

隨著網際網路的發展,面對海量使用者高併發業務,傳統的阻塞式的服務端架構樣式已經無能為力。為大家提供有用的高效能網路程式設計的I/O模型概覽以及網路服務行程模型的比較,以揭開設計和實現高效能網路架構的神秘面紗。
網際網路服務端處理網路請求的原理
首先看看一個典型網際網路服務端處理網路請求的典型過程。由圖可以看到,主要處理步驟包括:

1)獲取請求資料,客戶端與伺服器建立連線發出請求,伺服器接受請求(1-3);
2)構建響應,當伺服器接收完請求,併在使用者空間處理客戶端的請求,直到構建響應完成(4);
3)傳回資料,伺服器將已構建好的響應再透過核心空間的網路 I/O 發還給客戶端(5-7)。
設計服務端併發模型時,主要有如下兩個關鍵點:
1)伺服器如何管理連線,獲取輸入資料;
2)伺服器如何處理請求。
以上兩個關鍵點最終都與作業系統的 I/O 模型以及執行緒(行程)模型相關,下麵先詳細介紹這I/O模型。
“I/O 模型”的基本認識
介紹作業系統的 I/O 模型之前,先瞭解一下幾個概念:
1)阻塞呼叫與非阻塞呼叫;
2)阻塞呼叫是指呼叫結果傳回之前,當前執行緒會被掛起,呼叫執行緒只有在得到結果之後才會傳回;
3)非阻塞呼叫指在不能立刻得到結果之前,該呼叫不會阻塞當前執行緒。
兩者的最大區別在於被呼叫方在收到請求到傳回結果之前的這段時間內,呼叫方是否一直在等待。
阻塞是指呼叫方一直在等待而且別的事情什麼都不做;非阻塞是指呼叫方先去忙別的事情。
同步處理與非同步處理:同步處理是指被呼叫方得到最終結果之後才傳回給呼叫方;非同步處理是指被呼叫方先傳回應答,然後再計算呼叫結果,計算完最終結果後再通知並傳回給呼叫方。
阻塞、非阻塞和同步、非同步的區別(阻塞、非阻塞和同步、非同步其實針對的物件是不一樣的):
1)阻塞、非阻塞的討論物件是呼叫者;
2)同步、非同步的討論物件是被呼叫者。
Recvfrom函式:Recvfrom 函式(經Socket 接收資料),這裡把它視為系統呼叫。一個輸入操作通常包括兩個不同的階段:
1)等待資料準備好;
2)從核心向行程複製資料。
對於一個套接字上的輸入操作,第一步通常涉及等待資料從網路中到達。當所等待分組到達時,它被覆制到核心中的某個緩衝區。第二步就是把資料從核心緩衝區複製到應用行程緩衝區。
實際應用程式在系統呼叫完成上面的 2 步操作時,呼叫方式的阻塞、非阻塞,作業系統在處理應用程式請求時,處理方式的同步、非同步處理的不同,可以分為 5 種 I/O 模型(參考“UNIX網路程式設計捲1”)。
I/O模型1:阻塞式 I/O 模型(blocking I/O)

在阻塞式 I/O 模型中,應用程式在從呼叫 recvfrom 開始到它傳回有資料報準備好這段時間是阻塞的,recvfrom 傳回成功後,應用行程開始處理資料報。
比喻:一個人在釣魚,當沒魚上鉤時,就坐在岸邊一直等。
優點:程式簡單,在阻塞等待資料期間行程/執行緒掛起,基本不會佔用 CPU 資源。
缺點:每個連線需要獨立的行程/執行緒單獨處理,當併發請求量大時為了維護程式,記憶體、執行緒切換開銷較大,這種模型在實際生產中很少使用。
I/O模型2:非阻塞式 I/O 模型(non-blocking I/O)

在非阻塞式 I/O 模型中,應用程式把一個套介面設定為非阻塞,就是告訴核心,當所請求的 I/O 操作無法完成時,不要將行程睡眠。
而是傳回一個錯誤,應用程式基於 I/O 操作函式將不斷的輪詢資料是否已經準備好,如果沒有準備好,繼續輪詢,直到資料準備好為止。
比喻:邊釣魚邊玩手機,隔會再看看有沒有魚上鉤,有的話就迅速拉桿。
優點:不會阻塞在內核的等待資料過程,每次發起的 I/O 請求可以立即傳回,不用阻塞等待,實時性較好。
缺點:輪詢將會不斷地詢問核心,這將佔用大量的 CPU 時間,系統資源利用率較低,所以一般 Web 伺服器不使用這種 I/O 模型。
I/O模型3:I/O 復用模型(I/O multiplexing)
在 I/O 復用模型中,會用到 Select 或 Poll 函式或 Epoll 函式(Linux 2.6 以後的核心開始支援),這兩個函式也會使行程阻塞,但是和阻塞 I/O 有所不同。
這兩個函式可以同時阻塞多個 I/O 操作,而且可以同時對多個讀操作,多個寫操作的 I/O 函式進行檢測,直到有資料可讀或可寫時,才真正呼叫 I/O 操作函式。
比喻:放了一堆魚竿,在岸邊一直守著這堆魚竿,沒魚上鉤就玩手機。
優點:可以基於一個阻塞物件,同時在多個描述符上等待就緒,而不是使用多個執行緒(每個檔案描述符一個執行緒),這樣可以大大節省系統資源。
缺點:當連線數較少時效率相比多執行緒+阻塞 I/O 模型效率較低,可能延遲更大,因為單個連線處理需要 2 次系統呼叫,佔用時間會有增加。
眾所周之,Nginx這樣的高效能網際網路反向代理伺服器大獲成功的關鍵就是得益於Epoll。
I/O模型4:訊號驅動式 I/O 模型(signal-driven I/O)

在訊號驅動式 I/O 模型中,應用程式使用套介面進行訊號驅動 I/O,並安裝一個訊號處理函式,行程繼續執行並不阻塞。
當資料準備好時,行程會收到一個 SIGIO 訊號,可以在訊號處理函式中呼叫 I/O 操作函式處理資料。
比喻:魚竿上繫了個鈴鐺,當鈴鐺響,就知道魚上鉤,然後可以專心玩手機。
優點:執行緒並沒有在等待資料時被阻塞,可以提高資源的利用率。
缺點:訊號 I/O 在大量 IO 操作時可能會因為訊號佇列上限溢位導致沒法通知。
訊號驅動 I/O 儘管對於處理 UDP 套接字來說有用,即這種訊號通知意味著到達一個資料報,或者傳回一個非同步錯誤。
但是,對於 TCP 而言,訊號驅動的 I/O 方式近乎無用,因為導致這種通知的條件為數眾多,每一個來進行判別會消耗很大資源,與前幾種方式相比優勢盡失。
I/O模型5:非同步 I/O 模型(即AIO,全稱asynchronous I/O)

由 POSIX 規範定義,應用程式告知核心啟動某個操作,並讓核心在整個操作(包括將資料從核心複製到應用程式的緩衝區)完成後通知應用程式。
這種模型與訊號驅動模型的主要區別在於:訊號驅動 I/O 是由核心通知應用程式何時啟動一個 I/O 操作,而非同步 I/O 模型是由核心通知應用程式 I/O 操作何時完成。
優點:非同步 I/O 能夠充分利用 DMA 特性,讓 I/O 操作與計算重疊。
缺點:要實現真正的非同步 I/O,作業系統需要做大量的工作。目前 Windows 下透過 IOCP 實現了真正的非同步 I/O。
而在 Linux 系統下,Linux 2.6才引入,目前 AIO 並不完善,因此在 Linux 下實現高併發網路程式設計時都是以 IO 復用模型樣式為主。
關於AOI的介紹,請見“Java新一代網路程式設計模型AIO原理及Linux系統AIO介紹”。
I/O 模型總結
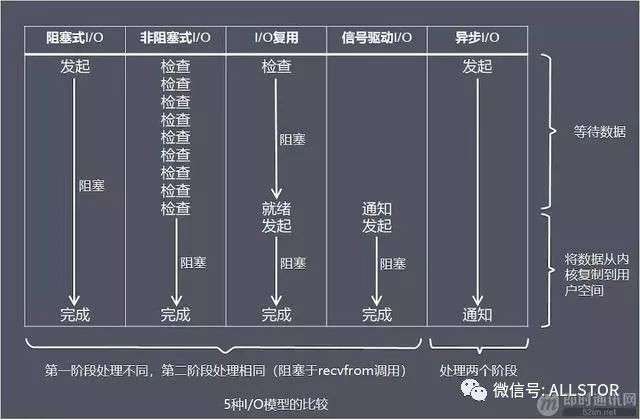
從上圖中我們可以看出,越往後,阻塞越少,理論上效率也是最優。
這五種 I/O 模型中,前四種屬於同步 I/O,因為其中真正的 I/O 操作(recvfrom)將阻塞行程/執行緒,只有非同步 I/O 模型才與 POSIX 定義的非同步 I/O 相匹配。
作者:陳彩華(caison),主要從事服務端開發、需求分析、系統設計、最佳化重構工作,主要開發語言是 Java,現任廣州貝聊服務端研發工程師。
推薦閱讀:
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取更多電子書詳情。

求知若渴, 虛心若愚

