

嘉賓介紹:劉振東
阿裡巴巴中介軟體技術專家,2016年中介軟體效能挑戰賽亞軍,具有豐富的分散式系統設計和最佳化經驗,目前負責Apache RocketMQ新航道探索和創新。

分享文章內容包括RocketMQ的起源、RocketMQ概念模型、儲存模型、部署模型和最佳實踐總結。
一、RocketMQ的起源
通常,每個產品的誕生都源於一個具體的需求或問題,RocketMQ也不例外。起初,產品的原型像一個巨石,把所有需要實現的程式和介面都羅列到一起。但隨著公司業務的發展,所有的系統和功能都在這個巨石上開發,當改寫幾百上千名開發人員的時候,瓶頸就出來了。這時候,就需要我們把系統進行分解。
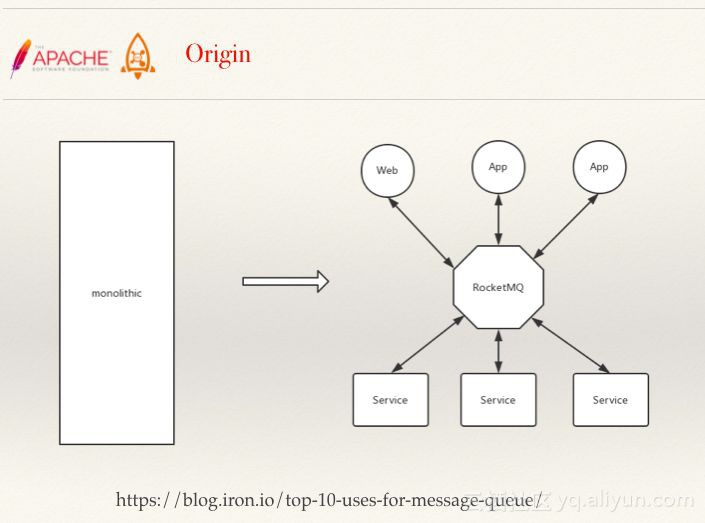
圖釋:巨石 -> 分散式
分解後,就出現了上圖中的分散式架構,這類架構最大的特點就是解耦,而RocketMQ的非同步解耦意味著底層的重構不會影響到上層應用的功能。RocketMQ另一個優勢是削峰填谷,在面臨流量的不確定性時,實現對流量的緩衝處理。此外,RocketMQ的順序設計特性使得RocketMQ成為一個天然的排隊引擎,例如,三個應用同時對一個後臺引擎發起請求,排隊引擎的特性可以確保不會引起“撞車”事故。
二、RocketMQ的概念模型
對於任何一款中介軟體產品而言,清晰的概念模型是幫助開發者正確理解使用它的關鍵。從RocketMQ的概念模型來看:Topic是用於儲存邏輯的地址的,Producer是資訊的傳送,Consumer是資訊的接收者。
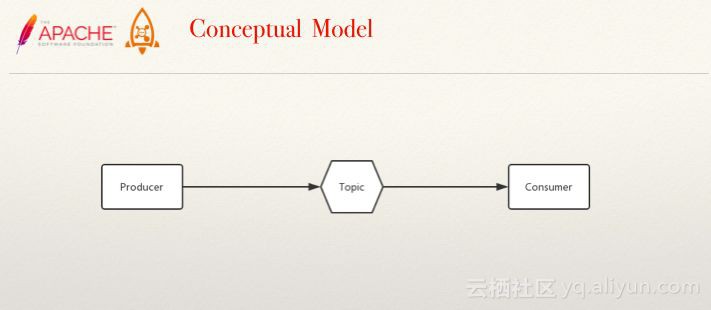
圖釋:最基本的概念模型
這隻是一個基礎的概念模型,在實際的生產中,結構會更複雜,例如我們需要對中間的Topic進行分割槽,出現多個有關聯的Topic,再如同一個資訊的傳送方會有多個訂閱者,同一個需求方會有多個傳送方,出現一對多、多對一的情況。
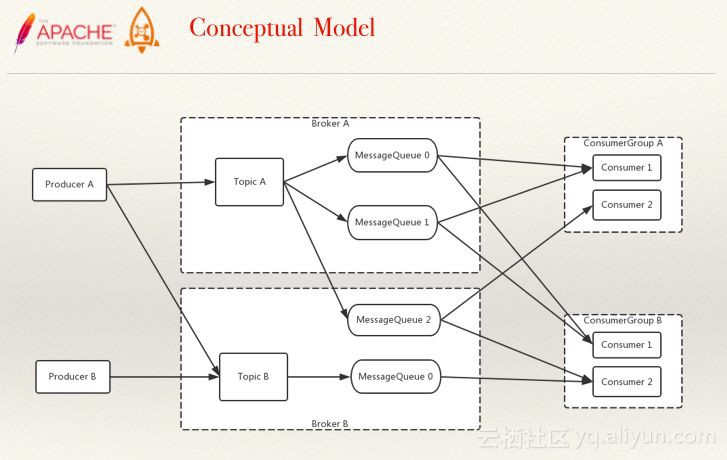
圖釋:擴充套件後的概念模型
上圖就是對Topic、Producer、Consumer擴充套件後的概念模型。RocketMQ中可以接觸到的所有概念都可以在這個概念模型圖中找到。左邊有兩個Producer,中間就是兩個分散式的Topic,用於儲存邏輯地址的兩個Topic中分別有兩個用於儲存物理儲存地址的Message Queue,Broker是實際部署過程的對應的一臺裝置,右邊則是兩個Consumer,Consumer Group是代表兩個Consumer可共享相互之間的訂閱。不同的Consumer Group相互獨立。一句話總結就是不同的Group是廣播訂閱的,同一個Group則是負載訂閱的。圖中的連線表示各模組之間的關係,例如Consumer Group A中的Consumer1對應著Message Queue0和Message Queue1的兩個佇列,分佈在BrokerA這一臺裝置上。
三、RocketMQ的儲存模型
RocketMQ的訊息的儲存是由ConsumeQueue和CommitLog 配合來完成的,ConsumeQueue中只儲存很少的資料,訊息主體都是透過CommitLog來進行讀寫。
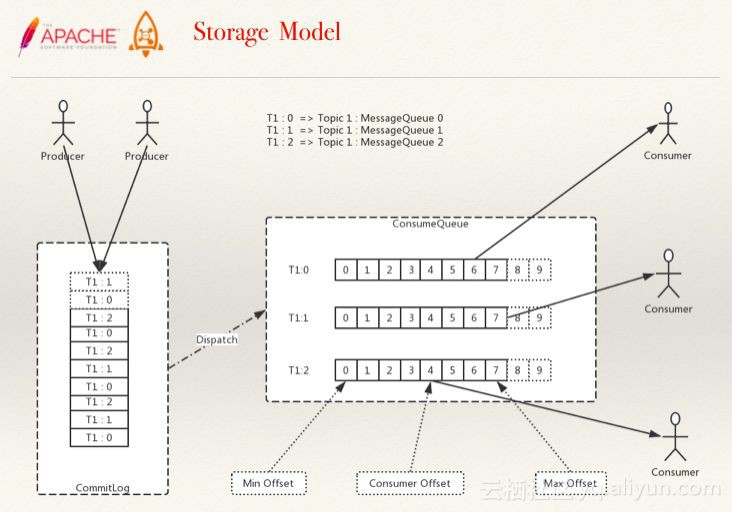
圖釋:儲存模型
CommitLog:是訊息主體以及元資料的儲存主體,對CommitLog建立一個ConsumeQueue,每個ConsumeQueue對應一個(概念模型中的)MessageQueue,所以只要有Commit Log在,Consume Queue即使資料丟失,仍然可以恢復出來。
Consume Queue:是一個訊息的邏輯佇列,儲存了這個Queue在CommitLog中的起始offset,log大小和MessageTag的hashCode。每個Topic下的每個Queue都有一個對應的ConsumerQueue檔案,例如Topic中有三個佇列,每個佇列中的訊息索引都會有一個編號,編號從0開始,往上遞增。並由此一個位點offset的概念,有了這個概念,就可以對Consumer端的消費情況進行佇列定義。
四、RocketMQ的部署模型
在實際的部署過程中,Broker是實際儲存訊息的資料節點,Nameserver則是服務發現節點,Producer傳送訊息到某一個Topic,並給到某個Consumer用於消費的過程中,需要先請求Nameserver拿到這個Topic的路由資訊,即Topic在哪些Broker上有,每個Broker上有哪些佇列,拿到這些請求後再把訊息傳送到Broker中;相對的,Consumer在消費的時候,也會經歷這個流程。

圖釋:部署模型
五、RocketMQ最佳實踐總結
這是我們在實踐過程的總結,同時我們也把其中一些普適性的總結作為阿裡中介軟體技術崗的面試題,目的是幫助大家更深刻的理解我們在設計分散式訊息系統的一些思考和探索。
Q1:分散式訊息系統中,如何避免訊息重覆?
造成訊息重覆的根本原因是:網路不可靠。只要透過網路交換資料,就無法避免這個問題。所以解決這個問題的辦法就是繞過這個問題。那麼問題就變成了:如果消費端收到兩條一樣的訊息,應該怎樣處理?
a. 消費端處理訊息的業務邏輯保持冪等性;
b. 保證每條訊息都有唯一編號且保證訊息處理成功與去重表的日誌同時出現。
透過冪等性,不管來多少條重覆訊息,可以實現處理的結果都一樣。再利用一張日誌表來記錄已經處理成功的訊息的ID,如果新到的訊息ID已經在日誌表中,那麼就可以不再處理這條訊息,避免訊息的重覆處理。
Q2:順序訊息擴容的過程中,如何在不停寫的情況下保證訊息順序?
1. 成倍擴容,實現擴容前後,同樣的key,hash到原佇列,或者hash到新擴容的佇列;
2. 擴容前,記錄舊佇列中的最大位點;
3. 對於每個Consumer Group,保證舊佇列中的資料消費完,再消費新佇列,也即:先對新佇列進行禁讀即可;
Q3:分散式訊息系統中,如何對訊息進行重放?
消費位點就是一個數字,把Consumer Offset改一下就可以達到重放的目的了。
文章來源:阿裡巴巴中介軟體
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取更多電子書詳情。

求知若渴, 虛心若愚

