導讀:本文由分享演講整理而成。透過圍繞美圖業務和大家分享下美圖容器基礎平臺建設中的探索經驗以及在業務落地過程中的具體問題和相應的方案。美圖從2016 年開始了容器相關的探索到 2018 年業務基本實現容器化,期間遇見的一些坑,同時也產生了相應的解決方案,希望對大家有一定的借鑒意義。
章敏鵬,目前就職於美圖技術保障部架構平臺,主要從事容器基礎平臺建設,流媒體體系相關建設。負責容器平臺基礎元件建設、排程系統研發、多機房及混合雲建設、流媒體基礎服務建設及使用者體驗最佳化等。在容器化技術及流媒體方向有著多年的積累及豐富的實戰經驗。
一、美圖業務
今天主要會圍繞美圖的業務情況,聊一聊在容器基礎平臺建設探索過程中遇見的一些問題,以及具體如何落地的方案,希望可以給大家一些參考。
美圖公司成立於2008年10月,懷揣著“成為全球懂美的科技公司”的願景,創造了一系列軟硬體產品,如美圖秀秀、美顏相機、短影片社群美拍以及美圖拍照手機, 美圖產品的多樣化也催生了複雜多樣的服務端技術,億級MAU對服務端的技術要求也越加嚴苛。
2016 年我們開始調研容器化相關技術,2017年我們開始擁抱Kubernetes,2018年容器平臺基本落成並推進業務的整體容器化。我們期望透過容器化可以提升公司研發人員的線上支撐能力,提升持續開發和整合的能力,提升整體資源利用率和服務的可用性。
二、容器化建設
2.1 容器化之前
在業務容器化之前,我們業務是以物理機的方式部署到北京、寧波等多個IDC,部分服務部署到公有雲。其中大部分業務是單IDC部署,部分業務存在跨IDC間的呼叫,然後IDC之間透過專線打通。當時存在的幾個重要的問題:
1. 服務部署沒有進行隔離,業務混部需要控制得非常小心,資源的利用率非常低;
2. 業務型別較多,缺乏完全統一和完善的自動化運維手段,業務的增長會伴隨著維護人力的增加;
3. 測試環境與生產環境存在較大差異,這也導致一些生產環境問題不能在測試期間發現;
4. 開發人員線上意識較薄弱,線上故障率持續較高;
5. 面對機房級故障時業務遷移非常困難,出問題時只能尷尬地等機房恢復。
對此,我們希望透過積極的調整來解決掉存在的種種問題,而容器化是一個非常好的機會,可行性也比較高,同時我們希望藉著這個機會對我們的技術架構以及相關人員做一次從意識到技能的全面提升,為未來的技術演進鋪平部分道路。
2.2 選擇kubernetes
2017年容器編排的“戰爭”打完,Kubernetes取得領先並趨於成熟。我們也徹底投入到Kubernetes當中,容器系統的大規模落地離不開成熟的容器編排系統。kubernetes對容器的編排、資源的排程以及強大的擴充套件能力極大地方便了我們平臺的構建。
單體容器如集裝箱,它統一的標準方便了排程運輸。Kubernetes提供了對集裝進行集中排程的碼頭和輪渡,讓一切井然有序並且易於實施。容器基礎平臺則好比基於容器和kubernetes之上的完整的運輸系統,它需要集裝箱,碼頭輪渡,高速公路等整套體系,實際服務容器化的過程不是一個簡單的打包裝箱和排程規劃過程。大部分的服務與外界是有割不開聯絡的,需要保持與外界的聯通性,服務進駐容器更像是使用者住進集裝箱房子,她需要相應的基礎配套設施,像水,電,燃氣等等。所以我們首先是提供各種基礎設施,讓服務能進駐容器而不會水土不服。比如需要做好資源隔離,打通底層網路,做好負載均衡,處理好應用日誌等等。
2.3 容器平臺建設
首先我們對多地機房及雲端資源進行梳理,成為我們計算及儲存的資源池。同時我們構建起基礎的容器網路,日誌系統,儲存服務等底層基礎,然後依託Kubernetes完成了基於多租戶的容器管理平臺建設,提供完善的專案管理,服務編排,資源排程,負載均衡等能力。
我們提供同叢集多租戶的樣式,所以對叢集內的業務隔離,資源排程,彈性伸縮等都會有很高的要求。同時我們也存在多叢集混合雲的應用場景,因此存在著對跨叢集跨機房的容器網路互通,多叢集的負載均衡等的特定需求。
2.3.1 基礎建設之網路
先來看基礎建設中網路這一層。網路屬於底層建設,解決的問題非常關鍵,容器網路解決的問題主要包括:
1. Pod內部容器間的通訊;
2. Pod與Pod的通訊;
3. Pod 與Service的通訊;
4. Service與叢集外部的通訊;
5. 跨叢集跨網段通訊。
容器網路除了要解決上述的5個問題的同時也需要考慮如何將網路層的效能損失最小化。接下來先來看看在網路方案選擇上我們的一些考慮。
Kubernetes 透過CNI 提供了非常強的擴充套件能力,同時社群的活躍也讓網路外掛有了更多選擇的空間。CNI是CNCF旗下的一個專案,作為容器網路標準,由一組用於配置網路介面的規範和庫組成,同時還包含了一些外掛。CNI僅關心容器建立時的網路分配和當容器被刪除時釋放網路資源。CNI具有廣泛的支援,而且規範易於實現,社群支援非常豐富,網路可選方案也比較多。
網路方案的選型方面,我們會比較看重效能、穩定性、可維護性相關。在對Flannel、Opencontrail、Contiv、Weave、Calico、Romana等開源方案進行詳細的對比和分析之後,最終選擇了Calico方案。經過我們實際的壓測驗證,Calico的效能比較接近Host 的效能。從社群活躍度、方案成熟程度和穩定性方面考慮Calico也是較為良好,同時其基於BGP的方案也為我們後繼的網路擴充套件提供了可能性。
那麼在Calico方案裡面,Kubernetes建立Pod時的過程是怎樣的呢?Kubernetes 在建立Pod時,會先建立Sandbox的虛擬網路,然後Pod中的容器直接繼承Sandbox網路。在建立網路時,Kubelet 服務會透過標準的 CNI 介面呼叫Calico CNI 外掛,為容器建立一個 veth-pair 型別的網絡卡,並寫入路由表資訊。節點上的路由表透過 Calico Bird 元件以 BGP 的形式廣播到其他鄰居上,其他節點在收到路由條目後在進一步聚合路由寫入到自身節點上。
Calico在同子網內直接使用BGP、跨子網時使用IPIP。 而IPIP 因為其單佇列的設計存在著效能瓶頸,這嚴重限制了節點的吞吐能力,特別是作為LB時影響更為嚴重,所以我們需要規避IPIP的問題。另外因為我們多機房建設需要打通不同機房、不同叢集、不同網段的網路,所以我們需要進一步推進網路的最佳化。
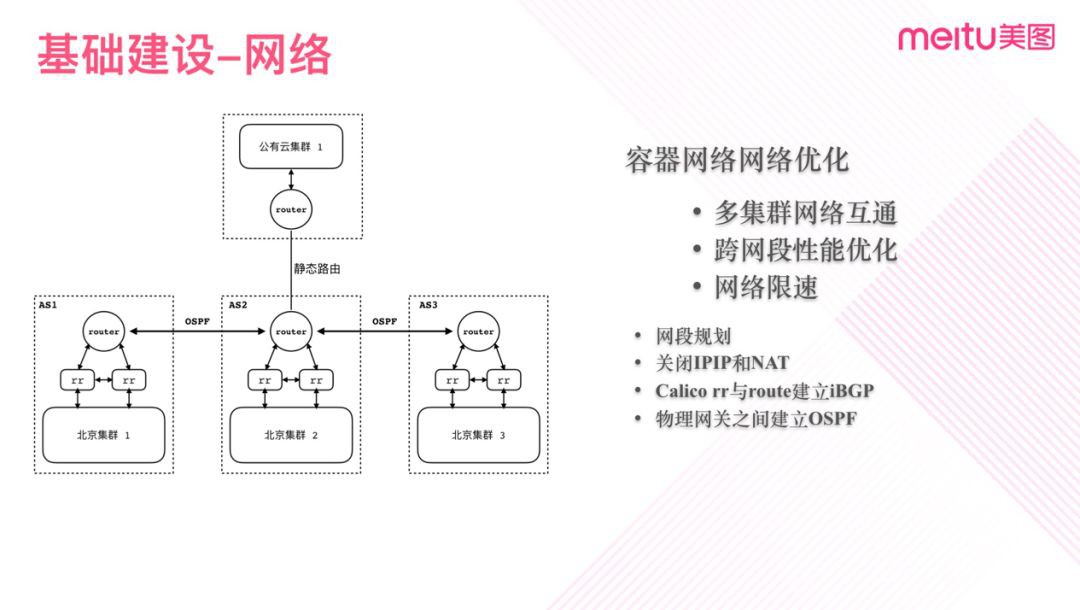
圖一
進一步的網路建設主要是三方面內容:
1. 多叢集的容器網路與物理網路打通;
2. 去掉IPIP,關閉NAT最佳化效能;
3. 增加限速,對節點網路進行保護;
圖一中是簡化後的一個網路拓撲圖,叢集的 Calico-RR(反射器) 與物理閘道器透過BGP進行打通,實現機房物理網路與容器網路拉平,解決了多叢集網路互通的問題,同時因為網路已拉到同一平面,也直接規避 IPIP 的效能問題。從上圖可以看出,每個機房作為一個 AS部署一個 Kubernetes叢集,機房內部冗餘有多個 RR(反射器),RR分別與機房內的閘道器建立 iBGP 連線,機房間的路由器透過 OSPF同步彼此之間的路由。
除了私有雲我們也需要解決混合雲的場景,實現叢集網路跨雲打通。受限於協議的支援,我們並沒有採用與私有雲一樣的打通方式。因為雲端網段相對固定,在規劃完成後變動較少,因此我們採用靜態路由的方式,機房閘道器上配置相應網段的靜態路由規則,同時在雲端路由上也配置上相應路由規則,最終打通路由路徑。
我們在實施的過程中遇到了不少細節上的問題,比如舊叢集單個叢集跨了三機房,在打通網路時存在環路的情況需要透過靜態路由來規避問題。在做網路限速時,外掛存在Bug並且社群沒有解決(目前最新版本已解決了)需要手動修複。不過問題一一解決後,網路基礎也完成了生產落地和打通。
2.3.2 基礎建設之LB
Kubernetes 在設計上其實是充分考慮了負載均衡和服務發現的,它提供了Service資源,並透過kube-proxy配合Cloud Provider來適應不同的應用場景。此外還有一些其它負載均衡機制,包括Service,Ingress Controller,Service Load Balancer,Custom Load Balancer。不過Kuernetes的設計有它實際適用的場景和侷限性,並不能完全滿足我們複雜場景落地,同時也考慮到社群方案成熟度問題,最終我們使用了自定義開發的Custom Load Balancer。
七層負載的選型上,我們是使用了較為成熟的Nginx Custom Controller的方案。我們也對Envoy等方案進行了仔細對比,但是考慮到我們公司對於Nginx有非常成熟的運維經驗,以及我們很多業務依賴於Nginx的一些第三方擴充套件的功能,所以從推動業務容器快速落地角度、維護穩定性角度,我們最終選擇了Nginx 作為早期的落地方案。不過在與kubernetes結合方面,Nginx還是存在著不少的細節問題,我們也一直在推動解決,同時我們也在考慮Envoy等後續的最佳化方案。
Custom Load Balancer由 Nginx、 Kubenernet Controller以及管理元件組成。Kubenernet Controller負責監聽 Kubernetes資源,並根據資源情況動態更新Nginx 配置。Nginx Upstream直接配置對應的Service Endpoints,並增加相應的存活檢測機制。因為在網路層面上物理網與容器網路已拉平,所以Nginx 與各叢集的 Service的Endpoint是完全鏈路可達的,因此也可直接支撐多叢集的負載均衡。
LB 提供了友好的UI介面,提高了釋出的效率、減少人為故障。 同時,LB也具備灰度升級,流量控制,故障降級等相關基礎功能,並且提供了豐富的指標,讓運維監控視覺化。
2.3.3 基礎建設之日誌
我們再來看一下另外一個比較重要的基礎設施——日誌。日誌其實是較為關鍵的基礎設施,它是審計,排障,監控報警等所必需的。日誌標準化一直是比較難推進的一件事情,特別是存在大量舊系統的情況下。一方面面臨業務程式碼的改造,另一方面面臨著開發及運維習慣的改造。 而容器化恰好是推進日誌標準化很好的一個機會。
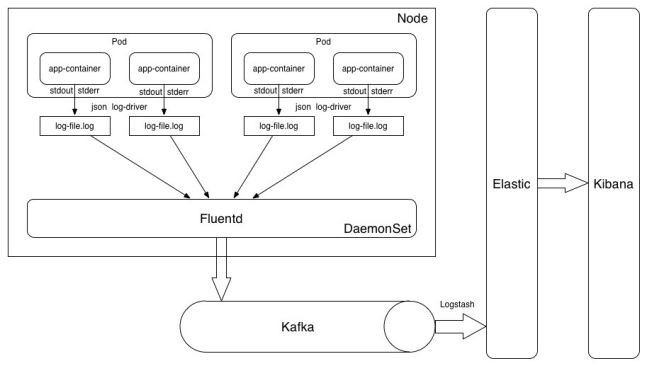
圖二
日誌架構上我們選用的是 Cluster-Level 的方式,使用Fluentd作為節點採集Agent。Docker 日誌驅動使用Json log-driver,業務容器日誌輸出到標準輸出,最終落盤到容器所屬的目錄中。Fluentd 採集Docker輸出日誌,並寫入Kafka佇列,Logstash 負責消費佇列資料併入 Elasticsearch, 同時由Kibana提供統一的日誌查詢介面。
在業務容器化落地的過程中,日誌也暴露了很多的問題。如:相容問題,標準輸出的日誌可能經過多層封裝導致日誌被截斷或者添加了額外內容,如PHP-FPM ,Nginx等。又比如日誌格式不統一,不同型別業務日誌格式各不相同,比較難完全統一。再比如業務日誌可靠性要求,有些允許極端情況下丟失,有些不允許丟失。
為了讓業務能更快速將舊業務遷移至容器平臺,我們為每種特性的業務型別做了定製化方案,輔助業務快速接入。比如對PHP,業務將日誌輸出至pipe 再由tail容器讀取pipe 資料輸至標準輸出。再如大資料業務,因為統計日誌與事件日誌是分割開的,一起輸到標準輸出會需要較大改造量,改造時間較長,所以對採集方式進行適配調整,業務直接輸出日誌到rootfs,並由宿主機agent直接採集rootfs約定目錄的日誌資料。
總之日誌因為與其它系統以及人員習慣耦合度太高,所以要完成標準化,完成系統解耦和人員依賴改變是比較消耗時間精力的一件事情。
2.3.4 基礎建設之彈性排程
再來看關於排程的一些建設。容器排程,其實是為瞭解決資源利用率最大化的問題,本質上是一個整數規劃問題。Kubernetes的排程策略源自Borg, 但是為了更好的適應新一代的容器應用,以及各種規模的部署,Kubernetes的排程策略相應做的更加靈活,也更加容易理解和使用。Kubernetes 對Pod的排程透過兩個階段來實現。Predicates階段用於過濾出符合基本要求的節點,Priorities階段用於得到最優節點。不過由於排程是根據分配量來進行而不是實際使用率,所以業務需要準確評估出自己的資源使用量,如果評估不準有可能會造成資源的浪費或者影響業務質量。
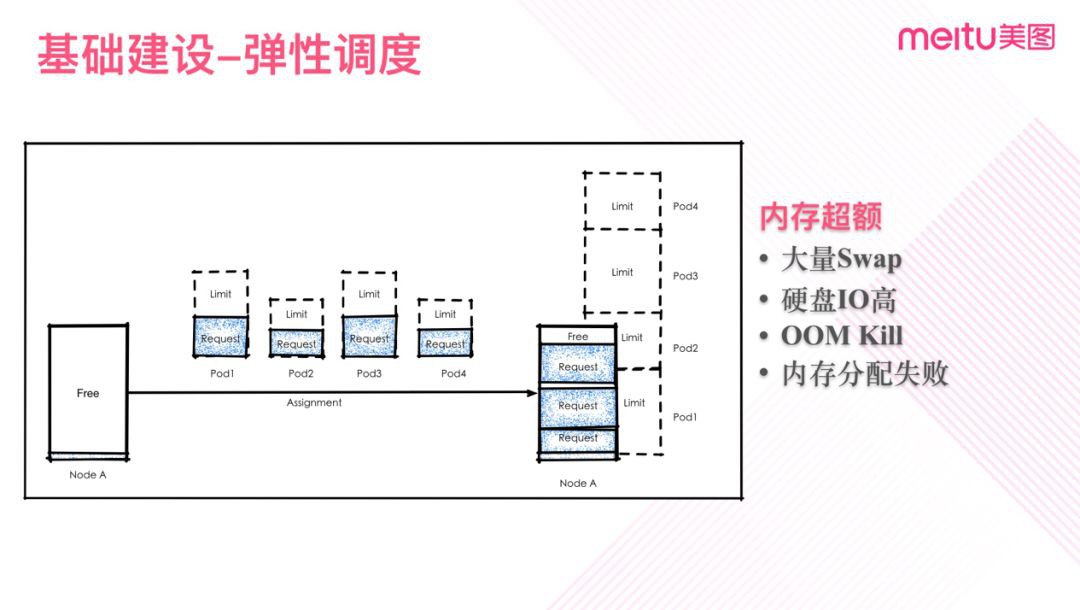
圖三
比如我們看圖三的實體,左邊為空閑伺服器,中間每個Pod 都申請了記憶體的 Request及Limit,排程器根據Request計算,伺服器能放得下這個幾個Pod,於是排程至了伺服器上面。
可以看到實際 Limit 是機器可用資源的兩倍。那麼假如這時Pod1 記憶體使用超過了Request,但是遠沒有達到Limit,這時伺服器有可能會出現Swap,而更進一步,機器資源不足後,有可能會出現OOM,記憶體最多且Request/Limit比值最小的那個Pod 中的行程將會被OOM Kill。而這種 Kill 將會造成業務的抖動。同時如果出現大量Swap也會使硬碟出現IO瓶頸,影響同機器上的其實業務。
在這樣的場景下,當前kubernetes的排程器實現會面臨一些問題,因為它是根據配額來排程的,而業務使用者不合理的配額需求導致了很多預期之外的場景,所以它無法簡單解決。
針對這種場景,我們總結出了以下幾個最佳化點:
1. 最佳化業務Request值,根據業務歷史資料調節Request;
2. 增加執行時指標,將節點當前利用率考慮進內;
3. 對於特殊質量保障的業務設定 Guaranteed 級別;
4. 規避Pod記憶體進行swap;
5. 完善IO及網路等資源的隔離機制。
實際上我們在業務的開發測試叢集中就遇到了資源緊張同時排程不均衡導致大量OOM的場景,並且一度影響到了業務的接入。本質這還是資源利用率過高時排程的不合理造成。後面經過最佳化改進才從這種困境中逃離。
再看另外一個場景,我們在將叢集分配率擠壓到高於50%以上時,很容易出現資源碎片。這時一些資源需求較大的Pod會出現無法排程的情況。在這種場景下則需要透過一些人工幹預來進行排程調整。針對這種場景,我們其實是需要透過一些策略調優來最佳化我們的排程,包括:Reschedule、 MostRequestedPriority、以及優先順序來最佳化叢集的排程。
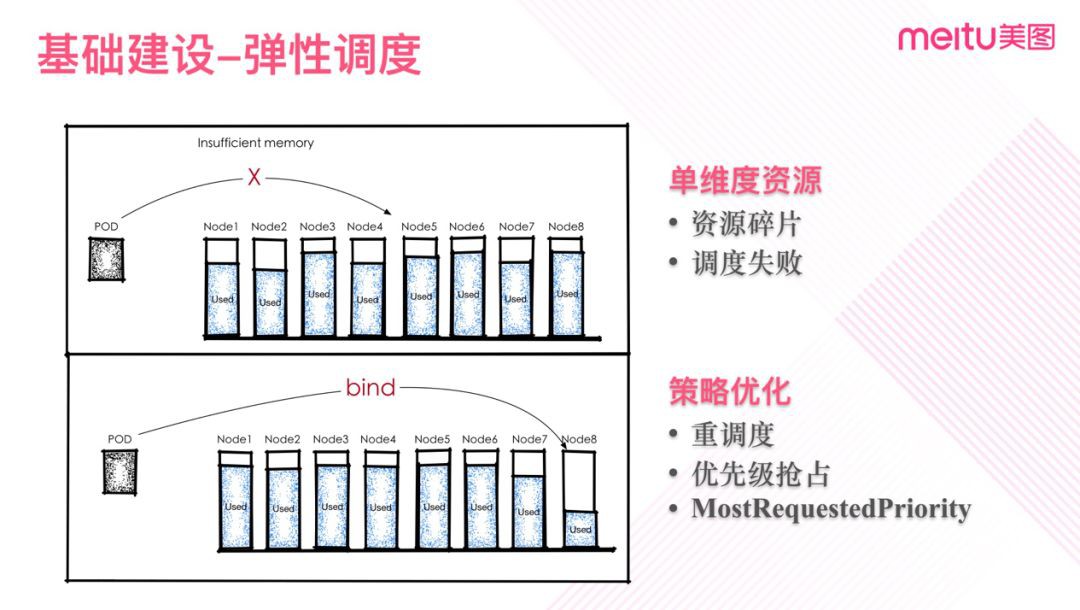
圖四
圖四是簡化後一個單資源的示例。實際應用中我們更希望叢集有足夠的冗餘度來做資源排程,同時在混合雲場景,我們更希望是儘量使用完部分節點再擴容新的節點。比如圖四所示,希望存在一些大塊的空白節點,儘量減少碎片空間。
不過提高器利用率,則會遇到上一場景提到的利用率過高時Pod資源不足的問題。所以必需首先解決好資源使用的預估及排程最佳化。而且也需要在利用率及冗餘度上做平衡,設定對相應的策略權重,透過一定水位限制確保節點仍有一定冗餘度,如 MostRequestedPriority 的水位限制。水位控制與我們希望的叢集利用率直接相關。
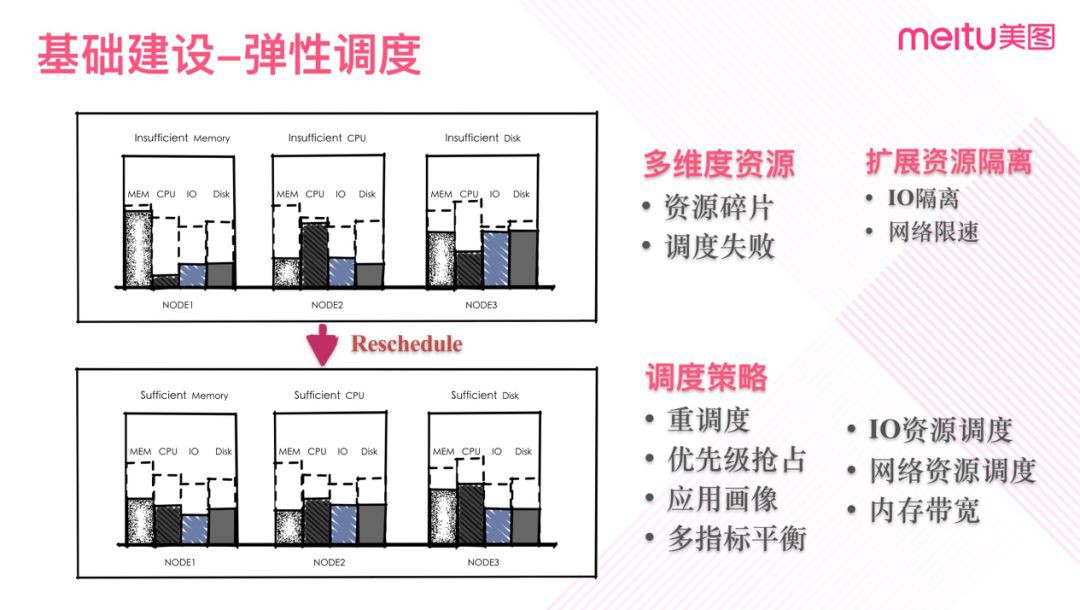
圖五
前面考慮很多時候是先從單個維度出發來考慮問題,實際場景中我們是多維度的。多維度下會複雜得多,並且碎片的情況更容易出現,在這種情況下很多時候得到的只是一個區域性最優排程而不是全域性最優。
有時候為了更接近全域性最優分配需要進行一定重排程。這需要我們自定義控制器做特定的排程策略,同時考慮到大量調動Pod可能會帶來的業務抖動,特別是對於部分優雅關閉沒有做很好的業務,所以需要較嚴謹的保護規則和時機控制。如只在機器資源較為緊張時對優先順序較低的服務進行調整。
在實際業務容器化過程中,業務對於資源的依賴複雜多樣,根據業務的實際需求,我們進一步引入了IO,網路,記憶體頻寬等一些資源需求的排程,我們在排程策略中也新增了對應的擴充套件資源。
2.3.5 基礎建設之彈性伸縮
排程解決了業務資源合理分配,彈性伸縮組(HPA)則是在提升資源利用率的同時對業務進行資源保障的重要手段。它保證在業務量級上來時能及時的進行擴容,在業務量級下降後又能及時回收資源,HPA 是根據特定的指標以及業務設定的標的值來增加或減少Pod的數量。這部分需要考慮三方面:
1. 伸縮指標的擴充套件;
2. 錯峰排程的實現;
3. 伸縮時的業務抖動的最佳化。
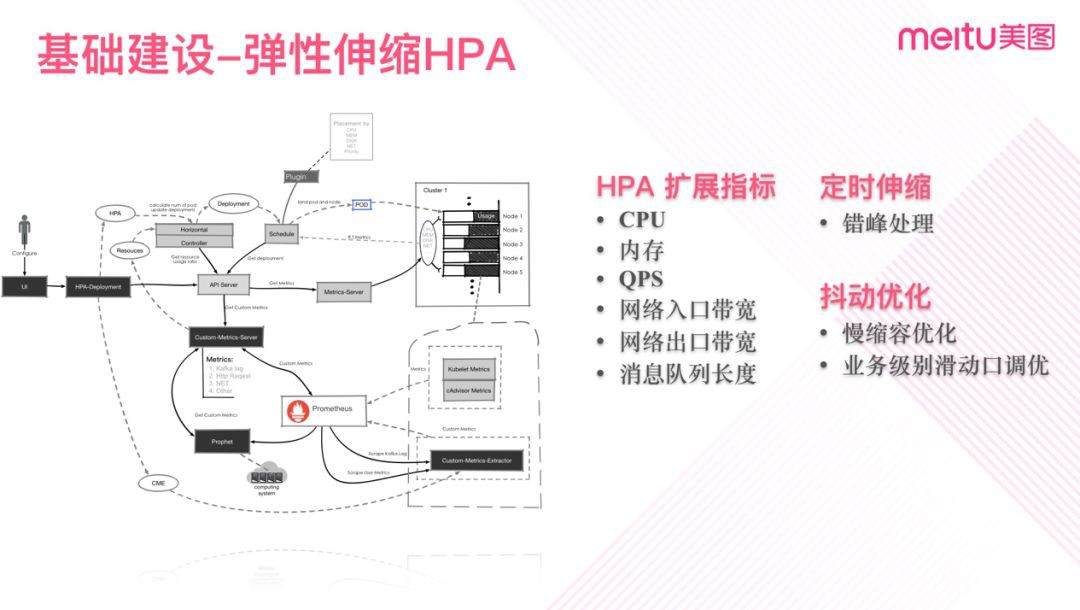
圖六
圖六左側是我們擴充套件指標的架構圖,從圖中我們可以看到,透過擴充套件採集模組及CME構建了擴充套件指標的採集面,透過預測器輸出預測指標,透過custom-metrics提供HPA所需要的擴充套件指標。
伸縮指標我們主要是擴展出了4個指標,包括QPS,網路入頻寬,網路出頻寬,訊息佇列積壓長度。錯峰排程則是透過定時策略實現。
我們這邊有一個雲處理的業務,會對於影片做H.265轉碼、編碼最佳化等CPU密集型操作,經常會有突峰的轉碼需求導致該業務需要大量的CPU資源。在這種情況下,HPA的擴縮容有時會跟不上節奏造成業務處理延時變長,主要是伸縮組演演算法在計算伸縮值時演演算法較為簡單,容易在業務量變小後馬上過量縮量,這就會導致業務量波動時反覆進行伸縮影響業務穩定,所以我們引入了慢縮容機制同時增加收縮滑動視窗以達到消峰的作用。
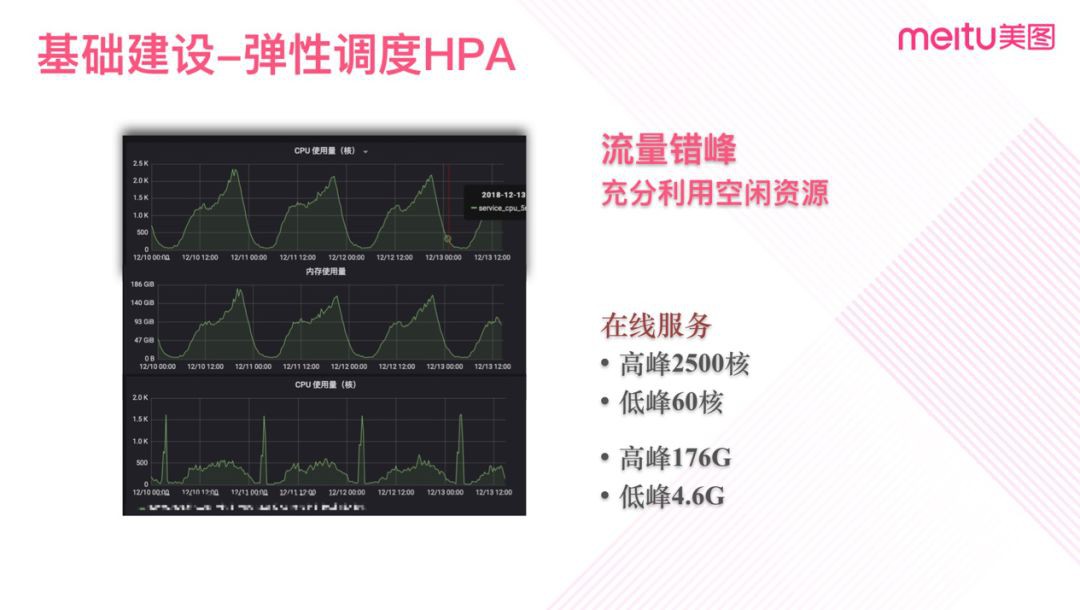
圖七
圖七是一個錯峰排程的案例。我們某個處理服務,白天需要大量資源佔用,高峰時需要2500核心,而低峰期間所需求的資源則非常少,最小時僅需要60核。而另外一個服務的一些離線計算任務沒有太強時間急迫性要求,可以放在夜間處理,還有一些統計類定時任務也是可以放置在夜間,這樣整體叢集資源可以被充分利用。
2.3.6 基礎建設之監控
監控是我們生產穩定的一個重要的保障手段。在容器化之前,我們運維體系其實已經有一套成熟的監控機制,容器化之後相應的監控並不需要完全推倒重做,部分體系可以復用比如物理機監控,在這之上引入新的容器監控系統。 容器平臺主要監控是幾方面的內容。
1. 物理機基礎監控,主要是像硬碟,IO,記憶體,網路等;
2. 業務指標監控,包括異常監控以及效能監控;
3. 容器行為的監控,監控Pod資源,容器事情等;
4. 容器元件的監控。
實際上監控指標是持續在豐富及最佳化的過程,我們最初只監控了主要的四方面的指標,而最終進行彙總分析時則是從叢集,服務,Pod,業務等等視角進行多維度的彙總分析輸出。
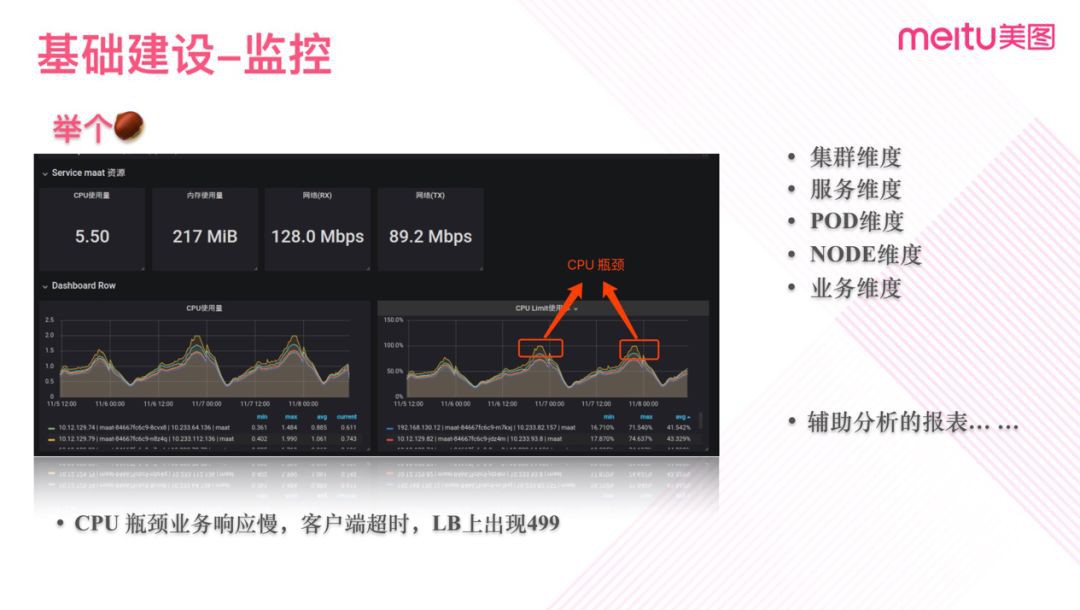
圖八
監控報表對於我們問題分析及排障會提供巨大的便利。圖八是一個CPU監控圖,圖中可以看出有兩個高峰期Pod的CPU是跑滿了。實際對應到的正是線上的某一次業務異常,當時業務的SLA在流量高峰時部分處理延時較高並導致報警。
基礎平臺的建設涉及到的還有很多內容,比如多叢集的管理、多租戶管理、DNS的最佳化,映象服務的最佳化,混合雲落地等等,限於篇幅不一一展開。
三、業務落地
前面講了比較多是基礎平臺構建的一些內容,下麵我們聊一下業務接入的一些事情。我們知道容器化給業務帶來的收益是非常多的,但是我們也是需要考慮可能會給業務帶來的困難。
考慮各種遷移和改造的問題,我們需要將平臺更進一步最佳化,讓業務接入成本儘量低。提供更簡單方便的CI/CD流程,我們需要提供友好的統一的操作介面,提供完整的接入指導,快速排障工具,定期的培訓等。
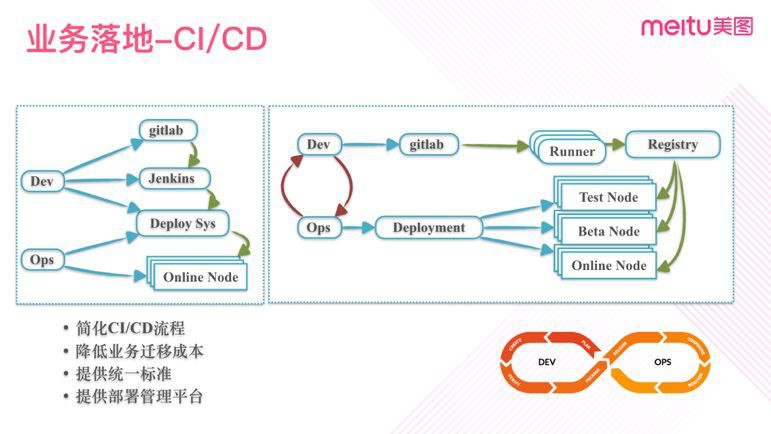
圖九
比如我們最佳化CI/CD流程,整個構建和釋出過程對開發儘量透明,圖九右邊是新的流程,開發提交完程式碼之後,Gitlab-CI會自動促發測試及構建過程,並將映象推送到倉庫。開發同學僅需要在統一門戶網上面操作對應的版本進行釋出,平臺會自動生成Deployment併發布至相應的叢集。
再比如,我們提供一個友好的管理平臺,它可以減少業務學習成本以及出錯的機率。同時也提供了靈活的軟體階段定製支援。可以使用簡單的方式定製多個階段,包括:Dev、Test、Pre、 Beta、Canary、Realse … …
綜上,其實我們僅基礎平臺建設是遠不夠,實際業務接入過程中需要考慮很多其它因素。同時業務的需求也不斷地最佳化我們的平臺架構,最終實現整體的落地。實際上我們做的也確實還遠遠不夠,業務在接入過程還是需要面臨著眾多的問題,所以我們需要在各方面都進一步完善,業務其實一直在教導我們如何做好一個平臺,我們也在不斷地學習吸收。這也是我們不斷提升的源動力之一。
四、展望未來
未來我們將長期執行多叢集混合雲的架構,會逐步引入多家公有雲,最佳化排程系統,更進一步提高我們的資源利用率,同時也會保持著對ServiceMesh、Serverless、邊緣計算等方向的關註,會結合著業務的需求,更進一步最佳化容器基礎平臺。

