在斯坦福大學發起的 SQuAD(Stanford Question Answering Dataset)文字理解挑戰賽中,微軟亞洲研究院和阿裡巴巴的 R-NET 模型和 SLQA 模型在 EM 值(表示預測答案和真實答案完全匹配)上分別以 82.650 和 82.440 的成績率先超過人類(82.304)。
作者丨胡明昊
學校丨國防科學技術大學博士生
研究方向丨自動問答系統
引言
教機器學會閱讀是近期自然語言處理領域的研究熱點之一,也是人工智慧在處理和理解人類語言行程中的一個長期標的。得益於深度學習技術和大規模標註資料集的發展,用端到端的神經網路來解決閱讀理解任務取得了長足的進步。
本文是一篇機器閱讀理解的綜述文章,主要聚焦於介紹公佈在 SQuAD(Stanford Question Answering Dataset)榜單上的各類模型,併進行系統地對比和總結。
SQuAD 簡介
SQuAD 是由 Rajpurkar 等人 [1] 提出的一個最新的閱讀理解資料集。該資料集包含 10 萬個(問題,原文,答案)三元組,原文來自於 536 篇維基百科文章,而問題和答案的構建主要是透過眾包的方式,讓標註人員提出最多 5 個基於文章內容的問題並提供正確答案,且答案出現在原文中。
SQuAD 和之前的完形填空類閱讀理解資料集如 CNN/DM [2],CBT [3] 等最大的區別在於:SQuAD 中的答案不在是單個物體或單詞,而可能是一段短語,這使得其答案更難預測。
SQuAD 包含公開的訓練集和開發集,以及一個隱藏的測試集,其採用了與 ImageNet 類似的封閉評測的方式,研究人員需提交演演算法到一個開放平臺,並由 SQuAD 官方人員進行測試並公佈結果。
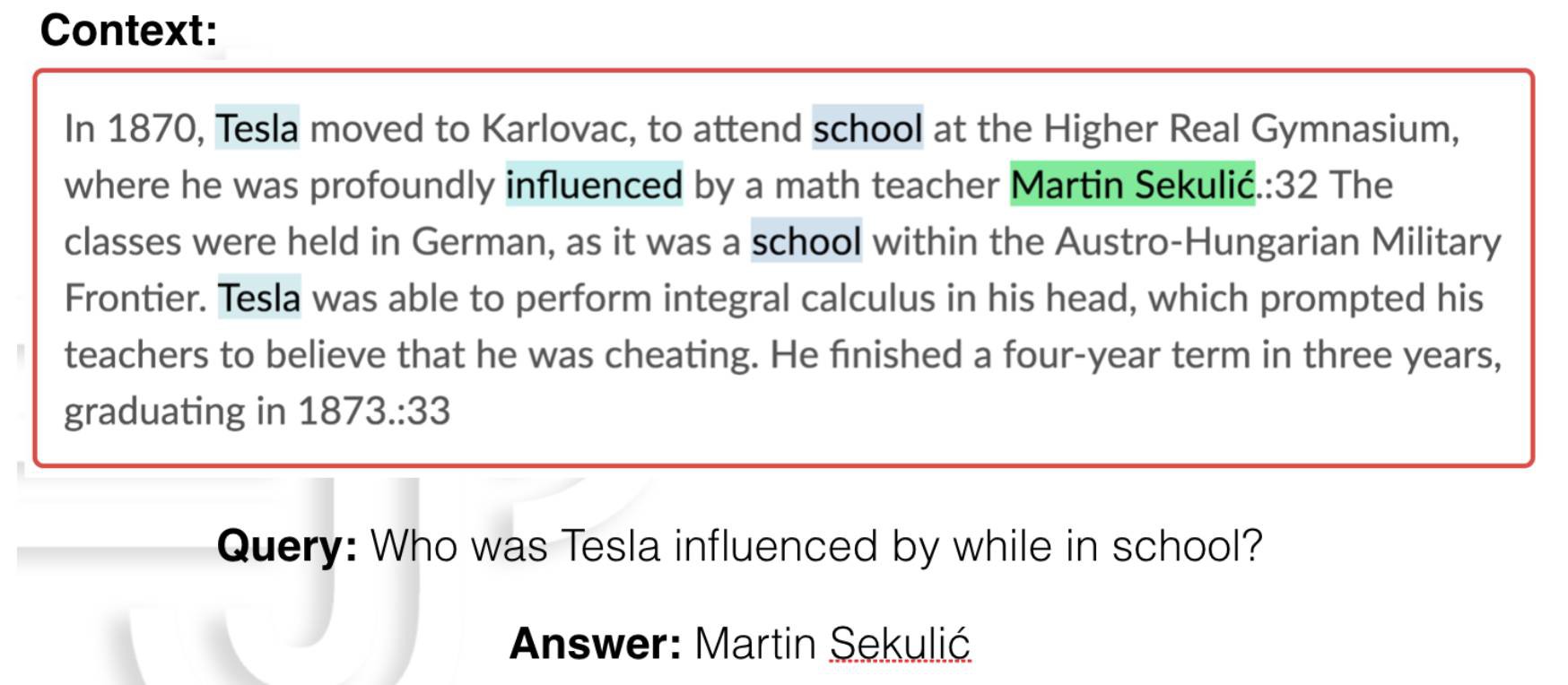
△ 圖1:一個(問題,原文,答案)三元組
模型
自從 SQuAD 資料集公佈以來,大量具有代表性的模型紛紛湧現,極大地促進了機器閱讀理解領域的發展,下麵就 SQuAD 榜單上代表性的模型進行介紹。
總的來說,由於 SQuAD 的答案限定於來自原文,模型只需要判斷原文中哪些詞是答案即可,因此是一種抽取式的 QA 任務而不是生成式任務。
幾乎所有做 SQuAD 的模型都可以概括為同一種框架:Embed 層,Encode 層,Interaction 層和 Answer 層。
Embed 層負責將原文和問題中的 tokens 對映為向量表示;Encode 層主要使用 RNN 來對原文和問題進行編碼,這樣編碼後每個 token 的向量表示就蘊含了背景關係的語意資訊;Interaction 層是大多數研究工作聚焦的重點,該層主要負責捕捉問題和原文之間的互動關係,並輸出編碼了問題語意資訊的原文表示,即 query-aware 的原文表示;最後 Answer 層則基於 query-aware 的原文表示來預測答案範圍。
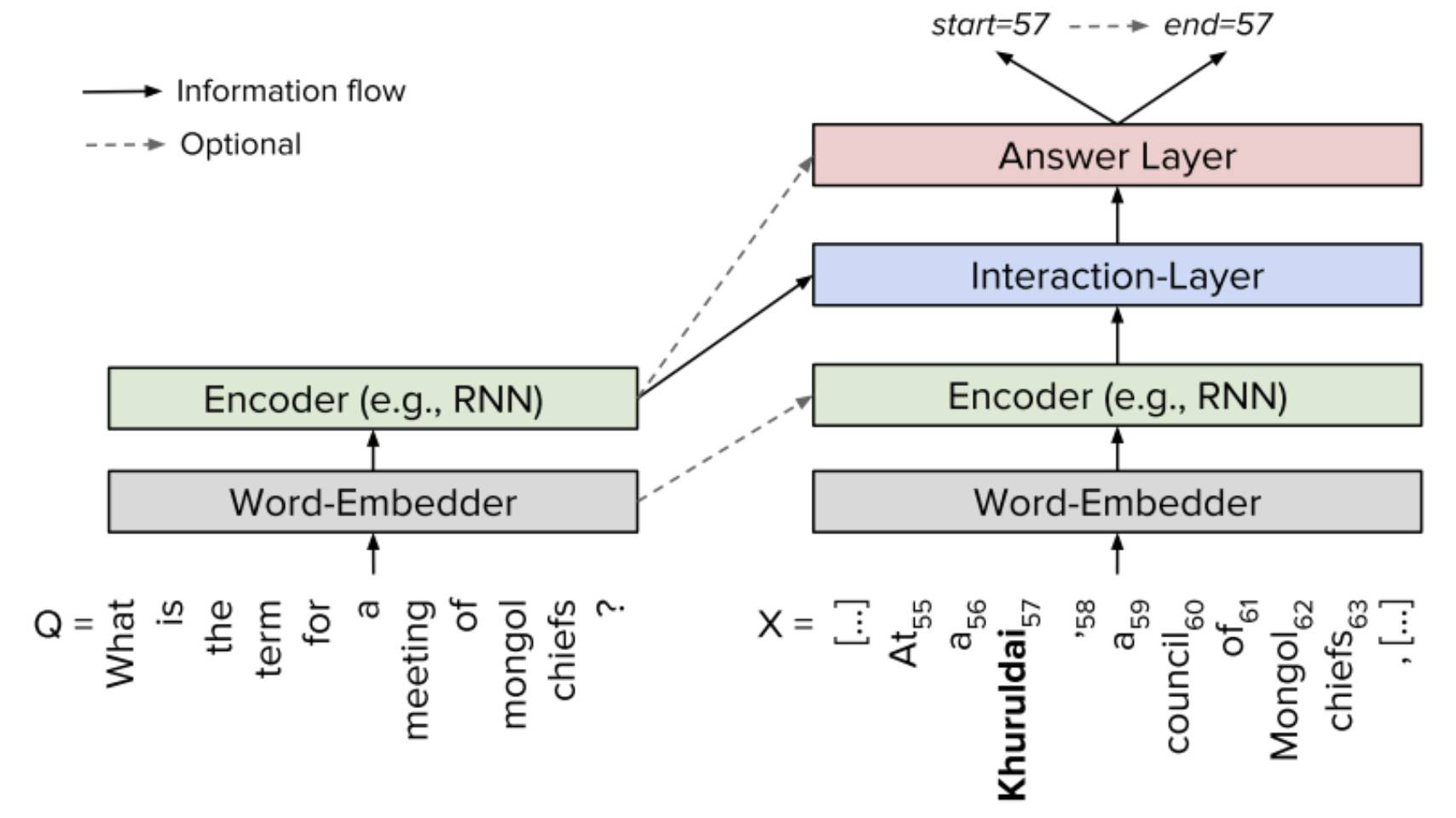
△ 圖2:一個高層的神經 QA 系統基本框架,來自[8]
Match-LSTM
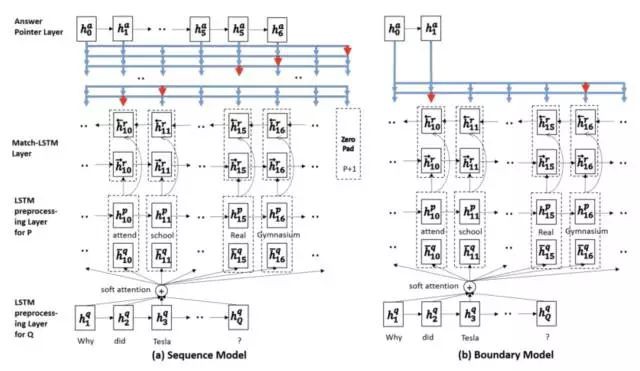
Match-LSTM [4] 的 Answer 層包含了兩種預測答案的樣式,分別為 Sequence Model 和 Boundary Model。
Sequence Model 將答案看做是一個整陣列成的序列,每個整數表示選中的 token 在原文中的位置,因此模型按順序產生一系列條件機率,每個條件機率表示基於上輪預測的 token 產生的下個 token 的位置機率,最後答案總機率等於所有條件機率的乘積。
Boundary Model 簡化了整個預測答案的過程,只預測答案開始和答案結束位置,相比於 Sequence Model 極大地縮小了搜尋答案的空間。
最後的實驗也顯示簡化的 Boundary Model 相比於複雜的 Sequence Model 效果更好,因此 Boundary Model 也成為後來的模型用來預測答案範圍的標配。
在模型實現上,Match-LSTM 的主要步驟如下:
-
Embed 層使用詞向量表示原文和問題;
-
Encode 層使用單向 LSTM 編碼原文和問題 embedding;
-
Interaction 層對原文中每個詞,計算其關於問題的註意力分佈,並使用該註意力分佈彙總問題表示,將原文該詞表示和對應問題表示輸入另一個 LSTM 編碼,得到該詞的 query-aware 表示;
-
在反方向重覆步驟 2,獲得雙向 query-aware 表示;
-
Answer 層基於雙向 query-aware 表示使用 Sequence Model 或 Boundary Model 預測答案範圍。
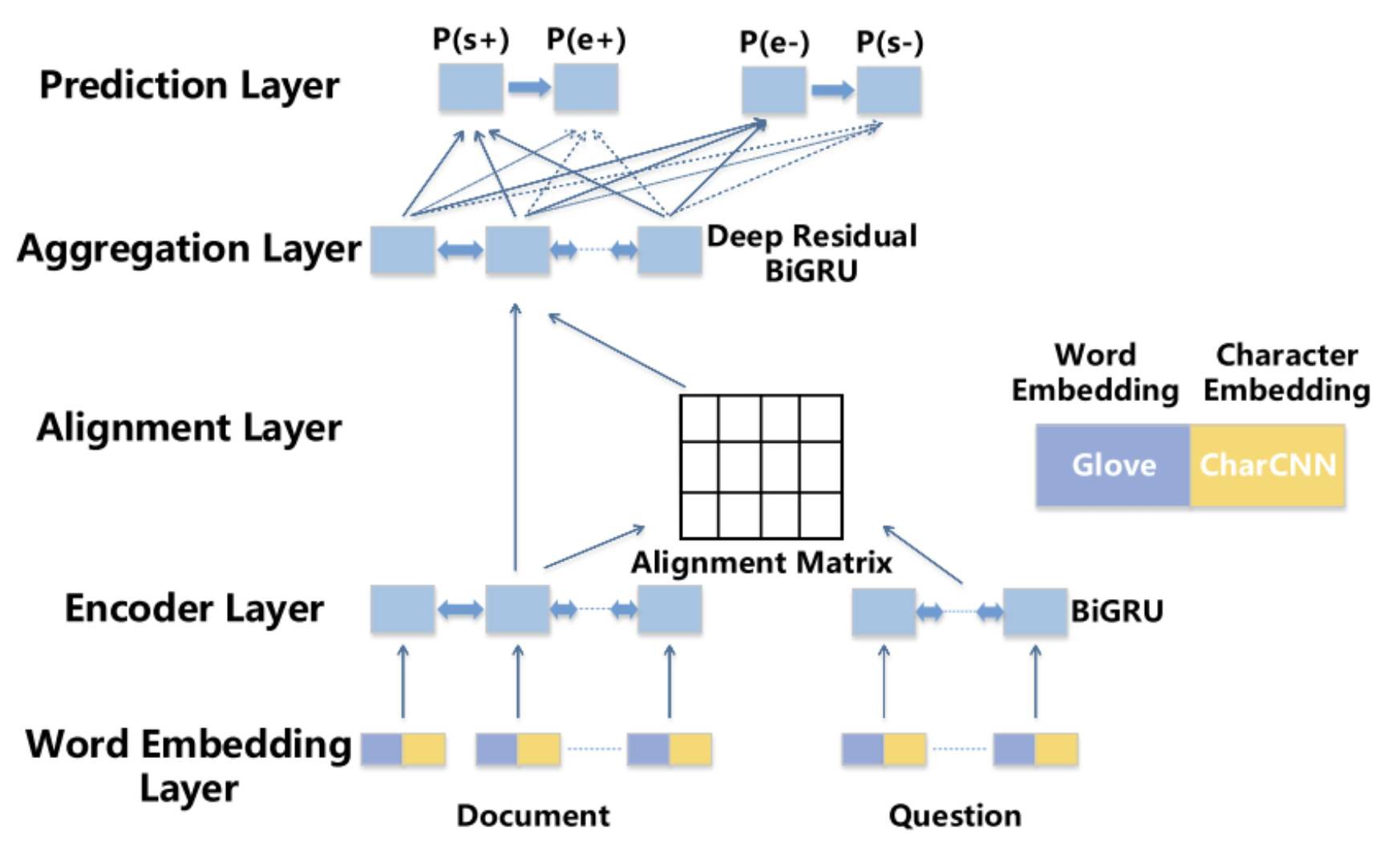
BiDAF

相比於之前工作,BiDAF(Bi-Directional Attention Flow)[5] 最大的改進在於 Interaction 層中引入了雙向註意力機制,即首先計算一個原文和問題的 Alignment matrix,然後基於該矩陣計算 Query2Context 和 Context2Query 兩種註意力,並基於註意力計算 query-aware 的原文表示,接著使用雙向 LSTM 進行語意資訊的聚合。
另外,其 Embed 層中混合了詞級 embedding 和字元級 embedding,詞級 embedding 使用預訓練的詞向量進行初始化,而字元級 embedding 使用 CNN 進一步編碼,兩種 embedding 共同經過 2 層 Highway Network 作為 Encode 層輸入。
最後,BiDAF 同樣使用 Boundary Model 來預測答案開始和結束位置。
Dynamic Coattention Networks
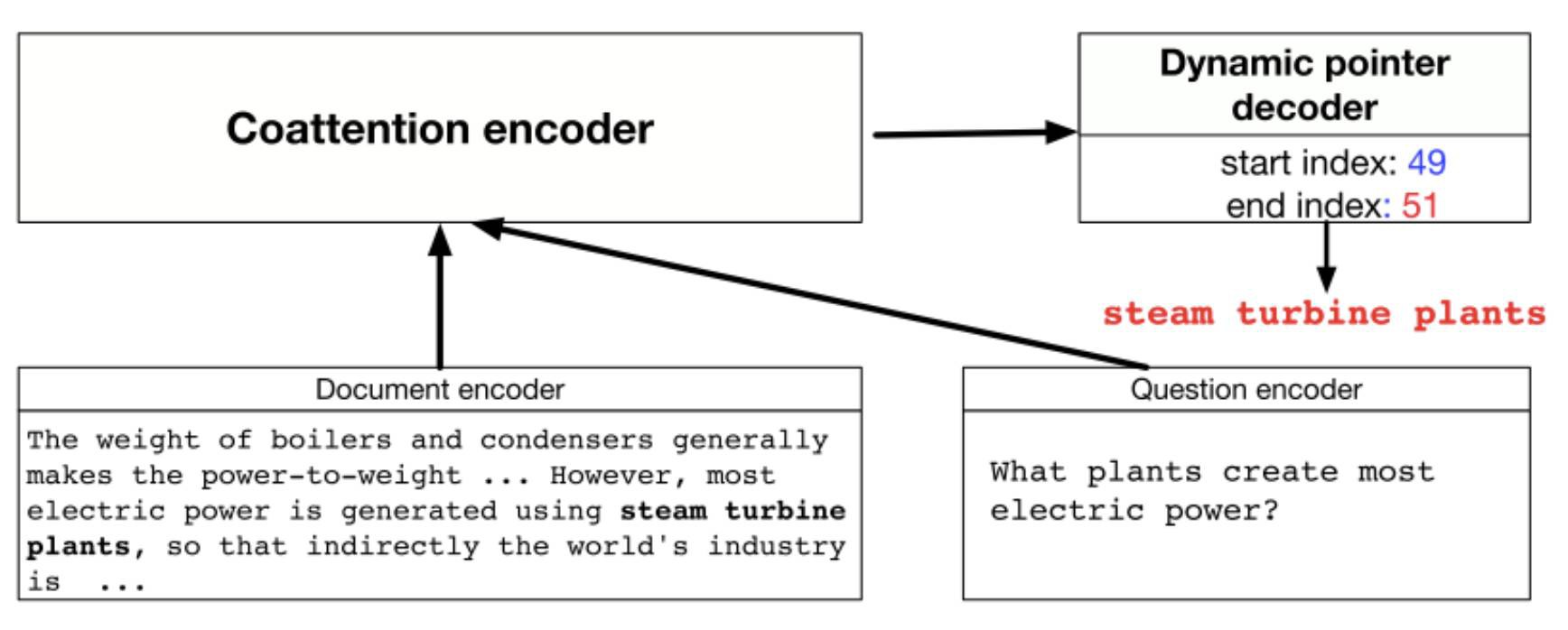
DCN [6] 最大的特點在於 Answer 層,其 Answer 層使用了一種多輪迭代 pointing 機制,每輪迭代都會產生對答案開始和結束位置的預測,並基於這兩個預測使用 LSTM 和 Highway Maxout Network 來更新下一輪的答案範圍預測。
而在 Interaction 層,DCN 使用和 BiDAF 類似的雙向註意力機制計算 query-aware 的原文表示。
Multi-Perspective Matching
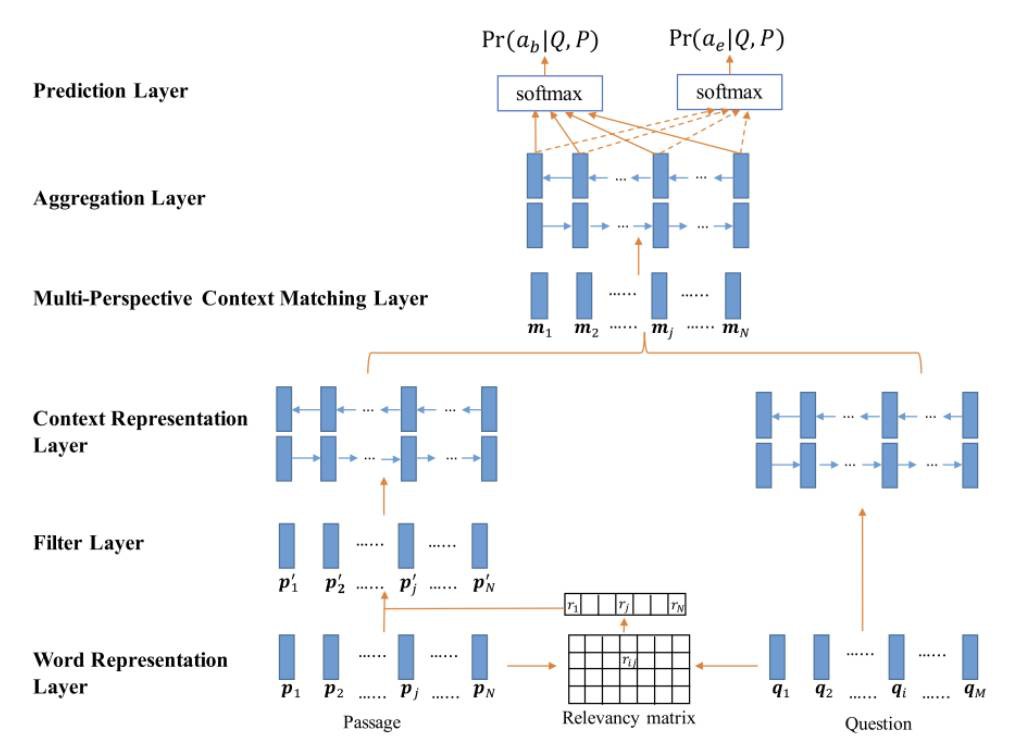
Multi-Perspective Matching [7] 在 Encode 層同樣使用 char,word 兩個 embedding,只不過 char embedding 使用 LSTM 進行編碼。
在 Encode 層之前,該模型使用一個過濾操作,作用是過濾掉那些和問題相關度低的原文詞。該模型最大的特點在 Interaction 層,該層針對每個原文詞使用一種 multi-perspective 的匹配函式計算其和問題的匹配向量,並使用 BiLSTM 來進一步聚合這些匹配向量。
匹配的形式包括每個原文詞和整個問題的表示匹配,每個原文詞和每個問題詞匹配後進行最大池化,和每個原文詞和每個問題詞匹配後進行平均池化。
最後在 Answer 層,基於匹配向量聚合表示使用兩個前饋網路來預測答案開始和結束位置。
FastQAExt

FastQAExt [8] 使用了一種輕量級的架構,其 Embed 層除了 word 和 char 兩種 embedding 作為輸入以外,還額外使用了兩個特徵:
1. binary 特徵表示原文詞是否出現在問題中;
2. weighted 特徵表示原文詞對於問題中所有詞的相似度。並且這兩個特徵同樣用在了問題詞上。
在 Interaction 層,FastQAExt 使用了兩種輕量級的資訊 fusion 策略:
1. Intra-Fusion,即每個原文詞和其他原文詞計算相似度,並彙總得到原文總表示,接著將該原文詞和對應原文總表示輸入 Highway Networks 進行聚合,聚合後原文詞表示進一步和背景關係詞表示進行類似的聚合;
2. Inter-Fusion,即對每個原文詞計算和問題詞的相似度,並彙總得到問題總表示,接著將將該原文詞和對應問題總表示輸入 Highway Networks 進行聚合,得到 query-aware 原文表示。
此外,在 Answer 層,FastQAExt 首先計算了一個問題的總表示,接著將 query-aware 原文表示和問題總表示共同輸入兩個前饋網路產生答案開始和結束位置機率。在確定答案範圍時,FastQAExt 使用了 Beam-search。
jNet
jNet [9] 的 baseline 模型和 BiDAF 類似,其在 Interaction 層除了對每個原文詞計算一個對應的問題表示以外,還將 Alignment Matrix 按原文所在維度進行池化(最大池化和平均池化),池化後的值表示原文各詞的重要程度,因此基於該值對原文表示進行過濾,剔除不重要的原文詞。
在 Answer 層,jNet 不僅先預測答案開始位置再預測答案結束位置,還反向地先預測答案結束位置再預測答案開始位置。最後對兩方向機率求平均後作為總機率輸出。
jNet 的最大創新在於對問題的理解和適應。為了在編碼問題表示時考慮句法資訊,jNet 使用 TreeLSTM 對問題進行編碼,並將編碼後表示作為 Interaction 層的輸入。
為了對不同問題進行適應,jNet 首先使用了問題型別的 embedding,將該 embeeding 作為 Interaction 層輸入。
另外,jNet 定義了 K 個 cluster 的中心向量,每個 cluster model 了一個特定的問題型別比如“when“,”where”等,接下來的適應演演算法分為兩步:adapting 和 updating。
Adapting 指根據問題總表示和 K 個 cluster 的相似度來更新出一個新的問題表示,並輸入 Interaction 層;Updating 層旨在修改 K 個 cluster 的中心以令每個 cluster 可以 model 不同型別的問題。
Ruminating Reader
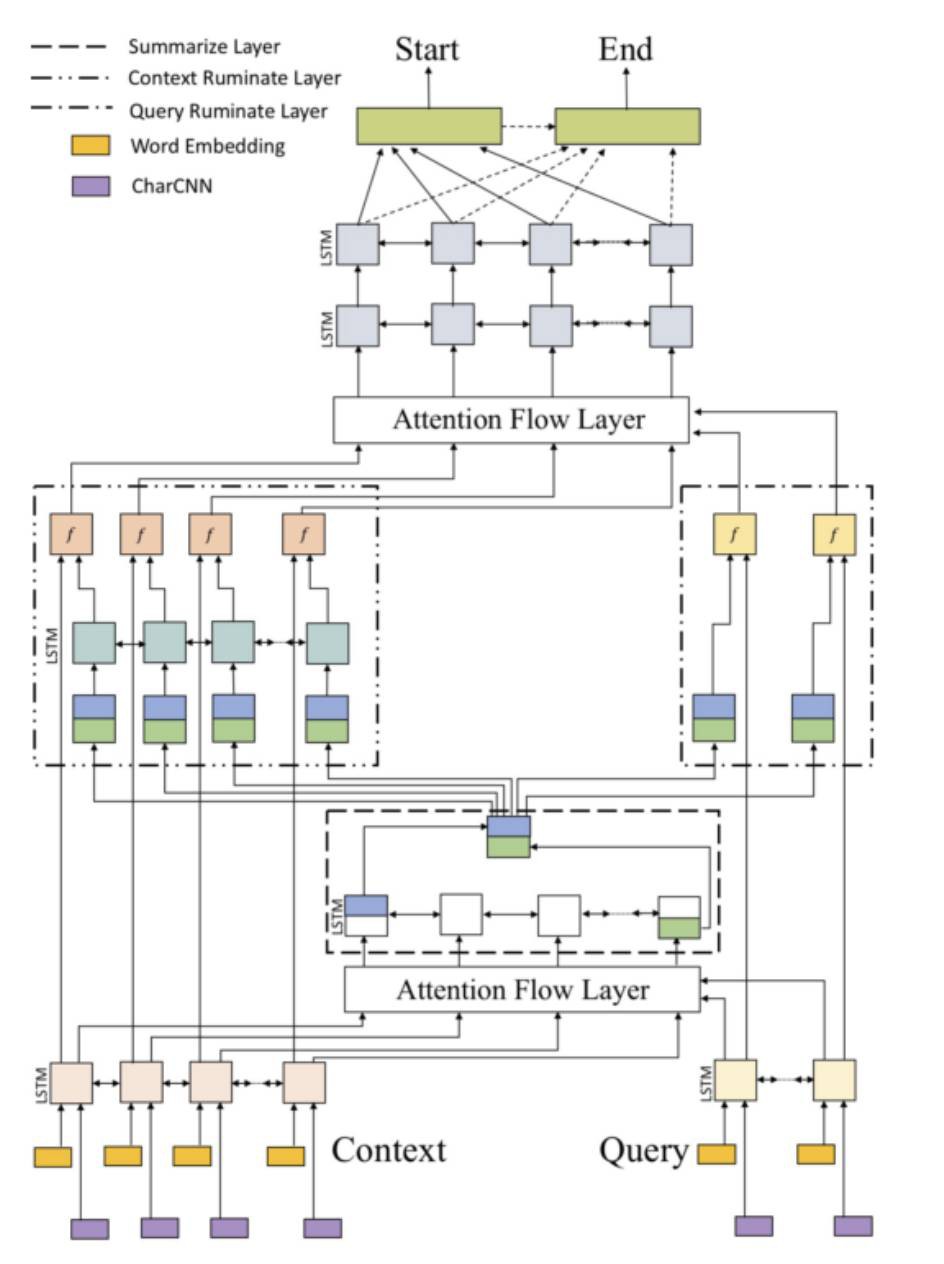
Ruminating Reader [10] 是 BiDAF 的改進和擴充套件,它將之前的單 Interaction 層擴充套件為了雙 Interaction 層。
第一個 Interaction 層和 BiDAF 的 Interaction 層相同,輸出 query-aware 的原文表示。query-aware 原文表示經過一個雙向 LSTM 編碼,其輸出的最後一位隱層狀態作為 query-aware 原文表示的總結。
接著,該總結向量依次與各原文詞表示和各問題詞表示經過一個 Highway Network 處理,以將總結向量的資訊重新融入原文和問題表示當中。
最後,基於更新後的原文和問題表示,使用第二個 Interaction 層來捕捉它們之間的互動,並生成新的 query-aware 的原文表示。Ruminating Reader 的 Embed 層,Encode 層和 Answer 層和 BiDAF 相同。
ReasoNet

和之前介紹的 Embed-Encode-Interaction-Answer 框架不同,ReasoNet [11] 使用了 Memory Networks 的框架[12]。
在使用 BiRNN 編碼問題和原文後,問題的最後一位隱層狀態初始化為一個中間狀態 s,而原文和問題表示作為 Memory。
接下來是一個多輪迭代的過程,在每一輪迭代中,中間狀態 s 首先經過一個邏輯回歸函式來輸出一個 binary random variable t,t 為真,那麼 ReasoNet 停止,並且用當前中間狀態 s 輸出到 Answer 模組產生對答案的預測。
否則,中間狀態 s 會和 Memory(原文和問題)中每一位表示計算註意力,並基於註意力求原文和問題的加權表示 x,x 和 s 共同作為一個 RNN 的輸入,產生新的中間狀態 s 併進入下一輪迭代。
由於出現了 binary random variable,ReasoNet 使用了強化學習的方法進行訓練。
R-NET
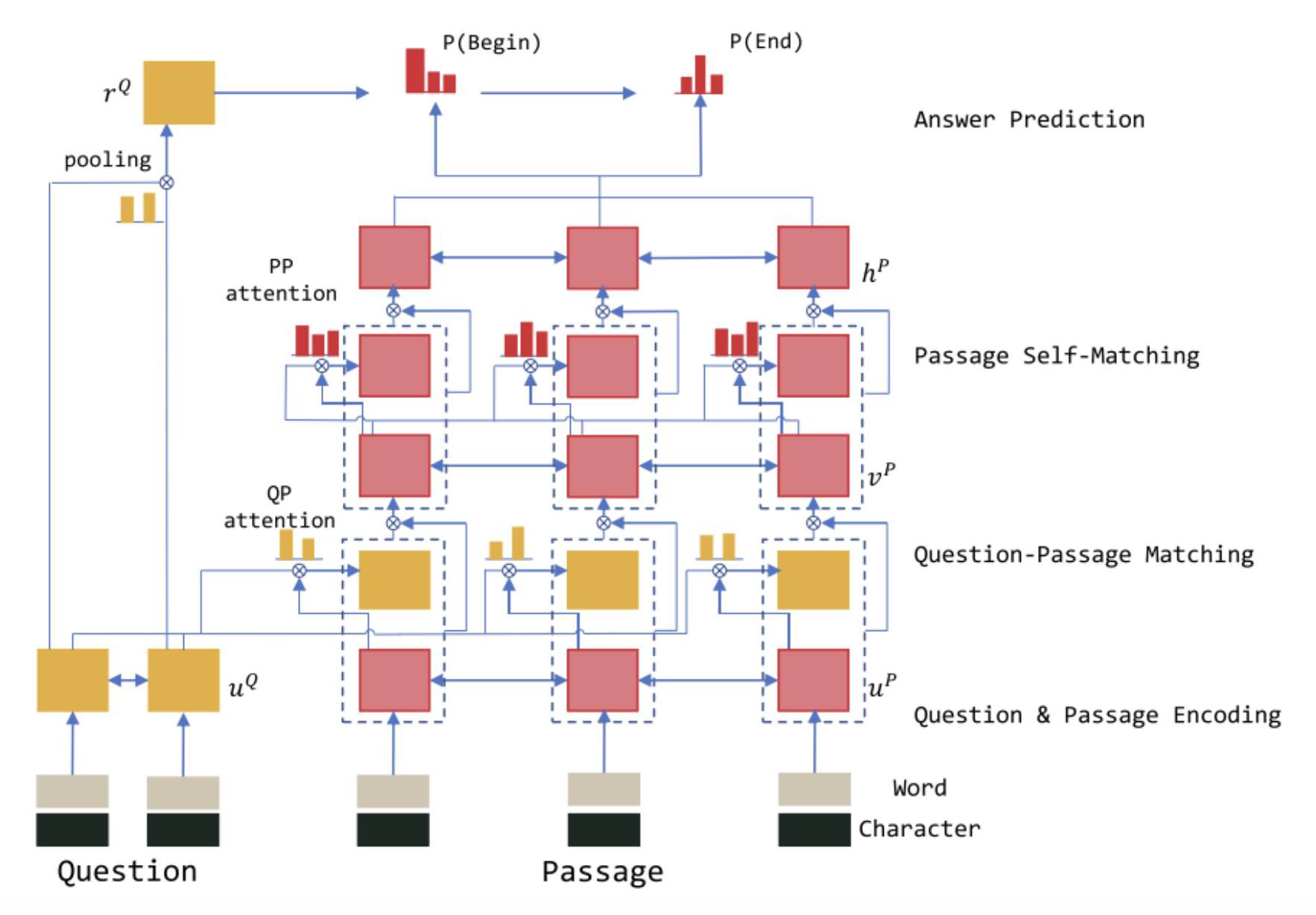
R-NET [13] 同樣使用了雙 Interaction 層架構,其第一 Interaction 層負責捕捉原文和問題之間的互動資訊,而第二 Interaction 層負責捕捉原文內部各詞之間的互動資訊。
具體來說,在第一 Interaction 層,r-net 首先使用了類似於 Match-LSTM 的方法,即對原文中每個詞,計算其關於問題的註意力分佈,並使用該註意力分佈彙總問題表示,將原文該詞表示和對應問題表示輸入 RNN 編碼,得到該詞的 query-aware 表示。
不同的是,在原文詞表示和對應問題表示輸入 RNN 之前,r-net 使用了一個額外的門來過濾不重要的資訊。
接著,在第二 Interaction 層,r-net 使用了同樣的策略來將 query-aware 表示進一步和自身進行匹配,將回答答案所需的證據和問題資訊進行語意上的融合,得到最終的原文表示。
在其他方面,r-net 的 Embed 層同樣使用了 word 和 char 兩種 embedding 以豐富輸入特徵。
在 Answer 層,r-net 首先使用一個 attention-pooling 的問題向量作為一個 RNN 的初始狀態,該 RNN 的狀態和最終的原文表示共同輸入一個 pointer networks 以產生答案開始機率。
接著基於開始機率和原文表示產生另一個 attention-pooling 向量,該向量和 RNN 狀態共同經過一次 RNN 更新後得到 RNN 的新狀態,並基於新狀態來預測答案結束機率。
Mnemonic Reader
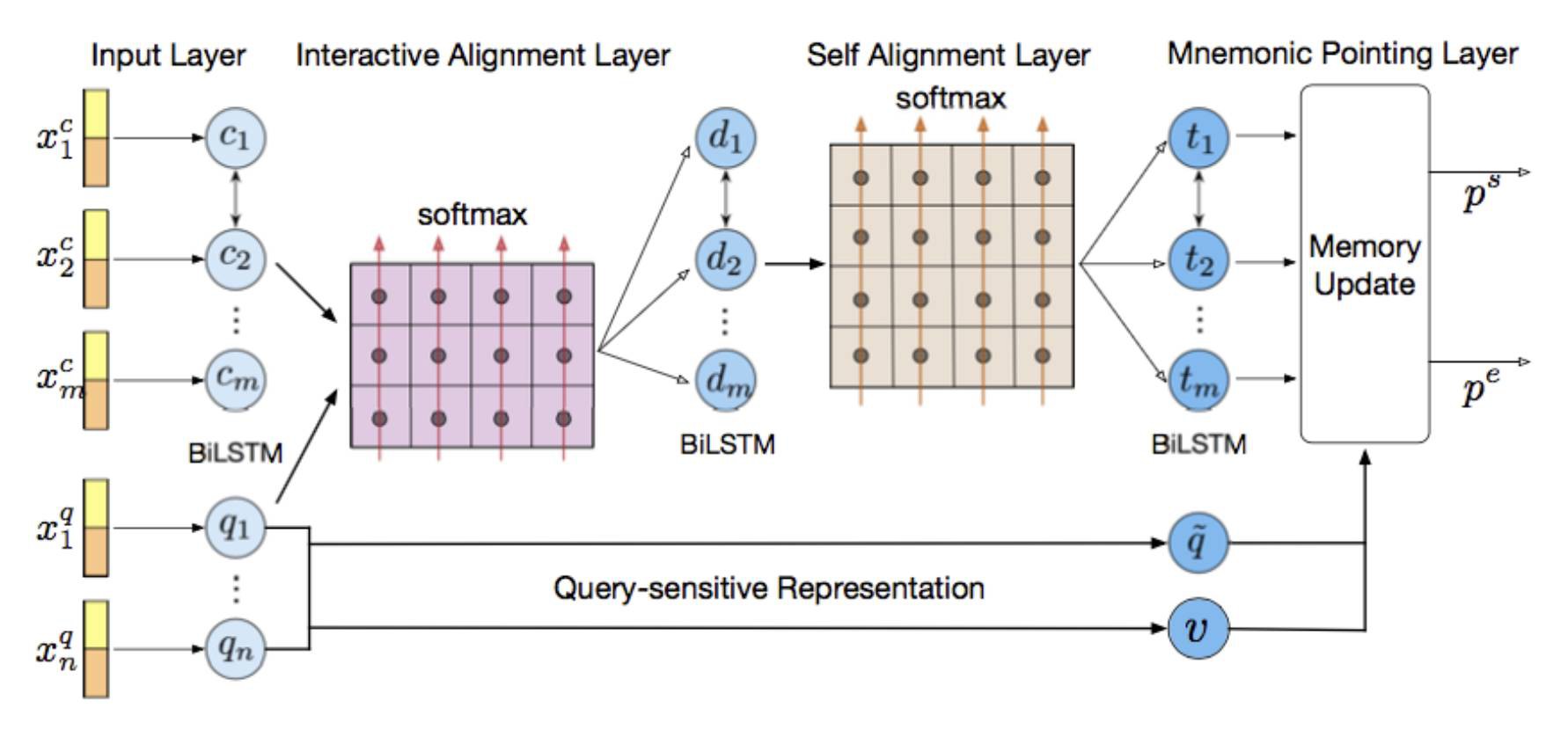
相比於之前的工作,我們的 Mnemonic Reader [14] 同樣使用了類似於 r-net 和 Ruminating Reader 的兩層 Interaction 層設計。
其中第一個 Interaction 層負責捕捉原文和問題之間的互動資訊,第二 Interaction 層負責捕捉原文內部的長時依賴資訊。
不同於 r-net 的是,r-net 使用了單向註意力+門機制來編碼這些互動資訊,而 Mnemonic Reader 使用了雙向註意力機制來編碼互動資訊,因此能夠捕捉更加細粒度的語意資訊。
在 Answer 層,我們使用對問題敏感的表示方法,具體來說,問題表示分為兩種:顯式的問題型別 embedding 和隱式的問題向量表示。
進一步地,我們使用了 Memory Network [12] 的框架來預測答案範圍,將問題表示作為一個可更新的記憶向量,在每次預測答案機率後將候選答案資訊更新至記憶向量中。
該過程可以持續多輪,因此可以根據之前預測資訊來不斷修正當前預測,直到產生正確的答案範圍。
效能對比
下圖是 SQuAD 榜單排名,其中 EM 表示預測答案和真實答案完全匹配,而 F1 用來評測模型的整體效能。
值得一提的是,人類在 SQuAD 資料集上的效能分別為 82.3 和 91.2,微軟亞洲研究院的 R-NET 模型和阿裡巴巴的 SLQA 模型在 EM 值上分別以 82.650 和82.440 率先超過人類。
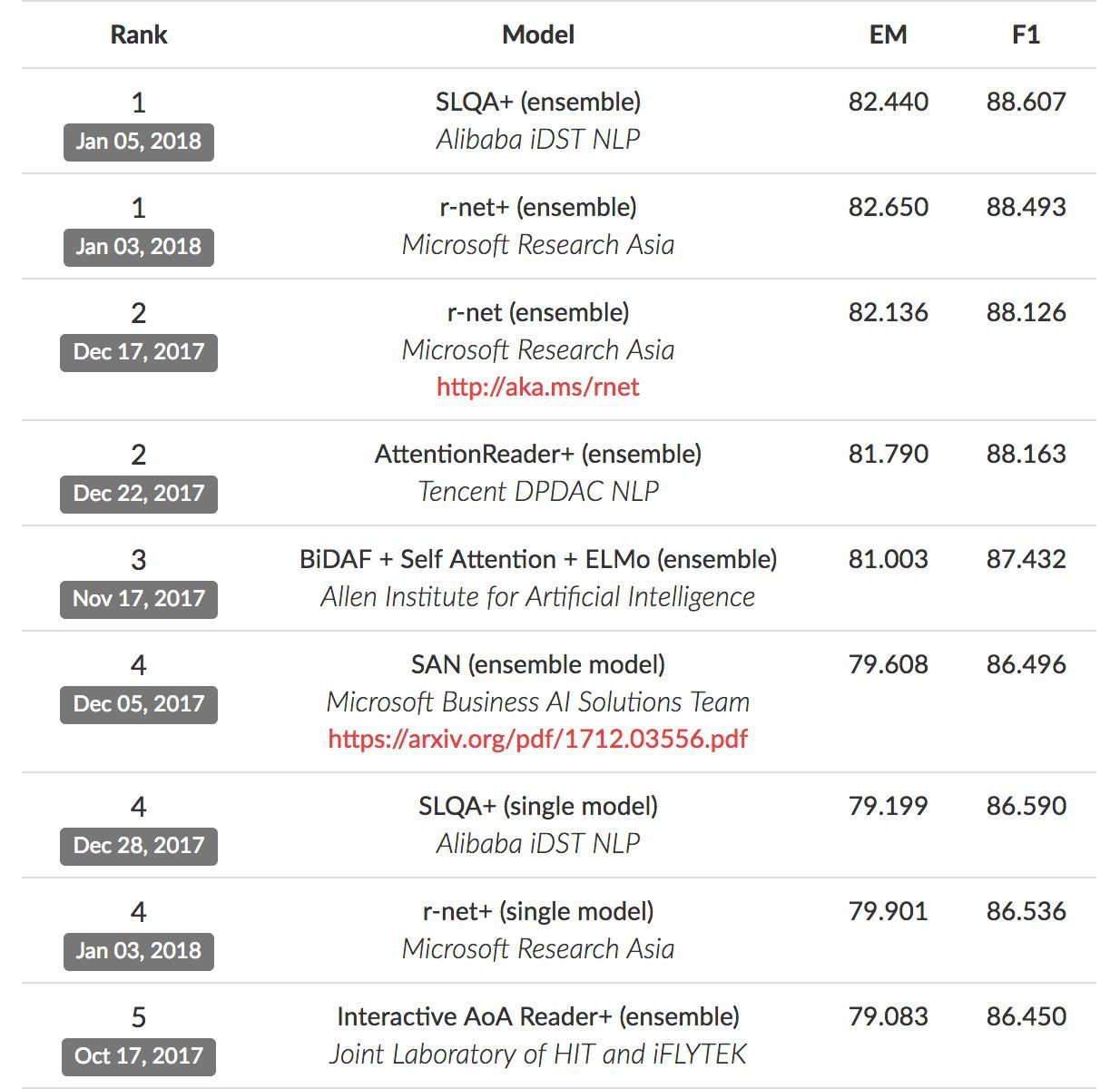
△ 圖3:SQuAD leaderboard上的各模型效能對比(2018年1月13日)
總結
總結以上工作,有以下幾點思考:
1) 大規模語料集的構建是推進機器閱讀理解發展的重要前提。從 15 年提出的 CNN/DM 完形填空資料集,到近期的 SQuAD 資料集,再到之後的若干新資料集,每一個新資料集都提出了當前方法無法有效解決的新問題,從而促使研究人員不斷探索新的模型,促進了該領域的發展。
2) 針對抽取式閱讀理解任務,可以看到有如下幾個技術創新點:
-
建立在單向或雙向註意力機制上的 Interaction 層對於模型理解原文和問題至關重要,而[10],[13]和[14]中更複雜的雙 Interaction 層設計無疑要優於之前的單 Interaction 層設計,原因是在問題-原文互動層之上的原文自互動層使得更多的語意資訊能在原文中流動,因此在某種程度上部分解決了長文字中存在的長時依賴問題。
-
多輪推理機制如[6],[11]和[14]對於回答覆雜問題具備一定幫助,尤其是針對 SQuAD 中的答案不是一個單詞而可能是一個短語的情況,多輪推理機制可以不斷縮小預測範圍,最終確定正確答案位置。
-
對問題敏感的問題表示方法[9],[14]能夠更好地 model 各型別問題,並根據問題型別聚焦於原文中的特定單詞,比如 when 類問題更加聚焦於原文中的時間資訊,而 where 類問題更關註空間資訊。
參考文獻
[1] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. In Proceedings of EMNLP.
[2] Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, , and Phil Blunsom. 2015. Teaching ma- chines to read and comprehend. In Proceedings of NIPS.
[3] Felix Hill, Antoine Bordes, Sumit Chopra, and Jason Weston. 2016. The goldilocks principle: Reading childrens books with explicit memory representa- tions. In Proceedings of ICLR.
[4] Shuohang Wang and Jing Jiang. 2017. Machine comprehension using match-lstm and answer pointer. In Proceedings of ICLR.
[5] Minjoon Seo, Aniruddha Kembhavi, Ali Farhadi, and Hananneh Hajishirzi. 2017. Bidirectional attention flow for machine comprehension. In Proceedings of ICLR.
[6] Caiming Xiong, Victor Zhong, and Richard Socher. 2017. Dynamic coattention networks for question answering. In Proceedings of ICLR.
[7] Zhiguo Wang, Haitao Mi, Wael Hamza, and Radu Florian. 2016. Multi-perspective context matching for machine comprehension. arXiv preprint arXiv:1612.04211 .
[8] Dirk Weissenborn, Georg Wiese, and Laura Seiffe. 2017. Fastqa: A simple and efficient neural architecture for question answering. arXiv preprint arXiv:1703.04816 .
[9] Junbei Zhang, Xiaodan Zhu, Qian Chen, Lirong Dai, Si Wei, and Hui Jiang. 2017. Exploring question understanding and adaptation in neural- network-based question answering. arXiv preprint arXiv:1703.04617 .
[10] Yichen Gong and Samuel R. Bowman. 2017. Ruminating reader: Reasoning with gated multi-hop attention. arXiv preprint arXiv:1704.07415 .
[11] Yelong Shen, Po-Sen Huang, Jianfeng Gao, and Weizhu Chen. 2016. Reasonet: Learning to stop reading in machine comprehension. arXiv preprint arXiv:1609.05284 .
[12] Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus. 2015. End-to-end memory networks. In Proceedings of NIPS.
[13] Microsoft Research Asia. 2017. R-NET: MACHINE READING COMPREHENSION WITH SELF-MATCHING NETWORKS. In Proceedings of ACL.
[14] Minghao Hu, Yuxing Peng, and Xipeng Qiu. 2017. Mnemonic Reader for Machine Comprehension. arXiv preprint arXiv:1705.02798 .
我是彩蛋
解鎖新姿勢:用微信刷論文!
PaperWeekly小程式上線啦
今日arXiv√猜你喜歡√熱門資源√
隨時緊跟最新最熱論文
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
長按識別二維碼,使用小程式
*點選閱讀原文即可註冊

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

