
在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @chenhong。本文提出了一種高效資料增強方式 SamplePairing,沒有任何公式,沒有任何框架,任何 CPU 都能處理。
如果你對本文工作感興趣,點選底部的閱讀原文即可檢視原論文。
關於作者:陳泰紅,小米高階演演算法工程師,研究方向為人臉檢測識別,手勢識別與跟蹤。
■ 論文 | Data Augmentation by Pairing Samples for Images Classification
■ 連結 | https://www.paperweekly.site/papers/1523
■ 作者 | chenhong
論文動機
這是 IBM 在 arXiv,2018 年 1 月 9 日新掛的一篇論文,主要研究資料增強。核心思想很簡單,小學生都會,求平均值。這是我見到 CNN 領域最簡單的一篇論文。
資料增強是機器學習任務中廣泛使用的技術,如影象處理領域,人工標註資料成本昂貴,而 CNN 的訓練有需要大量標註資料避免過擬合。圖像處理領域常用的資料增強技術有旋轉、扭曲、新增少量噪音、從原影象裁剪等。
本文提出了一種高效資料增強方式 SamplePairing:從訓練集隨機抽取的兩幅影象疊加合成一個新的樣本(畫素取平均值),可以使訓練集規模從 N 擴增到 N*N。沒有任何公式,沒有任何框架,簡單易懂簡潔明瞭,任何 CPU 都能處理。
論文在使用 GoogLeNet,在 ILSVRC 2012 資料集從 top-1 錯誤率從 33.5% 降低到 29%,在 CIFAR-10 資料集 top-1 錯誤率從 8.22% 降低到 6.93%。這對訓練集有限的任務而言,提高了模型的準確性。
模型介紹
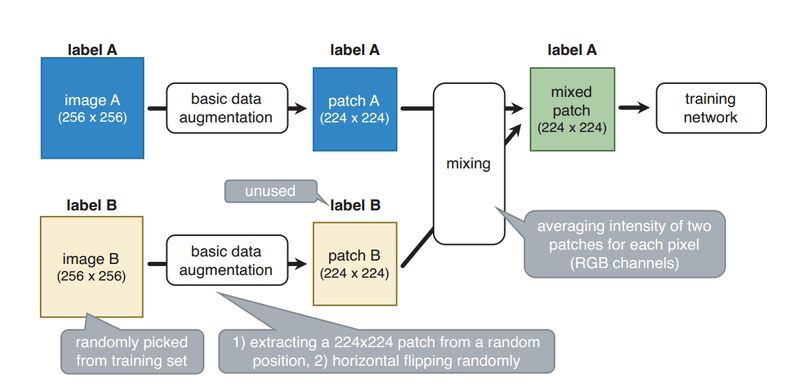
論文的模型結構 SamplePairing 如上圖所示。模型雖然很簡單,但是還得消化一下為什麼簡單有效。
先說一下實現過程。訓練影象 A 是隨機的,從訓練集隨機抓取影象 B,(A 和 B 都是 ILSVRC2012 的影象,解析度 256×256)兩者都經過基本的資料增強(隨機翻轉,萃取),解析度變為 224×224,對兩幅影象求平均值,但是 label採用的是 A,之後送入 GoogLeNet 模型。因此,SamplePairing 隨機從影象集中建立新的影象,而且 label B 未使用。
影象 A 和 B 在模型中的權重是一致的,即使使用大型網路,訓練誤差也不能變成 0,訓練精度平均不能超過 50%。對於 N 分類器,最大訓練精度是 0.5+1/(Nx2)。
儘管 SamplePairing 的訓練精度不會很高,當停止 SamplePairing 作為最終微調時的訓練,訓練精度和驗證精度很快改善。
經過微調模型,使用 SamplePairing 訓練的網路比未使用 SamplePairing 訓練的模型都高很多。論文認為使用 SamplePairing 是一種正則化。
在 mix 之前有其他資料增強方式,在 CPU 執行,而反向傳播的訓練過程在 GPU 執行,這樣 CPU 和 GPU 平行計算,沒有限制增加總的訓練時間。
論文的訓練過程如下:
1. 先不使用 SamplePairing 資料增強訓練,而是先使用傳統的資料增強訓練網路。
2. 完成一個 epoch(ILSVRC)或者 100 個 epoch(其他資料集),加入 SamplePairing 資料增強。
3. 間歇性禁止 SamplePairing。對於 ILSVRC 資料集,為 300,000 個影象啟用 SamplePairing,然後為下一個 100,000 個影象禁用它。對於其他資料集,啟用 8 個 epoch,在接下來的 2 個 epoch 禁止 SamplePairing。
4. 在訓練損失函式和精度穩定後,禁止 SamplePairing 作為微調。
實驗
論文的模型在多個資料集進行驗證:ILSVRC 2012,CIFAR-10,CIFAR-100,以及 Street View House Numbers (SVHN) datasets。
以 CIFAR-10 為例,validation 誤差一致在波浪形震蕩,800epoch 之後才趨於穩定,此時誤差才小於不使用 SamplePairing 的模型。
論文表 1 所示 training error 會增加,而 validation error 會減小,說明正則化效果明顯。在 CIFAR 訓練集減少樣本個數,訓練和驗證誤差相差不大。
文章評價
目前作者論文僅僅在 ILSVRC 2012 驗證分類的錯誤率,其他資料集比如標的檢測,語意分割是否有效?有研究能力的同志們趕緊往前沖,這又是一個坑。
論文給出一種資料增強方式,也用實驗驗證確實有效,但是為什麼有效?
個人認為相當於隨機引入噪聲,在訓練樣本中人為引入誤導性的訓練樣本。 如果不是 IBM 的論文,我估計也不會認真研究一番的。在論文滿天飛的年代,名企名校名人還是佔優勢的。
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

△ 戳我領取新年禮物
參與方式
1. 長按識別下方二維碼參與投票
2. 文末留言你喜歡某篇論文的原因
3. 分享本文到朋友圈並截圖發至後臺
截止時間
2018年1月24日0點0分
福利清單
PaperWeekly定製手機殼 x 3份
PaperWeekly定製筆記本 x 5份
PaperWeekly定製行李牌 x 10份

△ 我們長這樣哦~
長按掃描二維碼,參與投票!
▼

 # 高 能 提 醒 #
# 高 能 提 醒 #
1. 為了方便大家在投票過程中檢視論文詳情,請勿使用微信內建瀏覽器。點選頁面右上角的“…”按鈕,在手機瀏覽器中開啟表單。
2. 本次評選包含自然語言處理和計算機視覺兩大方向,請在你所選擇的參與方向下勾選3-10篇論文。
3. 獲獎名單將於1月25日公佈,其中5位由小編根據文末留言選取,其他13位採用隨機抽取,禮物隨機發放。
長按掃描二維碼,馬上投票!
▼
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視原論文