

-
獲取系統root使用者所有能力賦值給容器;
-
掃描宿主機所有裝置檔案掛載到容器內。
lynzabo@ubuntu:~$ docker run --rm --name def-cap-con1 -d alpine /bin/sh -c "while true;do echo hello; sleep 1;done"
f216f9261bb9c3c1f226c341788b97c786fa26657e18d7e52bee3c7f2eef755c
lynzabo@ubuntu:~$ docker inspect def-cap-con1 -f '{{.State.Pid}}'
43482
lynzabo@ubuntu:~$ cat /proc/43482/status | grep Cap
CapInh: 00000000a80425fb
CapPrm: 00000000a80425fb
CapEff: 00000000a80425fb
CapBnd: 00000000a80425fb
CapAmb: 0000000000000000
lynzabo@ubuntu:~$
lynzabo@ubuntu:~$ docker exec def-cap-con1 ls /dev
core fd full mqueue null ptmx pts random shm stderr stdin stdout tty urandom zero ...總共15條
lynzabo@ubuntu:~$
lynzabo@ubuntu:~$ docker run --privileged --rm --name pri-cap-con1 -d alpine /bin/sh -c "while true;do echo hello; sleep 1;done"
ad6bcff477fd455e73b725afe914b82c8aa6040f36326106a9a3539ad0be03d2
lynzabo@ubuntu:~$ docker inspect pri-cap-con1 -f '{{.State.Pid}}'
44312
lynzabo@ubuntu:~$ cat /proc/44312/status | grep Cap
CapInh: 0000003fffffffff
CapPrm: 0000003fffffffff
CapEff: 0000003fffffffff
CapBnd: 0000003fffffffff
CapAmb: 0000000000000000
lynzabo@ubuntu:~$ docker exec pri-cap-con1 ls /dev
agpgart autofs bsg btrfs-control bus core cpu_dma_latency cuse dmmidi dri ecryptfs
...總共186條
lynzabo@ubuntu:~$
$ docker run --device=/dev/snd:/dev/snd …
$ docker run --cap-drop ALL --cap-add SYS_TIME ntpd /bin/sh
[root@VM_0_6_centos ~]# getpcaps 652
Capabilities for `652': = cap_chown,cap_dac_override,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_net_bind_service,cap_net_raw,cap_sys_chroot,cap_sys_time,...
[root@VM_0_6_centos ~]#
$ export DOCKER_CONTENT_TRUST=11
#include
profile docker-nginx flags=(attach_disconnected,mediate_deleted) {
#include
...
deny network raw,
...
deny /bin/** wl,
deny /root/** wl,
deny /bin/sh mrwklx,
deny /bin/dash mrwklx,
deny /usr/bin/top mrwklx,
...
}
$ sudo apparmor_parser -r -W /etc/apparmor.d/containers/docker-nginx
$ docker run --security-opt "apparmor=docker-nginx" -p 80:80 -d --name apparmor-nginx nginx12
$ docker container exec -it apparmor-nginx bash1
root@6da5a2a930b9:~# ping 8.8.8.8
ping: Lacking privilege for raw socket.
root@6da5a2a930b9:/# top
bash: /usr/bin/top: Permission denied
root@6da5a2a930b9:~# touch ~/thing
touch: cannot touch 'thing': Permission denied
root@6da5a2a930b9:/# sh
bash: /bin/sh: Permission denied
$ cat /boot/config-`uname -r` | grep CONFIG_SECCOMP=
CONFIG_SECCOMP=y
{
"defaultAction": "SCMP_ACT_ERRNO",
"archMap": [
{
"architecture": "SCMP_ARCH_X86_64",
"subArchitectures": [
"SCMP_ARCH_X86",
"SCMP_ARCH_X32"
]
},=
...
],
"syscalls": [
{
"names": [
"reboot"
],
"action": "SCMP_ACT_ALLOW",
"args": [],
"comment": "",
"includes": {
"caps": [
"CAP_SYS_BOOT"
]
},
"excludes": {}
},
...
]
}
$ docker run --rm \
-it \
--security-opt seccomp=/path/to/seccomp/profile.json \
hello-seccomp
testuser:231072:65536
lynzabo@ubuntu:~$ ps -ef | grep dockerd
root 1557 1 0 12:54 ? 00:05:08 /usr/bin/dockerd -H
fd://
lynzabo 36398 23696 0 21:41 pts/1 00:00:00 grep --color=auto dockerd
lynzabo@ubuntu:~$
lynzabo@ubuntu:~$ docker run --rm alpine id
Unable to find image 'alpine:latest' locally
latest: Pulling from library/alpine
4fe2ade4980c: Pull complete
Digest:
sha256:621c2f39f8133acb8e64023a94dbdf0d5ca81896102b9e57c0dc184cadaf5528
Status: Downloaded newer image for alpine:latest
uid=0(root) gid=0(root) groups=0(root),1(bin),2(daemon)...
lynzabo@ubuntu:~$
lynzabo@ubuntu:~$ id
uid=1000(lynzabo) gid=1000(lynzabo)
groups=1000(lynzabo)...
lynzabo@ubuntu:~$ docker run --rm --user 1000:1000
alpine id
uid=1000 gid=1000
lynzabo@ubuntu:~$
lynzabo@ubuntu:~$ sudo systemctl stop docker
lynzabo@ubuntu:~$
lynzabo@ubuntu:~$ sudo dockerd --userns-remap=default &
lynzabo@ubuntu:~$
lynzabo@ubuntu:~$ id dockremap
uid=123(dockremap) gid=132(dockremap) groups=132(dockremap)
lynzabo@ubuntu:~$
lynzabo@ubuntu:~$ grep dockremap /etc/subuid
dockremap:165536:65536
lynzabo@ubuntu:~$ grep dockremap /etc/subgid
dockremap:165536:65536
lynzabo@ubuntu:~$
lynzabo@ubuntu:~$ docker info
...
Docker Root Dir: /home/docker/165536.165536
...
lynzabo@ubuntu:~$
lynzabo@ubuntu:~$ ls -ld /home/docker/165536.165536
drwx------ 14 165536 165536 4096 Sep 17 21:44 /home/docker/165536.165536
lynzabo@ubuntu:~$ sudo ls -l /home/docker/165536.165536/
total 48
drwx------ 2 165536 165536 4096 Sep 17 21:44 volumes
drwx--x--x 3 root root 4096 Sep 17 21:44 containerd
drwx------ 2 165536 165536 4096 Sep 17 21:44 containers
drwx------ 3 root root 4096 Sep 17 21:44 image
drwxr-x--- 3 root root 4096 Sep 17 21:44 network
drwx------ 4 165536 165536 4096 Sep 17 21:44 overlay2
...
lynzabo@ubuntu:~$
lynzabo@ubuntu:~$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
lynzabo@ubuntu:~$
lynzabo@ubuntu:~$ docker run -it --rm -v /bin:/host/bin busybox /bin/sh
Unable to find image 'busybox:latest' locally
latest: Pulling from library/busybox
8c5a7da1afbc: Pull complete
Digest:
sha256:cb63aa0641a885f54de20f61d152187419e8f6b159ed11a251a09d115fdff9bd
Status: Downloaded newer image for busybox:latest
/ # id
uid=0(root) gid=0(root) groups=10(wheel)
/ #
/ # rm /host/bin/sh
rm: can't remove 'sh': Permission denied
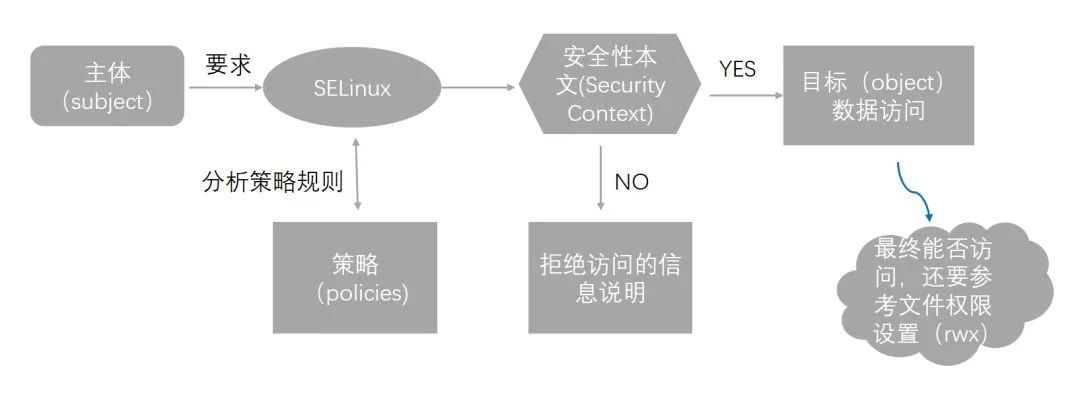
-
Enforcing樣式:將受限主體進入規則比對、安全本文比對,如果失敗,抵擋主體程式的讀寫行為,並且記錄這一行為。 如果成功,這才進入到rwx許可權的判斷。
-
Permissive樣式:不會抵擋主體程式讀寫行為,只是將該動作記錄下來。
-
Disabled的樣式:禁用SELinux,直接去判斷rwx。
# 檢視系統Selinux是否開啟,及當前樣式,policy
[lynzabo@localhost ~]$ sestatus
SELinux status: enabled
SELinuxfs mount: /sys/fs/selinux
SELinux root directory: /etc/selinux
Loaded policy name: targeted
Current mode: enforcing
Mode from config file: enforcing
Policy MLS status: enabled
Policy deny_unknown status: allowed
Max kernel policy version: 28
[lynzabo@localhost ~]$
# Docker開啟Selinux
[root@localhost conf]# ps -ef|grep dockerd
root 4401 1 0 08:15 ? 00:00:00 /usr/bin/dockerd --selinux-enabled
root 4549 3117 0 08:15 pts/0 00:00:00 grep --color=auto dockerd
[root@localhost conf]#
# 執行一個容器,將本地nginx.conf檔案掛載到容器中
[root@localhost conf]# docker run --name test-selinux-nginx -v /root/nginx/conf/nginx.conf:/etc/nginx/nginx.conf -d nginx
bbef34e4caa4e8c3a19f9eae5859691e3504731568e7e585108e26aade95be76
[root@localhost conf]#
[root@localhost conf]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
bbef34e4caa4 nginx "nginx -g 'daemon of…" 15 seconds ago Exited (1) 13 seconds ago test-selinux-nginx
[root@localhost conf]# docker logs -f bbef34e4caa4
2018/09/17 15:16:02 [emerg] 1#1: open() "/etc/nginx/nginx.conf" failed (13: Permission denied)
nginx: [emerg] open() "/etc/nginx/nginx.conf" failed (13: Permission denied)
[root@localhost conf]#
[root@localhost conf]# ls -Z
-rw-r--r--. root root unconfined_u:object_r:admin_home_t:s0 nginx.conf
[root@localhost conf]#
docker run -v /var/db:/var/db:z rhel7 /bin/sh
[root@localhost conf]# docker run --name test-selinux-z-nginx -v /root/nginx/conf/nginx.conf:/etc/nginx/nginx.conf:z -d nginx
db49bbe352ff1ab800274a17fd18f9c7d86c281e60ac3ffa36ba14e12949285d
[root@localhost conf]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
db49bbe352ff nginx "nginx -g 'daemon of…" 5 seconds ago Up 2 seconds 80/tcp test-selinux-z-nginx
[root@localhost conf]#
[lynzabo@VM_0_6_centos ~]$ docker run -it --ulimit nofile=2048 --ulimit nproc=100 busybox sh
/ # ulimit -a
-f: file size (blocks) unlimited
-t: cpu time (seconds) unlimited
-d: data seg size (kb) unlimited
-s: stack size (kb) 8192
-c: core file size (blocks) unlimited
-m: resident set size (kb) unlimited
-l: locked memory (kb) 64
-p: processes 100
-n: file descriptors 2048
-v: address space (kb) unlimited
-w: locks unlimited
-e: scheduling priority 0
-r: real-time priority 0
/ ## 我們使用daemon使用者啟動4個容器,並設定允許的最大行程數為3
$ docker run -d -u daemon --ulimit nproc=3 busybox top
$ docker run -d -u daemon --ulimit nproc=3 busybox top
$ docker run -d -u daemon --ulimit nproc=3 busybox top
# 這個容器會失敗並報錯,資源不足
$ docker run -d -u daemon --ulimit nproc=3 busybox top
[lynzabo@VM_0_6_centos ~]$ docker run -d --name test-pids-limit --pids-limit=5 busybox top
5693c8c31284b0f3cb4eb10d4f67e13ad98d1972a27dab094f0ad96154a5ce6a
[lynzabo@VM_0_6_centos ~]$ docker exec -ti test-pids-limit sh
/ # ps -ef
PID USER TIME COMMAND
1 root 0:00 top
5 root 0:00 sh
9 root 0:00 ps -ef
/ # nohup top &
/ # nohup: appending output to nohup.out
/ # nohup top &
/ # nohup: appending output to nohup.out
/ # nohup top &
/ # nohup: appending output to nohup.out
/ # nohup top &
sh: can't fork: Resource temporarily unavailable
/ #
-
可以使用docker-bench-security檢查你的Docker執行環境,如Docker daemon配置,宿主機配置
-
使用Sysdig Falco(地址:https://sysdig.com/opensource/falco/)可以監視容器的行為,檢測容器中是否有異常活動。
-
使用GRSEC 和 PAX來加固系統核心,還可以使用GRSecurity為系統提供更豐富的安全限制。等等。


