
作者丨蘇劍林
單位丨廣州火焰資訊科技有限公司
研究方向丨NLP,神經網路
個人主頁丨kexue.fm
今天我們來談一下 Wasserstein 散度,簡稱“W 散度”。註意,這跟 Wasserstein 距離(Wasserstein distance,簡稱“W 距離”,又叫 Wasserstein 度量、Wasserstein metric)是不同的兩個東西。
本文源於論文 Wasserstein Divergence for GANs,論文中提出了稱為 WGAN-div 的 GAN 訓練方案。


這是一篇我很是欣賞卻默默無聞的 paper,我只是找文獻時偶然碰到了它。不管英文還是中文界,它似乎都沒有流行起來,但是我感覺它是一個相當漂亮的結果。

▲ WGAN-div的部分樣本(2w iter)
如果讀者需要入門一下 WGAN 的相關知識,不妨請閱讀拙作互懟的藝術:從零直達 WGAN-GP。
WGAN
我們知道原始的 GAN(SGAN)會有可能存在梯度消失的問題,因此 WGAN 橫空出世了。
W距離
WGAN 引入了最優傳輸裡邊的 W 距離來度量兩個分佈的距離:

這裡的 p̃(x) 是真實樣本的分佈,q(x) 是偽造分佈,c(x,y) 是傳輸成本,論文中用的是 c(x,y)=‖x−y‖;而 γ∈Π(p̃(x),q(x)) 的意思是說:γ 是任意關於 x,y 的二元分佈,其邊緣分佈則為 p̃(x) 和 q(y)。
直觀來看,γ 描述了一個運輸方案,而 c(x,y) 則是運輸成本,Wc(p̃(x),q(x)) 就是說要找到成本最低的那個運輸方案所對應的成本作為分佈度量。
對偶問題
W 距離確實是一個很好的度量,但顯然不好算。當 c(x,y)=‖x−y‖ 時,我們可以將其轉化為對偶問題:
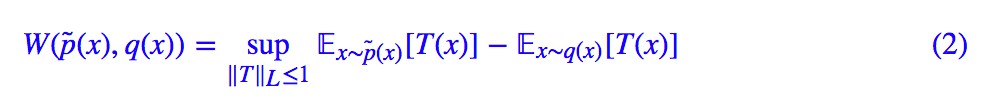
其中 T(x) 是一個標量函式,‖T‖L 則是 Lipschitz 範數:

說白了,T(x) 要滿足:

生成模型
這樣一來,生成模型的訓練,可以作為 W 距離下的一個最小-最大問題:
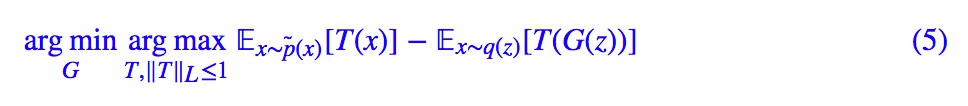
第一個 arg max 試圖獲得 W 距離的近似運算式,而第二個 arg min 則試圖最小化 W 距離。
然而,T 不是任意的,需要滿足 ‖T‖L≤1,這稱為 Lipschitz 約束(L 約束),該怎麼施加這個約束呢?因此,一方面,WGAN 開創了 GAN 的一個新流派,使得 GAN 的理論上了一個新高度,另一方面,WGAN 也挖了一個關於 L 約束的大坑,這個坑也引得不少研究者前僕後繼地跳坑。
L約束
目前,往模型中加入 L 約束,有三種主要的方案。
權重裁剪
這是 WGAN 最原始的論文所提出的一種方案:在每一步的判別器的梯度下降後,將判別器的引數的絕對值裁剪到不超過某個固定常數。
這是一種非常樸素的做法,現在基本上已經不用了。其思想就是:L 約束本質上就是要網路的波動程度不能超過一個線性函式,而啟用函式通常都滿足這個條件,所以只需要考慮網路權重,最簡單的一種方案就是直接限制權重範圍,這樣就不會抖動太劇烈了。
梯度懲罰
這種思路非常直接,即 ‖T‖L≤1 可以由 ‖∇T‖≤1 來保證,所以乾脆把判別器的梯度作為一個懲罰項加入到判別器的 loss 中:
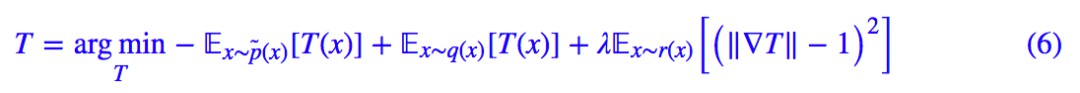
但問題是我們要求 ‖T‖L≤1 是在每一處都成立,所以 r(x) 應該是全空間的均勻分佈才行,顯然這很難做到。所以作者採用了一個非常機智(也有點流氓)的做法:在真假樣本之間隨機插值來懲罰,這樣保證真假樣本之間的過渡區域滿足 L 約束。
這種方案就是 WGAN-GP。顯然,它比權重裁剪要高明一些,而且通常都 work 得很好。但是這種方案是一種經驗方案,沒有更完備的理論支撐。
譜歸一化
另一種實現 L 約束的方案就是譜歸一化(SN),可以參考我之前寫的文章深度學習中的Lipschitz約束:泛化與生成模型。
本質上來說,譜歸一化和權重裁剪都是同一類方案,只是譜歸一化的理論更完備,結果更加鬆弛。而且還有一點不同的是:權重裁剪是一種“事後”的處理方案,也就是每次梯度下降後才直接裁剪引數,這種處理方案本身就可能導致最佳化上的不穩定;譜歸一化是一種“事前”的處理方案,它直接將每一層的權重都譜歸一化後才進行運算,譜歸一化作為了模型的一部分,更加合理一些。
儘管譜歸一化更加高明,但是它跟權重裁剪一樣存在一個問題:把判別器限制在了一小簇函式之間。也就是說,加了譜歸一化的 T,只是所有滿足 L 約束的函式的一小部分。因為譜歸一化事實上要求網路的每一層都滿足 L 約束,但這個條件太死了,也許這一層可以不滿足 L 約束,下一層則滿足更強的 L 約束,兩者抵消,整體就滿足 L 約束,但譜歸一化不能適應這種情況。
WGAN-div
在這種情況下,Wasserstein Divergence for GANs 引入了 W 散度,它聲稱:現在我們可以去掉 L 約束了,並且還保留了 W 距離的好性質。
論文回顧
有這樣的好事?我們來看看 W 散度是什麼。一上來,作者先回顧了一些經典的 GAN 的訓練方案,然後隨手扔出一篇文獻,叫做 Partial differential equations and monge-kantorovich mass transfer [1],裡邊提供了一個方案(下麵的出場順序跟論文有所不同),能直接將 T 訓練出來,標的是(跟原文的寫法有些不一樣):

這裡的 r(x) 是一個非常寬鬆的分佈,我們後面再細談。整個 loss 的意思是:你只要按照這個公式將 T 訓練出來,它就是 (2) 式中 T 的最優解,也就是說,接下來只要把它代進 (2) 式,就得到了 W 距離,最小化它就可以得到生成器了。

一些註解
首先,我為什麼說作者“隨手”跑出一篇論文呢?因為作者確實是隨手啊……
作者直接說“According to [19]”,然後就給出了後面的結果,[19] 就是這篇論文,是一篇最優傳輸和偏微分方程的論文,59 頁。我翻來翻去,才發現作者取用的應該是 36 頁和 40 頁的結果(不過翻到了也沒能進一步看懂,放棄了),也不提供多一點參考資料,尷尬。
還有後面的一些引理,作者也說“直接去看 [19] 的 discussion 吧”….. 然後,讀者更多的疑問是:這玩意跟梯度懲罰方案有什麼差別,加個負號變成最小化不都是差不多嗎?
做實驗時也許沒有多大差別,但是理論上的差別是很大的,因為 WGAN-GP 的梯度懲罰只能算是一種經驗方案,而 (7) 式是有理論保證的。後面我們會繼續講完它。
W散度
式 (7) 是一個理論結果,而不管怎樣深度學習還是一門理論和工程結合的學科,所以作者一般化地考慮了下麵的標的:

其中 k>0,p>1。基於此,作者證明瞭 Wk,p 有非常好的性質:
1. Wk,p 是個對稱的散度。散度的意思是:D[P,Q]≥0 且 D[P,Q]=0⇔P=Q,它跟“距離”的差別是它不滿足三角不等式,也有叫做“半度量”、“半距離”的。Wk,p 是一個散度,這已經非常棒了,因為我們大多數 GAN 都只是在最佳化某個散度而已。散度意味著當我們最小化它時,我們真正是在縮小兩個分佈的距離。
2. Wk,p 的最優解跟 W 距離有一定的聯絡。(7) 式就是一個特殊的 W1/2,2。這說明當我們最大化 Wk,p 得到 T 之後,可以去掉梯度項,透過最小化 (8) 來訓練生成器。這也表明以 Wk,p 為標的,性質跟 W 距離類似,不會有梯度消失的問題。
3. 這是我覺得最逗的一點,作者證明瞭:
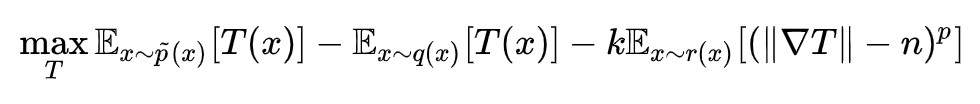
不總是一個散度。當 n=1,p=2 時這就是 WGAN-GP 的梯度懲罰,作者說它不是一個散度,明擺著要跟 WGAN-GP 對著乾。不是散度意味著 WGAN-GP 在訓練判別器的時候,並非總是會在拉大兩個分佈的距離(鑒別者在偷懶,沒有好好提升自己的鑒別技能),從而使得訓練生成器時回傳的梯度不準。
WGAN-div
好了,說了這麼久,終於可以引入 WGAN-div 了,其實就是基於 (9) 的 WGAN 的訓練樣式了:

前者是為了透過 W 散度 Wk,p 找出 W 距離中最優的 T,後者就是為了最小化 W 距離。所以,W 散度的角色,就是一個為 W 距離的默默無聞的填坑者,再結合這篇論文字身的鮮有反響,我覺得這種感覺更加強烈了。
實驗
k,p的選擇
作者透過做了一批搜尋實驗,發現 k=2,p=6 時效果最好(用 FID 為指標)。這進一步與 WGAN-GP 的做法有出入:範數的二次冪並非是最好的選擇。
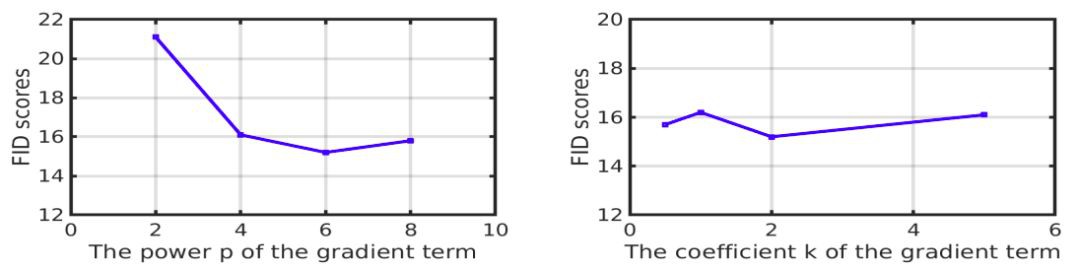
▲ 不同的k,p對FID的影響(FID越小越好)
r(x)的選擇
前面我們就說過,W 散度中對 r(x) 的要求非常寬鬆,論文也做了一組對比實驗,對比了常見的做法:
-
真假樣本隨機插值
-
真樣本之間隨機插值、假樣本之間隨機插值
-
真假樣本混合後,隨機選兩個樣本插值
-
直接選原始的真假樣本混合
-
直接只選原始的假樣本
-
直接只選原始的真樣本
結果發現,在 WGAN-div 之下這幾種做法表現都差不多(用 FID 為指標),但是對於 WGAN-GP,這幾種做法差別比較大,而且 WGAN-GP 中最好的結果比 WGAN-div 中最差的結果還要差。這時候 WGAN-GP 就被徹底虐倒了。

▲ 不同取樣方式所導致的不同模型的FID不同差異(FID越小越好)
這裡邊的差別不難解釋,WGAN-GP 是憑經驗加上梯度懲罰,並且“真假樣本隨機插值”只是它無法做到全空間取樣的一個折衷做法,但是 W 散度和 WGAN-div,從理論的開始,就沒對 r(x) 有什麼嚴格的限制。
其實,原始 W 散度的構造(這個需要看參考論文)基本上只要求 r(x) 是一個樣本空間跟 p̃(x)、q(x) 一樣的分佈,非常弱的要求,而我們一般選擇為 p̃(x)、q(x) 兩者共同衍生出來的分佈,相對來說收斂快一點。
參考程式碼
自然是用 Keras 寫的,人生苦短,我用 Keras。
https://github.com/bojone/gan/blob/master/keras/wgan_div_celeba.py
隨機樣本(自己的實驗結果):
▲ WGAN-div的部分樣本(2w iter)
當然,原論文的實驗結果也表明 WGAN-div 是很優秀的:

▲ WGAN-div與不同的模型在不同的資料集效果比較(指標為FID,越小越好)
結語
不知道業界是怎麼看這篇 WGAN-div 的,也許是覺得跟 WGAN-GP 沒什麼不同,就覺得沒有什麼意思了。不過我是很佩服這些從理論上推導並且改進原始結果的大牛及其成果。雖然看起來像是隨手甩了一篇論文然後說“你看著辦吧”的感覺,但這種將理論和實踐結合起來的結果仍然是很有美感的。
本來我對 WGAN-GP 是多少有些芥蒂的,總覺得它太醜,不想用。但是 WGAN-div 出現了,在我心中已經替代了 WGAN-GP,並且它不再醜了。
相關連結
[1]. Evans, L.C.: Partial differential equations and monge-kantorovich mass transfer. Current developments in mathematics 1997(1) (1997) 65–126

點選以下標題檢視作者其他文章:
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視作者部落格
