼續細分到介面級別
這個限制來源於應用沒有進行微服務改造,沒有按照介面將應用拆分為多個獨立的微服務,因此無法得到更小的服務治理粒度。這也就是我在2018年上半年,螞蟻金服決定基於 Istio 訂製自己的 ServiceMesh 解決方案,在6月底對外公佈了 SOFAMesh,詳情請見之前的文章: 大規模微服務架構下的Service Mesh探索之路 。
DNS通用定址方案總結
我們將這個方案稱為“DNS通用定址方案”,是因為這個方案真的非常的通用,體現在以下幾個方面:
-
對使用者來說,透過域名和 DNS 解析的方式來訪問,是非常簡單直白而易於接受的,同時也是廣泛使用的,適用於各種語言、平臺、框架。
-
這個方案延續了 k8s 和 istio 的做法,保持了一致的方式方式,對使用者提供了相同的體驗
-
這個定址方案,不僅僅可以用於 Dubbo、SOFA、HSF 等 RPC 框架往 Service Mesh 的遷移,也可以適用於基於 HTTP/REST 協議的 SOA 應用,甚至最傳統的 web 應用(例如 tomcat 下部署多個 war 包)遷移到Service Mesh
-
我們也在考慮在未來的 Serverless 專案中,將 Function 的定址也統一到這套方案中,而無需要求每個 Function 都進行一次服務註冊
概括的說,有了這套 DNS 通用定址方案,不管需要定址的物體是什麼形態,只要它部署在 Service Mesh 上,滿足以下條件:
-
有正常註冊為 k8s Service,分配有 ClusterIP
-
為物體(或者更細分的子物體)分配域名或子域名,然後新增到 DNS,解析到 ClusterIP
那麼我們的 DNS 通用定址方案,就可以工作,從而將請求正確的轉發到目的地。而在此基礎上,Service Mesh 所有的強大功能都可以為這些物體所用,實現我們前面的標的:在不修改程式碼不做微服務改造的情況下,也能提前受益於 Service Mesh 帶來的強大服務治理功能。

長按關註,獲取分散式架構乾貨
歡迎大家共同打造 SOFAStack https://github.com/alipay