來源:機器之心;
本文約1500字,建議閱讀5分鐘。
本文為你分享近日《Mathematics for Machine Learning》的全部草稿已放出,我們整理了這本書的簡要概述。
近日,Marc Peter Deisenroth、A Aldo Faisal 和 Cheng Soon Ong 所著書籍《Mathematics for Machine Learning》的全部草稿已放出,我們整理了這本書的簡要概述。感興趣的讀者可從以下連結獲取全文(英文版)。
書籍地址:https://mml-book.github.io/
以下是這本書的部分序言。
機器學習是捕捉人類知識、對適合構建機器和工程化自動系統的格式進行推理的最新嘗試。隨著機器學習越來越普遍,軟體包越來越易用,自然而然地,從業者不會註意低階技術細節。但是,這帶來了一些風險,即從業者不瞭解設計決策,更容易忽略機器學習演演算法的侷限性。對成功的機器學習演演算法的背後機制感興趣的從業者需要學習如下必備知識:
-
程式設計知識和資料分析工具;
-
大規模計算和相關框架;
-
數學和統計學知識,以及機器學習如何在其上構建。
在大學裡,機器學習的基礎課程會先花時間介紹部分必備知識。由於歷史原因,機器學習課程通常屬於電腦科學系,學生通常接受過前兩項必備知識領域的訓練,但對數學和統計學知識可能涉獵不多。目前的機器學習教科書嘗試用一兩章的篇幅改寫背景數學知識,可能在書的開頭或者是附錄。而本書將介紹基礎機器學習概念的數學基礎,並收集相關資訊。
為什麼要再寫一本關於機器學習的書?
機器學習構建於數學語言之上,以表達看似直觀實則難以形式化的概念。一旦得到恰當的形式化,我們就可以使用數學工具推匯出機器學習演演算法設計的選擇結果。這幫助我們理解正在解決的任務,同時瞭解智慧的本質。全球數學專業的學生常見的一種抱怨是數學話題似乎與實際問題沒有什麼相關。我們認為機器學習是促使人們學習數學的直接動力。
本書旨在作為構建現代機器學習基礎的大量數學文獻的指南。我們透過直接指出數學概念在基礎機器學習問題中的有用性來促進對數學概念學習的需求。為使書籍儘量簡短,我們省略了很多細節和高階概念。本書主要介紹基礎數學概念及其在機器學習語境中的意義,讀者可在章節最後找到進一步學習的大量資源。對於具備數學背景的讀者,本書提供簡潔但表述準確的機器學習概覽。與主要介紹機器學習方法和模型或程式設計知識的書籍不同,本書僅提供四個代表性機器學習演演算法。我們主要關註模型背後的數學概念,並描述其抽象之美。我們希望所有讀者能夠透過數學模型中的基礎選擇更加深入地瞭解機器學習應用中出現的機器學習基礎問題和相關的實際問題。
標的讀者
隨著機器學習應用在社會中的廣泛應用,我們認為每個人都應該瞭解其背後的原則。本書以學術數學風格寫成,可以幫助讀者準確理解機器學習背後的概念。我們鼓勵不熟悉這一風格的讀者堅持閱讀本書,並牢記每個話題的標的。我們將在文字中插入大量評論,希望可以幫助讀者獲取對全域性的理解。本書假設讀者具備中學數學和物理知識。例如,讀者應該瞭解過導數和積分,以及二維三維幾何向量。因此,本書的標的讀者包括本科大學生、夜校學生和參與機器學習線上課程的人們。
本書結構如下所示:
第一部分:數學基礎
1. 引言和動機
2. 線性代數
3. 解析幾何
4. 矩陣分解
5. 向量微積分
6. 機率和分佈
7. 連續最佳化
第二部分:機器學習核心問題
1. 當模型遇到資料
2. 線性回歸
3. 利用主成分分析進行降維
4. 利用高斯混合模型進行密度估計
5. 利用支援向量機進行分類
我們可以用以下兩種策略來理解機器學習中的數學:
按從基礎到高階的順序構建概念。這通常是偏技術性領域(如數學)的首選方法。該策略的優點是,讀者可以隨時依賴自己以前學過的定義,不會遇到那些晦澀難懂、難以接受的觀點。但對於從業者來說,許多基礎概念本身並不怎麼有趣,因此大多數基礎定義會被他們很快遺忘。
從實際需求向下挖掘出更基礎的要求。這種標的驅動方法的優點是,讀者隨時都知道為什麼他們需要研究特定的概念,並且清晰地知道自己需要哪些知識。這種策略的缺點是知識的基礎並不穩固,讀者必須記住一組自己並不理解的單詞。
本書分為兩部分,第一部分講數學基礎,第二部分將第一部分的概念應用於基本的機器學習問題中,繼而形成了圖 1.1 中闡述的“機器學習四大支柱”。
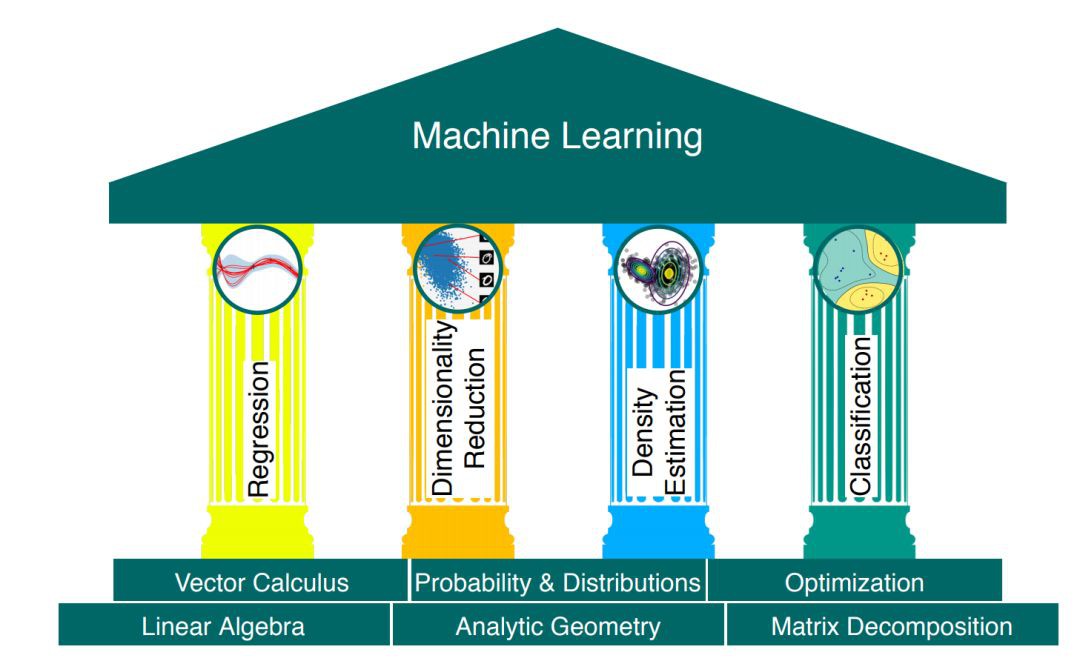
圖 1.1:機器學習的基礎和四大支柱
第一部分關於數學
我們將數值資料表示為向量,並將這些資料的表格表示為矩陣。向量和矩陣的研究被稱為線性代數,見本書第 2 章。
我們經常認為資料是一些真實潛在訊號的噪聲觀測結果,並希望透過機器學習從噪聲中識別出訊號。為此我們需要一種語言來量化噪聲的含義。我們也經常希望能有預測因子來表達某種不確定性,例如,量化我們對特定測試資料機率預測值的置信度。對不確定性的量化屬於機率論的領域,在本書第 6 章有所涉及。
為了把爬山法(hill-climbing)應用於訓練機器學習模型,我們需要形式化梯度的概念,它會告訴我們尋找解的方向。搜尋方向這個想法是透過微積分來形式化的,我們在第 5 章介紹了這一點。如何使用這些搜尋方向序列來找到山頂被稱為最佳化,見本書第 7 章。
第二部分關於機器學習
本書第二部分介紹了機器學習的四大支柱,如下表所示。表中的每一行區分了問題的相關變數是連續還是類別。我們解釋瞭如何將本書第一部分介紹的數學概念應用於機器學習演演算法的設計中。
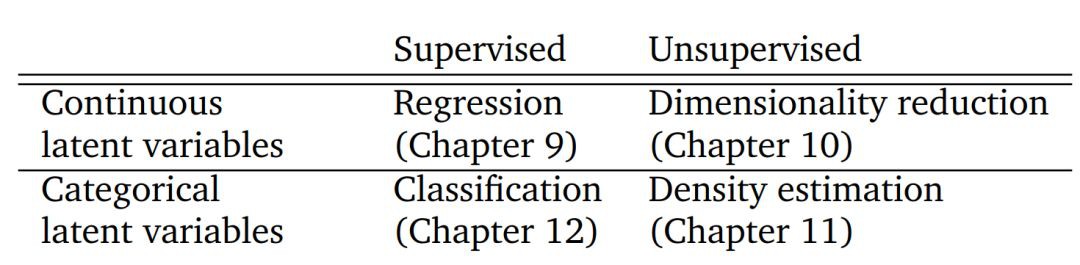
表 1.1:機器學習的四大支柱

圖 2.2:該思維導圖展示了本章介紹的概念及其與其他章節的關聯
END
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀:
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
80%的運營註定了打雜?因為你沒有搭建出一套有效的使用者運營體系
合作請加qq:365242293
更多相關知識請回覆:“ 月光寶盒 ”;
資料分析(ID : ecshujufenxi )網際網路科技與資料圈自己的微信,也是WeMedia自媒體聯盟成員之一,WeMedia聯盟改寫5000萬人群。

