
最近,在自然語言處理(NLP)領域中,使用語言模型預訓練方法在多項 NLP 任務上都獲得了不錯的提升,廣泛受到了各界的關註。就此,我將最近看的一些相關論文進行總結,選取了幾個代表性模型(包括 ELMo [1],OpenAI GPT [2] 和 BERT [3])和大家一起學習分享。
作者丨羅凌
學校丨大連理工大學資訊檢索研究室
研究方向丨深度學習,文字分類,物體識別
引言
在介紹論文之前,我將先簡單介紹一些相關背景知識。首先是語言模型(Language Model),語言模型簡單來說就是一串詞序列的機率分佈。具體來說,語言模型的作用是為一個長度為 m 的文字確定一個機率分佈 P,表示這段文字存在的可能性。
在實踐中,如果文字的長度較長,P(wi | w1, w2, . . . , wi−1) 的估算會非常困難。因此,研究者們提出使用一個簡化模型:n 元模型(n-gram model)。在 n 元模型中估算條件機率時,只需要對當前詞的前 n 個詞進行計算。在 n 元模型中,傳統的方法一般採用頻率計數的比例來估算 n 元條件機率。當 n 較大時,機會存在資料稀疏問題,導致估算結果不準確。因此,一般在百萬詞級別的語料中,一般也就用到三元模型。

為了緩解 n 元模型估算機率時遇到的資料稀疏問題,研究者們提出了神經網路語言模型。代表性工作是 Bengio 等人在 2003 年提出的神經網路語言模型,該語言模型使用了一個三層前饋神經網路來進行建模。其中有趣的發現了第一層引數,用做詞表示不僅低維緊密,而且能夠蘊涵語意,也就為現在大家都用的詞向量(例如 word2vec)打下了基礎。
其實,語言模型就是根據背景關係去預測下一個詞是什麼,這不需要人工標註語料,所以語言模型能夠從無限制的大規模單語語料中,學習到豐富的語意知識。
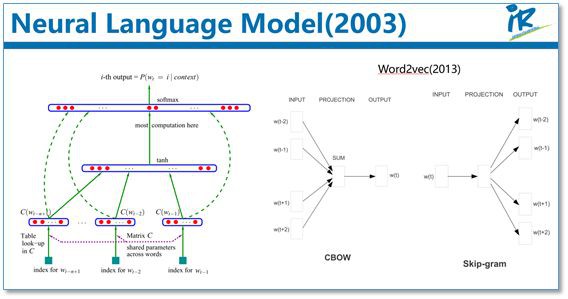
接下來再簡單介紹一下預訓練的思想。我們知道目前神經網路在進行訓練的時候基本都是基於後向傳播(BP)演演算法,透過對網路模型引數進行隨機初始化,然後透過 BP 演演算法利用例如 SGD 這樣的最佳化演演算法去最佳化模型引數。
那麼預訓練的思想就是,該模型的引數不再是隨機初始化,而是先有一個任務進行訓練得到一套模型引數,然後用這套引數對模型進行初始化,再進行訓練。
其實早期的使用自編碼器棧式搭建深度神經網路就是這個思想。還有詞向量也可以看成是第一層 word embedding 進行了預訓練,此外在基於神經網路的遷移學習中也大量用到了這個思想。

接下來,我們就具體看一下這幾篇用語言模型進行預訓練的工作。
ELMo
引言
Deep Contextualized Word Representations [1] 這篇論文來自華盛頓大學的工作,最後是發表在今年的 NAACL 會議上,並獲得了最佳論文。
其實這個工作的前身來自同一團隊在 ACL 2017 發表的 Semi-supervised sequence tagging with bidirectional language models [4],只是在這篇論文裡,他們把模型更加通用化了。
首先我們來看看他們工作的動機,他們認為一個預訓練的詞表示應該能夠包含豐富的句法和語意資訊,並且能夠對多義詞進行建模。而傳統的詞向量(例如 word2vec)是背景關係無關的。例如下麵”apple”的例子,這兩個”apple”根據背景關係意思是不同的,但是在 word2vec 中,只有 apple 一個詞向量,無法對一詞多義進行建模。

所以他們利用語言模型來獲得一個背景關係相關的預訓練表示,稱為 ELMo,併在 6 個 NLP 任務上獲得了提升。

方法
在 EMLo 中,他們使用的是一個雙向的 LSTM 語言模型,由一個前向和一個後向語言模型構成,標的函式就是取這兩個方向語言模型的最大似然。

在預訓練好這個語言模型之後,ELMo 就是根據下麵的公式來用作詞表示,其實就是把這個雙向語言模型的每一中間層進行一個求和。最簡單的也可以使用最高層的表示來作為 ELMo。

然後在進行有監督的 NLP 任務時,可以將 ELMo 直接當做特徵拼接到具體任務模型的詞向量輸入或者是模型的最高層表示上。
總結一下,不像傳統的詞向量,每一個詞只對應一個詞向量,ELMo 利用預訓練好的雙向語言模型,然後根據具體輸入從該語言模型中可以得到背景關係依賴的當前詞表示(對於不同背景關係的同一個詞的表示是不一樣的),再當成特徵加入到具體的 NLP 有監督模型裡。
實驗
這裡我們簡單看一下主要的實驗,具體實驗還需閱讀論文。首先是整個模型效果的實驗。他們在 6 個 NLP 任務上進行了實驗,首先根據目前每個任務搭建了不同的模型作為 baseline,然後加入 ELMo,可以看到加入 ELMo 後 6 個任務都有所提升,平均大約能夠提升 2 個多百分點,並且最後的結果都超過了之前的先進結果(SOTA)。
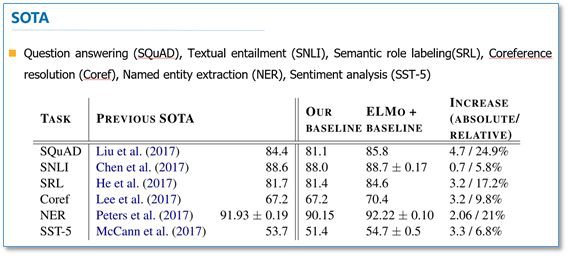
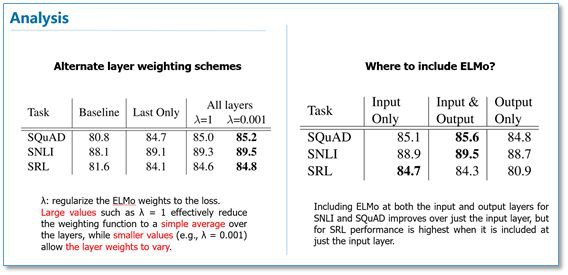
在下麵的分析實驗中,我們可以看到使用所有層的效果要比只使用最後一層作為 ELMo 的效果要好。在輸入還是輸出上面加 EMLo 效果好的問題上,並沒有定論,不同的任務可能效果不一樣。
OpenAI GPT
引言
我們來看看第二篇論文 Improving Language Understanding by Generative Pre-Training [2],這是 OpenAI 團隊前一段時間放出來的預印版論文。他們的標的是學習一個通用的表示,能夠在大量任務上進行應用。
這篇論文的亮點主要在於,他們利用了Transformer網路代替了LSTM作為語言模型來更好的捕獲長距離語言結構。然後在進行具體任務有監督微調時使用了語言模型作為附屬任務訓練標的。最後在 12 個 NLP 任務上進行了實驗,9 個任務獲得了 SOTA。

方法
首先我們來看一下他們無監督預訓練時的語言模型。他們仍然使用的是標準的語言模型標的函式,即透過前 k 個詞預測當前詞,但是在語言模型網路上,他們使用了 Google 團隊在 Attention is all your need 論文中提出的 Transformer 解碼器作為語言模型。
Transformer 模型主要是利用自註意力(self-attention)機制的模型,這裡我就不多進行介紹,大家可以看論文或者參考我之前的文章自然語言處理中的自註意力機制(Self-Attention Mechanism)。

然後在具體 NLP 任務有監督微調時,與 ELMo 當成特徵的做法不同,OpenAI GPT 不需要再重新對任務構建新的模型結構,而是直接在 Transformer 這個語言模型上的最後一層接上 softmax 作為任務輸出層,然後再對這整個模型進行微調。他們還發現,如果使用語言模型作為輔助任務,能夠提升有監督模型的泛化能力,並且能夠加速收斂。

由於不同 NLP 任務的輸入有所不同,在 Transformer 模型的輸入上針對不同 NLP 任務也有所不同。
具體如下圖,對於分類任務直接講文字輸入即可;對於文字蘊涵任務,需要將前提和假設用一個 Delim 分割向量拼接後進行輸入;對於文字相似度任務,在兩個方向上都使用 Delim 拼接後,進行輸入;對於像問答多選擇的任務,就是將每個答案和背景關係進行拼接進行輸入。

實驗
下麵我簡單的列舉了一下不同 NLP 任務上的實驗結果。
語言推理任務:

問答和常識推理任務:

語意相似度和分類任務:
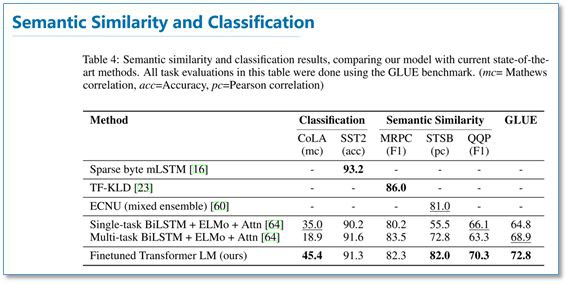
可以看到在多項任務上,OpenAI GPT 的效果要比 ELMo 的效果更好。從下麵的消除實驗來看,在去掉預訓練部分後,所有任務都大幅下降,平均下降了 14.8%,說明預訓練很有效;在大資料集上使用語言模型作為附加任務的效果更好,小資料集不然;利用 LSTM 代替 Transformer 後,結果平均下降了 5.6%,也體現了 Transformer 的效能。

BERT
引言
上週 Google 放出了他們的語言模型預訓練方法,瞬時受到了各界廣泛關註,不少媒體公眾號也進行了相應報道,那我們來看看這篇論文 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [3]。
這篇論文把預訓練語言表示方法分為了基於特徵的方法(代表 ELMo)和基於微調的方法(代表 OpenAI GPT)。而目前這兩種方法在預訓練時都是使用單向的語言模型來學習語言表示。

這篇論文中,作者們證明瞭使用雙向的預訓練效果更好。其實這篇論文方法的整體框架和 GPT 類似,是進一步的發展。具體的,BERT 是使用 Transformer 的編碼器來作為語言模型,在語言模型預訓練的時候,提出了兩個新的標的任務(即遮擋語言模型 MLM 和預測下一個句子的任務),最後在 11 個 NLP 任務上取得了 SOTA。

方法
在語言模型上,BERT 使用的是 Transformer 編碼器,並且設計了一個小一點的 base 結構和一個更大的網路結構。

對比一下三種語言模型結構,BERT 使用的是 Transformer 編碼器,由於 self-attention 機制,所以模型上下層直接全部互相連線的。而 OpenAI GPT 使用的是 Transformer 編碼器,它是一個需要從左到右的受限制的 Transformer,而 ELMo 使用的是雙向 LSTM,雖然是雙向的,但是也只是在兩個單向的 LSTM 的最高層進行簡單的拼接。所以只有 BERT 是真正在模型所有層中是雙向的。

而在模型的輸入方面,BERT 做了更多的細節,如下圖。他們使用了 WordPiece embedding 作為詞向量,並加入了位置向量和句子切分向量。此外,作者還在每一個文字輸入前加入了一個 CLS 向量,後面會有這個向量作為具體的分類向量。

在語言模型預訓練上,他們不再使用標準的從左到右預測下一個詞作為標的任務,而是提出了兩個新的任務。第一個任務他們稱為 MLM,即在輸入的詞序列中,隨機的擋上 15% 的詞,然後任務就是去預測擋上的這些詞,可以看到相比傳統的語言模型預測標的函式,MLM 可以從任何方向去預測這些擋上的詞,而不僅僅是單向的。
但是這樣做會帶來兩個缺點:
1. 預訓練用 [MASK] 提出擋住的詞後,在微調階段是沒有 [MASK] 這個詞的,所以會出現不匹配;
2. 預測 15% 的詞而不是預測整個句子,使得預訓練的收斂更慢。但是對於第二點,作者們覺得雖然是慢了,但是效果提升比較明顯可以彌補。

對於第一點他們採用了下麵的技巧來緩解,即不是總是用 [MASK] 去替換擋住的詞,在 10% 的時間用一個隨機詞取替換,10% 的時間就用這個詞本身。

而對於傳統語言模型,並沒有對句子之間的關係進行考慮。為了讓模型能夠學習到句子之間的關係,作者們提出了第二個標的任務就是預測下一個句子。其實就是一個二元分類問題,50% 的時間,輸入一個句子和下一個句子的拼接,分類標簽是正例,而另 50% 是輸入一個句子和非下一個隨機句子的拼接,標簽為負例。最後整個預訓練的標的函式就是這兩個任務的取和求似然。

在微調階段,不同任務的模型如下圖,只是在輸入層和輸出層有所區別,然後整個模型所有引數進行微調。

實驗
下麵我們列出一下不同 NLP 上 BERT 的效果。
GLUE結果:

QA結果:

物體識別結果:

SWAG結果:

可以看到在這些所有 NLP 任務上,BERT 都取得了 SOTA,而且相比 EMLo 和 GPT 的效果提升還是比較大的。
在預訓練實驗分析上,可以看到本文提出的兩個標的任務的作用還是很有效的,特別是在 MLM 這個標的任務上。
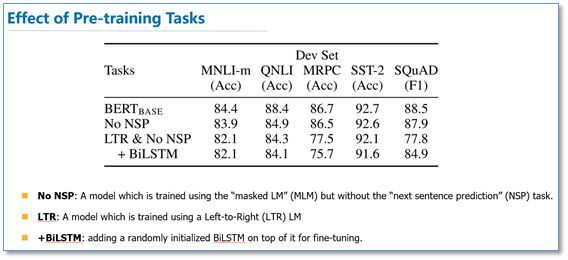
作者也做了模型規模的實驗,大規模的模型效果更好,即使在小資料集上。

此外,作者也做了像 ELMo 當成特徵加入的實驗,從下圖可以看到,當成特徵加入最好效果能達到 96.1% 和微調的 96.4% 差不多,說明 BERT 對於基於特徵和基於微調這兩種方法都是有效的。

總結
最後進行簡單的總結,和傳統的詞向量相比,使用語言模型預訓練其實可以看成是一個句子級別的背景關係的詞表示,它可以充分利用大規模的單語語料,並且可以對一詞多義進行建模。
而且從後面兩篇論文可以看到,透過大規模語料預訓練後,使用統一的模型或者是當成特徵直接加到一些簡單模型上,對各種 NLP 任務都能取得不錯的效果,說明很大程度上緩解了具體任務對模型結構的依賴。在目前很多評測上也都取得了 SOTA,ELMo 也提供了官網供大家使用。
但是這些方法在空間和時間複雜度上都比較高,特別是 BERT,在論文中他們訓練 base 版本需要在 16 個 TGPU 上,large 版本需要在 64 個 TPU 上訓練 4 天。對於一般條件,一個 GPU 訓練的話,得用上 1年。還有就是可以看出這些方法裡面都存在很多工程細節,一些細節做得不好的話,效果也會大大折扣。
參考文獻
[1] Peters, M. E. et al. Deep contextualized word representations. naacl (2018).
[2] Radford, A. & Salimans, T. Improving Language Understanding by Generative Pre-Training. (2018).
[3] Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. (2018).
[4] Peters, M. E., Ammar, W., Bhagavatula, C. & Power, R. Semi-supervised sequence tagging with bidirectional language models. Acl (2017).

點選以下標題檢視更多論文解讀:
 #投 稿 通 道#
#投 稿 通 道#
讓你的論文被更多人看到
如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準:
• 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向)
• 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結
• PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱:
• 投稿郵箱:hr@paperweekly.site
• 所有文章配圖,請單獨在附件中傳送
• 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視作者部落格
