(點選上方公眾號,可快速關註)
來源:ImportNew – fzr
概述
雜湊策略會對HashMap或HashSet之類的雜湊集合的效能產生直接的影響。
內建的雜湊(又稱雜湊)函式都是通用的,在大多數使用情況下都能表現很好。但是我們能不能做的更好呢,特別是當你對某個用例產生了很好的想法時?
測試一個雜湊策略
在先前的一篇文章中,我研究了一些測試雜湊策略的方法,其中特別註意了一種“正交位”最佳化的雜湊策略,它僅僅只是改變一個位就能確保每個雜湊結果盡可能的不同。
http://vanillajava.blogspot.co.uk/2015/08/comparing-hashing-strategies.html?view=magazine
然而,如果要對一個已知的元素或關鍵字集合進行雜湊,你就可以針對具體案例進行最佳化,而不是尋求一個通用方案。
減少衝突
一個雜湊集合中最主要的事情就是避免衝突了。所謂衝突,就是兩個以上關鍵字對映到同一個雜湊槽中。這些衝突意味著當有多個關鍵字對映到同一個雜湊槽中時你必須要付出更多的努力來檢查那些關鍵字是否是你想要的那個。理想狀態下一個雜湊槽中最多有一個關鍵字。
我只需要唯一的雜湊碼,是嗎?
通常的誤解是隻要雜湊碼唯一就可以避免衝突。雖然都希望雜湊碼是唯一的,但它還不夠。
假設現在有一些關鍵字,每一個都有唯一的32位雜湊碼。如果你有40億雜湊槽,每個關鍵字都有自己的槽,那就沒有衝突了。對於所有的雜湊集合,這樣大的陣列一般是不太現實的。事實上,HashMap和HashSet的大小都收到機器記憶體的限制,一般為2^30,大概剛剛超過10億。
當你只能有一個規模上比較實際的雜湊集合時又該如何呢?雜湊槽的數目需要更小一些,而雜湊碼需對雜湊槽數目取模。如果雜湊槽數是2的冪值,你可以用最低位當掩碼。
來看個例子,ftse350.csv。如果把第一列作為關鍵字或是元素,就有352個字串。這些字串有唯一的String().hashCode()碼,但是假設我們只取這些雜湊碼的低位。會不會有衝突呢?

一個裝載因子是0.7(預設)的HashMap的大小是512,使用雜湊碼的低九位作為掩碼。可以看到,儘管原始的雜湊碼是唯一的,仍然有大約30%的關鍵字會衝突。
HashTesterMain的程式碼在這裡。
https://github.com/OpenHFT/Chronicle-Algorithms/blob/master/src/test/java/net/openhft/chronicle/algo/hashing/HashTesterMain.java
為了減少糟糕的雜湊策略造成的影響,HashMap使用了擾動函式。Java 8裡的實現相當簡單。
下麵是來自HashMap.hash的原始碼。想瞭解更多細節,可以閱讀Javadoc檔案。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
這個方法混合了原始雜湊碼的高位和低位,以此來提高低位的隨機性。對於像上面的那樣有相當高的衝突率的情況,這就是一個改善方法。請參看第三列。
初探 String類的雜湊函式
下麵是String.hashCode()的程式碼:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
String的雜湊實現已經在Javadoc中規定好了,所以我們基本沒有機會改動,但我們可以定義一個新的雜湊策略。
雜湊策略的組成部分
我會留意雜湊策略中的兩個部分。
-
魔法數字。你可以嘗試不同的數字以取得最佳效果。
-
程式碼結構。你需要一個無論選取什麼樣的魔法數字都能提供一個好的結果的程式碼結構。
魔法數字固然很重要,但是你並不想讓它過於重要;因為總是有些時候你選的數字並不適合你的使用場景。這就是為什麼你同時還需要一個即使在魔法數字選取很糟糕的情況下其最壞情況依然不是特別差的程式碼結構。
用別的乘數代替31
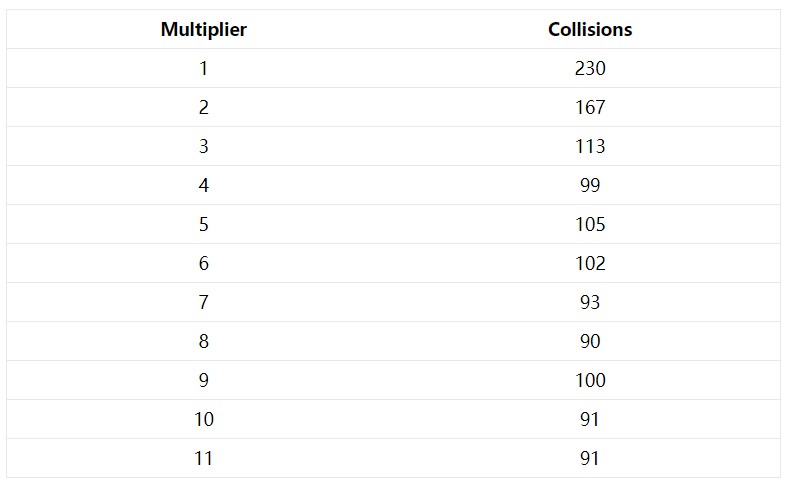
可以看到,魔法數的選取的確很重要,但需要嘗試的數字太多了。我們需要寫一個測試程式,測試出一個不錯的隨機選擇。HashSearchMain的原始碼。
https://github.com/OpenHFT/Chronicle-Algorithms/blob/master/src/test/java/net/openhft/chronicle/algo/hashing/HashSearcherMain.java

程式碼的關鍵部分:
public static int hash(String s, int multiplier) {
int h = 0;
for (int i = 0; i < s.length(); i++) {
h = multiplier * h + s.charAt(i);
}
return h;
}
private static int xorShift16(int hash) {
return hash ^ (hash >> 16);
}
private static int addShift16(int hash) {
return hash + (hash >> 16);
}
private static int xorShift16n9(int hash) {
hash ^= (hash >>> 16);
hash ^= (hash >>> 9);
return hash;
}
可以發現,如果提供了好的乘數,或是適合於你的關鍵字集合的乘數,那麼重覆乘上每個雜湊值再加上下一個字元就很合理。對比分別以130795和31作乘數,對於測試的關鍵字集合,前者只有81次碰撞而後者有103次。
如果你再加上擾動函式,碰撞會減少到大約68次。這已經很接近加倍陣列規模時的衝突率了:不佔用更多記憶體,卻可以降低衝突率。
但是當我們向雜湊集合中新增新的關鍵字時會發生什麼呢?魔法數字還能表現良好嗎?這使我不得不研究最壞衝突率,以決定在面對更大範圍的輸入時,哪種程式碼結構可能會表現得更好。hash()的最壞表現是250次碰撞,即70%的關鍵字發生衝突,確實很糟糕。擾動函式能稍稍提高效能,但作用也不大。註意:如果我們選擇與偏移值相加而不是異或會得到更糟糕的結果。
然而,如果選擇位移兩次——不僅僅是混合高低位,還有從產生的雜湊值的四個部分選擇的位,結果發現,最壞情況的衝突率大大下降。這使我想到,在選擇的關鍵字改變的情況下,如果結構足夠好,魔法數的影響足夠低,我們得到糟糕結果的可能性就會降低。
如果在雜湊函式中選擇了相加而非異或,會發生什麼呢?
在擾動函式中採用異或而不是相加可能會得到更好的結果。如果我們將
h = multiplier * h + s.charAt(i);
變為
h = multiplier * h ^ s.charAt(i);
會發生什麼呢?

最佳情況下的表現變好了一些,然而最壞情況下的衝突率明顯更高了。由此我看出,魔法數選取的重要性提高了,也意味著,關鍵字的影響更大了。考慮到關鍵字可能會隨著時間改變,這種選擇好像有些冒險。
為何選擇奇數作為乘數
當與一個奇數相乘時,結果的低位是0或1的機率相等;因為0*1=0,1*1=1.然而,如果與偶數相乘,最低位一定是0.也就是說,這一位不再是隨機變化的了。假設我們重覆先前的測試,但是隻採用偶數,結果會怎樣?

如果你很幸運,魔法數選對了,那麼結果將會和奇數情況下一樣好。然而如果不太幸運,結果可能會很糟糕。325次碰撞意味著,512個雜湊槽中只有27個被使用了。
更高階的雜湊策略有何不同?
對於我們使用的基於City,Murmur,XXHash,以及Vanilla Hash(我們自己的)的雜湊策略:
-
該策略一次讀取64位資料,比一位元組一位元組地讀快很多;
-
所得有效值是兩個64位長的值;
-
有效值被縮短至64位;
-
結果使用了更多的常量乘數;
-
擾動函式更為複雜;
我們在實現中使用長雜湊值是因為:
-
我們為64位處理器做了最佳化;
-
Java中最長的基本資料型別是64位的;
-
如果你的雜湊集合太大(比如百萬以上),32位的雜湊值很難保證唯一性。
總結
透過探索雜湊值的產生過程,我們找到了將352個關鍵字的衝突次數從103次降到68次的方法。同時,我們也相信,如果關鍵字集合發生變化,我們也能降低變化可能造成的影響。
這是在不佔用更多記憶體,或更多處理器資源的情況下完成的。
我們也可以選擇使用更多記憶體。
作為對比,可以看到,加倍陣列規模可以提高最佳情況下的表現。但我們仍然要面對的問題是:當關鍵字集合和魔法數匹配的不好時,雜湊衝突率依然很高。
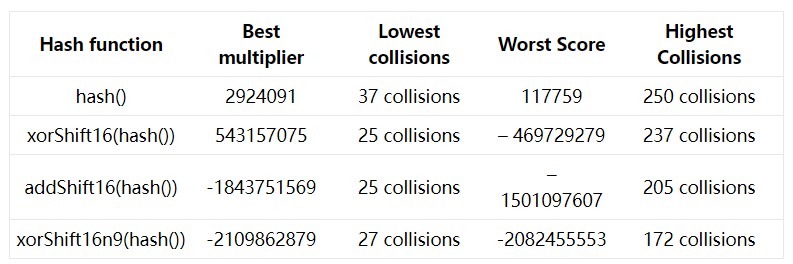
結論
在你的關鍵字集合比較穩定的情況下,你可以透過調整雜湊策略來明顯改善衝突率。當關鍵字集合改變時,你還需要測試不最佳化的情況下結果會糟糕到什麼程度。將這兩種策略結合起來,你可以不佔用更多記憶體和CPU就能得到提高效能的新雜湊策略。
【關於投稿】
如果大家有原創好文投稿,請直接給公號傳送留言。
① 留言格式:
【投稿】+《 文章標題》+ 文章連結
② 示例:
【投稿】《不要自稱是程式員,我十多年的 IT 職場總結》:http://blog.jobbole.com/94148/
③ 最後請附上您的個人簡介哈~
看完本文有收穫?請轉發分享給更多人
關註「ImportNew」,提升Java技能

