

摘要(Abstract)
The security of computer systems fundamentally relies on memory isolation,e.g., kernel address ranges are marked as non-accessible and are protected fromuser access. In this paper, we present Meltdown. Meltdown exploits side effectsof out-of-order execution on modern processors to read arbitrary kernel-memorylocations including personal data and passwords. Out-of-order execution is anindispensable performance feature and present in a wide range of modernprocessors. The attack is independent of the operating system, and it does not relyon any software vulnerabilities. Meltdown breaks all security assumptions givenby address space isolation as well as paravirtualized environments and, thus, everysecurity mechanism building upon this foundation. On affected systems, Meltdownenables an adversary to read memory of other processes or virtual machines in thecloud without any permissions or privileges, affecting millions of customersand virtually every user of a personal computer. We show that the KAISERdefense mechanism for KASLR [8] has the important (but inadvertent) side effectof impeding Meltdown. We stress that KAISER must be deployed immediately toprevent large-scale exploitation of this severe information leakage.
記憶體隔離是計算機系統安全的基礎,例如:核心空間的地址段往往是標記為受保護的,使用者態程式讀寫核心地址則會觸發異常,從而阻止其訪問。在這篇文章中,我們會詳細描述這個叫Meltdown的硬體漏洞。Meltdown是利用了現代處理器上亂序執行(out-of-order execution)的副作用(side effect),使得使用者態程式也可以讀出核心空間的資料,包括個人私有資料和密碼。由於可以提高效能,現代處理器廣泛採用了亂序執行特性。利用Meltdown進行攻擊的方法和作業系統無關,也不依賴於軟體的漏洞。地址空間隔離帶來的安全保證被Meltdown給無情的打碎了(半虛擬化環境也是如此),因此,所有基於地址空間隔離的安全機制都不再安全了。在受影響的系統中,Meltdown可以讓一個攻擊者讀取其他行程的資料,或者讀取雲伺服器中其他虛擬機器的資料,而不需要相應的許可權。這份檔案也說明瞭KAISER(本意是解決KASLR不能解決的問題)可以防止Meltdown攻擊。因此,我們強烈建議必須立即部署KAISER,以防止大規模、嚴重的資訊洩漏。
一、簡介(Introduction)
One of the central security features of today’s operating systems ismemory isolation. Operating systems ensure that user applications cannot accesseach other’s memories and prevent user applications from reading or writing kernelmemory. This isolation is a cornerstone of our computing environments andallows running multiple applications on personal devices or executing processesof multiple users on a single machine in the cloud.
當今作業系統的核心安全特性之一是記憶體隔離。所謂記憶體隔離就是作業系統要確保使用者應用程式不能訪問彼此的記憶體,此外,它也要阻止使用者應用程式對核心空間的訪問。在個人裝置上,多個行程並行執行,我們需要隔離彼此。在雲端計算環境中,共享同一臺物理主機的多個使用者(虛擬機器)的多個行程也是共存的,我們也不能讓某個使用者(虛擬機器)的行程能夠訪問到其他使用者(虛擬機器)的行程資料。因此,這種核心隔離是我們計算環境的基石。
On modern processors, the isolation between the kernel and user processesis typically realized by a supervisor bit of the processor that defines whethera memory page of the kernel can be accessed or not. The basic idea is that thisbit can only be set when entering kernel code and it is cleared when switchingto user processes. This hardware feature allows operating systems to map thekernel into the address space of every process and to have very efficienttransitions from the user process to the kernel, e.g., for interrupt handling.Consequently, in practice, there is no change of the memory mapping whenswitching from a user process to the kernel.
在現代處理器上,內核和使用者地址空間的隔離通常由處理器控制暫存器中的一個bit實現(該bit被稱為supervisor bit,標識當前處理器處於的樣式),該bit定義了是否可以訪問kernel space的記憶體頁。基本的思路是:當執行核心程式碼的時候才設定此位等於1,在切換到使用者行程時清除該bit。有了這種硬體特性的支援,作業系統可以將核心地址空間對映到每個行程。在使用者行程執行過程中,往往需要從使用者空間切換到核心空間,例如使用者行程透過系統呼叫請求核心空間的服務,或者當在使用者空間發生中斷的時候,需要切換到核心空間執行interrupt handler,以便來處理外設的非同步事件。考慮到從使用者態切換核心態的頻率非常高,如果在這個過程中地址空間不需要切換,那麼系統效能就不會受到影響。
In this work, we present Meltdown1. Meltdown is a novel attack that allows overcomingmemory isolation completely by providing a simple way for any user process toread the entire kernel memory of the machine it executes on, including allphysical memory mapped in the kernel region. Meltdown does not exploit anysoftware vulnerability, i.e., it works on all major operating systems. Instead,Meltdown exploits side-channel information available on most modern processors,e.g., modern Intel microarchitectures since 2010 and potentially on other CPUsof other vendors.
While side-channel attacks typically require very specific knowledge aboutthe target application and are tailored to only leak information about itssecrets, Meltdown allows an adversary who can run code on the vulnerable processorto obtain a dump of the entire kernel address space, including any mappedphysical memory. The root cause of the simplicity and strength of Meltdown areside effects caused by out-of-order execution.
在這項工作中,我們提出了利用meltdown漏洞進行攻擊的一種全新的方法,透過這種方法,任何使用者行程都可以攻破作業系統對地址空間的隔離,透過一種簡單的方法讀取核心空間的資料,這裡就包括對映到核心地址空間的所有的物理記憶體。Meltdown並不利用任何的軟體的漏洞,也就是說它對任何一種作業系統都是有效的。相反,它是利用大多數現代處理器(例如2010年以後的Intel微架構(microarchitectural),其他CPU廠商也可能潛伏這樣的問題)上的側通道(side-channel)資訊來發起攻擊。一般的側通道攻擊(side-channel attack)都需要直到攻擊標的的詳細資訊,然後根據這些資訊指定具體的攻擊方法,從而獲取秘密資料。Meltdown攻擊方法則不然,它可以dump整個核心地址空間的資料(包括全部對映到核心地址空間的物理記憶體)。Meltdown攻擊力度非常很大,其根本原因是利用了亂序執行的副作用(side effect)。
Out-of-order execution is an important performance feature of today’sprocessors in order to overcome latencies of busy execution units, e.g., amemory fetch unit needs to wait for data arrival from memory. Instead of stallingthe execution, modern processors run operations out-of-order i.e., they look ahead and schedulesubsequent operations to idle execution units of the processor. However, suchoperations often have unwanted side-effects, e.g., timing differences [28, 35,11] can leak information from both sequential and out-of-order execution.
有時候CPU執行單元在執行的時候會需要等待操作結果,例如載入記憶體資料到暫存器這樣的操作。為了提高效能,CPU並不是進入stall狀態,而是採用了亂序執行的方法,繼續處理後續指令並排程該指令去空閑的執行單元去執行。然而,這種操作常常有不必要的副作用,而透過這些執行指令時候的副作用,例如時序方面的差異[ 28, 35, 11 ],我們可以竊取到相關的資訊。
From a security perspective, one observation is particularly significant:Out-of-order; vulnerable CPUs allow an unprivileged process to load data from aprivileged (kernel or physical) address into a temporary CPU register. Moreover,the CPU even performs further computations based on this register value, e.g.,access to an array based on the register value. The processor ensures correctprogram execution, by simply discarding the results of the memory lookups(e.g., the modified register states), if it turns out that an instructionshould not have been executed. Hence, on the architectural level (e.g., the abstractdefinition of how the processor should perform computations), no securityproblem arises.
雖然效能提升了,但是從安全的角度來看卻存在問題,關鍵點在於:在亂序執行下,被攻擊的CPU可以執行未授權的行程從一個需要特權訪問的地址上讀出資料並載入到一個臨時的暫存器中。CPU甚至可以基於該臨時暫存器的值執行進一步的計算,例如,基於該暫存器的值來訪問陣列。當然,CPU最終還是會發現這個異常的地址訪問,並丟棄了計算的結果(例如將已經修改的暫存器值)。雖然那些異常之後的指令被提前執行了,但是最終CPU還是力輓狂瀾,清除了執行結果,因此看起來似乎什麼也沒有發生過。這也保證了從CPU體系結構角度來看,不存在任何的安全問題。
However, we observed that out-of-order memory lookups influence the cache,which in turn can be detected through the cache side channel. As a result, an attackercan dump the entire kernel memory by reading privileged memory in anout-of-order execution stream, and transmit the data from this elusive statevia a microarchitectural covert channel (e.g., Flush+Reload) to the outsideworld. On the receiving end of the covert channel, the register value isreconstructed. Hence, on the microarchitectural level (e.g., the actualhardware implementation), there is an exploitable security problem.
然而,我們可以觀察亂序執行對cache的影響,從而根據這些cache提供的側通道資訊來發起攻擊。具體的攻擊是這樣的:攻擊者利用CPU的亂序執行的特性來讀取需要特權訪問的記憶體地址並載入到臨時暫存器,程式會利用儲存在該暫存器的資料來影響cache的狀態。然後攻擊者搭建隱蔽通道(例如,Flush+Reload)把資料傳遞出來,在隱蔽通道的接收端,重建暫存器值。因此,在CPU微架構(和實際的CPU硬體實現相關)層面上看的確是存在安全問題。
Meltdown breaks all security assumptions given by the CPU’s memoryisolation capabilities. We evaluated the attack on modern desktop machines andlaptops, as well as servers in the cloud. Meltdown allows an unprivileged processto read data mapped in the kernel address space, including the entire physicalmemory on Linux and OS X, and a large fraction of the physical memory onWindows. This may include physical memory of other processes, the kernel, andin case of kernel-sharing sandbox solutions (e.g., Docker, LXC) or Xen inparavirtualization mode, memory of the kernel (or hypervisor), and otherco-located instances. While the performance heavily depends on the specificmachine, e.g., processor speed, TLB and cache sizes, and DRAM speed, we can dumpkernel and physical memory with up to 503KB/s. Hence, an enormous number of systems are affected.
CPU苦心經營的核心隔離能力被Meltdown輕而易舉的擊破了。我們對現代臺式機、膝上型電腦以及雲伺服器進行了攻擊,併發現在Linux和OS X這樣的系統中,meltdown可以讓使用者行程dump所有的物理記憶體(由於全部物理記憶體被對映到了核心地址空間)。而在Window系統中,meltdown可以讓使用者行程dump大部分的物理記憶體。這些物理記憶體可能包括其他行程的資料或者內核的資料。在共享內核的沙箱(sandbox)解決方案(例如Docker,LXC)或者半虛擬化樣式的Xen中,dump的物理記憶體資料也包括了核心(即hypervisor)以及其他的guest OS的資料。根據系統的不同(例如處理器速度、TLB和高速快取的大小,和DRAM的速度),dump記憶體的速度可以高達503kB/S。因此,Meltdown的影響是非常廣泛的。
The countermeasure KAISER [8], originally developed to preventside-channel attacks targeting KASLR, inadvertently protects against Meltdownas well. Our evaluation shows that KAISER prevents Meltdown to a large extent.Consequently, we stress that it is of utmost importance to deploy KAISER on alloperating systems immediately. Fortunately, during a responsible disclosurewindow, the three major operating systems (Windows, Linux, and OS X)implemented variants of KAISER and will roll out these patches in the nearfuture.
我們提出的對策是KAISER[8 ],KAISER最初是為了防止針對KASLR的側通道攻擊,不過無意中也意外的解決了Meltdown漏洞。我們的評估表明,KAISER在很大程度上防止了Meltdown,因此,我們強烈建議在所有作業系統上立即部署KAISER。幸運的是,三大作業系統(Windows、Linux和OS X)都已經實現了KAISER變種,並會在不久的將來推出這些補丁。
Meltdown is distinct from the Spectre Attacks [19] in several ways,notably that Spectre requires tailoring to the victim process’s softwareenvironment, but applies more broadly to CPUs and is not mitigated by KAISER.
熔斷(Meltdown)與幽靈(Spectre)攻擊[19]有幾點不同,最明顯的不同是發起幽靈攻擊需要瞭解受害者行程的軟體環境並針對這些資訊修改具體的攻擊方法。不過在更多的CPU上存在Spectre漏洞,而且KAISER對Spectre無效。
Contributions. The contributions of this work are:
1. We describe out-of-order execution as a new, extremely powerful,software-based side channel.
2. We show how out-of-order execution can be combined with amicroarchitectural covert channel to
transfer the data from an elusive state to a receiver on the outside.
3. We present an end-to-end attack combining out-oforder execution withexception handlers or TSX, to read arbitrary physical memory without anypermissions or privileges, on laptops, desktop machines,
and on public cloud machines.
4. We evaluate the performance of Meltdown and the effects of KAISER onit.
這項工作的貢獻包括:
1、我們首次發現可以透過亂序執行這個側通道發起攻擊,攻擊力度非常強大
2、我們展示瞭如何透過亂序執行和處理器微架構的隱蔽通道來傳輸資料,洩露資訊。
3、我們展示了一種利用亂序執行(結合異常處理或者TSX)的端到端的攻擊方法。透過這種方法,我們可以在沒有任何許可權的情況下讀取了膝上型電腦,臺式機和雲伺服器上的任意物理記憶體。
4、我們評估了Meltdown的效能以及KAISER對它的影響
Outline. The remainder ofthis paper is structured as follows: In Section 2, we describe the fundamentalproblem which is introduced with out-of-order execution. In Section 3, weprovide a toy example illustrating the side channel Meltdown exploits. InSection 4, we describe the building blocks of the full Meltdown attack. InSection 5, we present the Meltdown attack. In Section 6, we evaluate theperformance of the Meltdown attack on several different systems. In Section 7,we discuss the effects of the software-based KAISER countermeasure and proposesolutions in hardware. In Section 8, we discuss related work and conclude ourwork in Section 9.
本文概述:本文的其餘部分的結構如下:在第2節中,我們描述了亂序執行帶來的基本問題,在第3節中,我們提供了一個簡單的示例來說明Meltdown利用的側通道。在第4節中,我們描述了Meltdown攻擊的方塊結構圖。在第5節中,我們展示如何進行Meltdown攻擊。在第6節中,我們評估了幾種不同系統上的meltdown攻擊的效能。在第7節中,我們討論了針對meltdown的軟硬體對策。軟體解決方案主要是KAISER機制,此外,我們也提出了硬體解決方案的建議。在第8節中,我們將討論相關工作,併在第9節給出我們的結論。
二、背景介紹(Background)
In this section, we provide background on out-of-order execution, addresstranslation, and cache attacks.
這一小節,我們將描述亂序執行、地址翻譯和快取攻擊的一些基本背景知識。
1、亂序執行(Out-of-order execution)
Out-of-order execution is an optimization technique that allows tomaximize the utilization of all execution units of a CPU core as exhaustive aspossible. Instead of processing instructions strictly in the sequential programorder, the CPU executes them as soon as all required resources are available.While the execution unit of the current operation is occupied, other executionunits can run ahead. Hence, instructions can be run in parallel as long astheir results follow the architectural definition.
亂序執行是一種最佳化技術,透過該技術可以盡最大可能的利用CPU core中的執行單元。和順序執行的CPU不同,支援亂序執行的CPU可以不按照program order來執行程式碼,只要指令執行的資源是OK的(沒有被佔用),那麼就進入執行單元執行。如果當前指令涉及的執行單元被佔用了,那麼其他指令可以提前執行(如果該指令涉及的執行單元是空閑的話)。因此,在亂序執行下,只要結果符合體系結構定義,指令可以並行執行。
In practice, CPUs supporting out-of-order execution support runningoperations speculativelyto the extent thatthe processor’s out-of-order logic processes instructions before the CPU iscertain whether the instruction will be needed and committed. In this paper, werefer to speculative execution in a more restricted meaning, where it refers toan instruction sequence following a branch, and use the term out-of-orderexecution to refer to any way of getting an operation executed before the processorhas committed the results of all prior instructions.
在實際中,CPU的亂序執行和推測執行(speculative execution)捆綁在一起的。在CPU無法確定下一條指令是否一定需要執行的時候往往會進行預測,並根據預測的結果來完成亂序執行。在本文中,speculative execution被認為是一個受限的概念,它特指跳轉指令之後的指令序列的執行。而亂序執行這個術語是指處理器在提交所有前面指令操作結果之前,就已經提前執行了當前指令。
In 1967, Tomasulo [33] developed an algorithm [33] that enabled dynamicscheduling of instructions to allow out-of-order execution. Tomasulo [33]introduced a unified reservation station that allows a CPU to use a data valueas it has been computed instead of storing it to a register and re-reading it.The reservation station renames registers to allow instructions that operate onthe same physical registers to use the last logical one to solveread-after-write (RAW), write-after-read (WAR) and write-after-write (WAW)hazards. Furthermore, the reservation unit connects all execution units via acommon data bus (CDB). If an operand is not available, the reservation unit canlisten on the CDB until it is available and then directly begin the executionof the instruction.
1967,Tomasulo設計了一種演演算法[ 33 ] [ 33 ],實現了指令的動態排程,從而允許了亂序執行。Tomasulo [ 33 ]為CPU執行單元設計了統一的保留站(reservation station)。在過去,CPU執行單元需要從暫存器中讀出運算元或者把結果寫入暫存器,現在,有了保留站,CPU的執行單元可以使用它來讀取運算元並且儲存操作結果。我們給出一個具體的RAW(read-after-write)的例子:
R2
R4
第一條指令是計算R1+R3並把結果儲存到R2,第二條指令依賴於R2的值進行計算。在沒有保留站的時候,第一條指令的操作結果提交到R2暫存器之後,第二條指令才可以執行,因為需要從R2暫存器中載入運算元。如果有了保留站,那麼我們可以在保留站中重新命名暫存器R2,我們稱這個暫存器是R2.rename。這時候,第一條指令執行之後就把結果儲存在R2.rename暫存器中,而不需要把最終結果提交到R2暫存器中,這樣第二條指令就可以直接從R2.rename暫存器中獲取運算元並執行,從而解決了RAW帶來的hazard。WAR和WAW類似,不再贅述。(註:上面這一句的翻譯我自己做了一些擴充套件,方便理解保留站)。此外,保留站和所有的執行單元透過一個統一的CDB(common data bus)相連。如果運算元尚未準備好,那麼執行單元可以監聽CDB,一旦獲取到運算元,該執行單元會立刻開始指令的執行。

On the Intel architecture, the pipeline consists of the front-end, theexecution engine (back-end) and the memory subsystem [14]. x86 instructions arefetched by the front-end from the memory and decoded to microoperations (μOPs) which are continuously sent tothe execution engine. Out-of-order execution is implemented within theexecution engine as illustrated in Figure 1. The Reorder Buffer is responsible for registerallocation, register renaming and retiring. Additionally, other optimizations likemove elimination or the recognition of zeroing idioms are directly handled bythe reorder buffer. The μOPs are forwarded to the Unified Reservation Station that queues the operations on exitports that are connected to Execution Units. Each execution unit can perform different tasks likeALU operations, AES operations, address generation units (AGU) or memory loads andstores. AGUs as well as load and store execution units are directly connectedto the memory subsystem to process its requests.
在英特爾CPU體系結構中,流水線是由前端、執行引擎(後端)和記憶體子系統組成[14]。前端模組將x86指令從儲存器中讀取出來並解碼成微操作(μOPS,microoperations),uOPS隨後被髮送給執行引擎。在執行引擎中實現了亂序執行,如上圖所示。重新排序緩衝區(ReorderBuffer)負責暫存器分配、暫存器重新命名和將結果提交到軟體可見的暫存器(這個過程也稱為retirement)。此外,reorder buffer還有一些其他的功能,例如move elimination 、識別zeroing idioms等。uOPS被髮送到統一保留站中,併在該保留站的輸出埠上進行排隊,而保留站的輸出埠則直接連線到執行單元。每個執行單元可以執行不同的任務,如ALU運算,AES操作,地址生成單元(AGU)、memory load和memory store。AGU、memory load和memory store這三個執行單元會直接連線到儲存子系統中以便處理記憶體請求。
Since CPUs usually do not run linear instruction streams, they have branchprediction units that are used to obtain an educated guess of which instructionwill be executed next. Branch predictors try to determine which direction of abranch will be taken before its condition is actually evaluated. Instructionsthat lie on that path and do not have any dependencies can be executed inadvance and their results immediately used if the prediction was correct. Ifthe prediction was incorrect, the reorder buffer allows to rollback by clearingthe reorder buffer and re-initializing the unified reservation station.
由於CPU並非總是執行線性指令流,所以它有分支預測單元。該單元可以記錄過去程式跳轉的結果並用它來推測下一條可能被執行的指令。分支預測單元會在實際條件被檢查之前確定程式跳轉路徑。如果位於該路徑上的指令沒有任何依賴關係,那麼這些指令可以提前執行。如果預測正確,指令執行的結果可以立即使用。如果預測不正確,reorder buffer可以回滾操作結果,而具體的回滾是透過清除重新排序緩衝區和初始化統一保留站來完成的。
Various approaches to predict the branch exist: With static branchprediction [12], the outcome of the branch is solely based on the instructionitself. Dynamic branch prediction [2] gathers statistics at run-time to predictthe outcome. One-level branch prediction uses a 1-bit or 2-bit counter torecord the last outcome of the branch [21]. Modern processors often usetwo-level adaptive predictors [36] that remember the history of the last n outcomes allow to predict regularlyrecurring patterns. More recently, ideas to use neural branch prediction [34,18, 32] have been picked up and integrated into CPU architectures [3].
分支預測有各種各樣的方法:使用靜態分支預測[ 12 ]的時候,程式跳轉的結果完全基於指令本身。動態分支預測[ 2 ]則是在執行時收集統計資料來預測結果。一級分支預測使用1位或2位計數器來記錄跳轉結果[ 21 ]。現代處理器通常使用兩級自適應預測器[36],這種方法會記住最後n個歷史跳轉結果,並透過這些歷史跳轉記過來尋找有規律的跳轉樣式。最近,使用神經分支預測[ 34, 18, 32 ]的想法被重新拾起並整合到CPU體系結構中[ 3]。
2、地址空間(address space)
To isolate processesfrom each other, CPUs support virtual address spaces where virtual addressesare translated to physical addresses. A virtual address space is divided into aset of pages that can be individually mapped to physical memory through amulti-level page translation table. The translation tables define the actualvirtual to physical mapping and also protection properties that are used toenforce privilege checks, such as readable, writable, executable anduser-accessible. The currently used translation table that is held in a specialCPU register. On each context switch, the operating system updates thisregister with the next process’ translation table address in order to implementper process virtual address spaces. Because of that, each process can onlyreference data that belongs to its own virtual address space. Each virtualaddress space itself is split into a user and a kernel part. While the useraddress space can be accessed by the running application, the kernel addressspace can only be accessed if the CPU is running in privileged mode. This isenforced by the operating system disabling the user accessible property of thecorresponding translation tables. The kernel address space does not only havememory mapped for the kernel’s own usage, but it also needs to performoperations on user pages, e.g., filling them with data. Consequently, theentire physical memory is typically mapped in the kernel. On Linux and OS X,this is done via a direct-physical map, i.e., the entire physical memory is directly mappedto a pre-defined virtual address (cf. Figure 2).
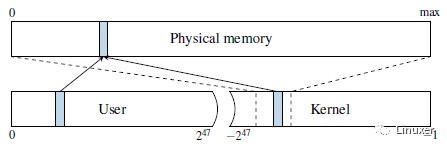
為了相互隔離行程,CPU支援虛擬地址空間,但是CPU向匯流排發出的是物理地址,因此程式中的虛擬地址需要被轉換為物理地址。虛擬地址空間被劃分成一個個的頁面,這些頁面又可以透過多級頁表對映到物理頁面。除了虛擬地址到物理地址的對映,頁表也定義了保護屬性,如可讀的、可寫的、可執行的和使用者態是否可訪問等。當前使用頁表儲存在一個特殊的CPU暫存器中(對於X86,這個暫存器就是cr3,對於ARM,這個暫存器是TTBR系列暫存器)。在背景關係切換中,作業系統總是會用下一個行程的頁表地址來更新這個暫存器,從而實現了行程虛擬地址空間的切換。因此,每個行程只能訪問屬於自己虛擬地址空間的資料。每個行程的虛擬地址空間本身被分成使用者地址空間和核心地址空間部分。當行程執行在使用者態的時候只可以訪問使用者地址空間,只有在核心態下(CPU執行在特權樣式),才可以訪問核心地址空間。作業系統會disable核心地址空間對應頁表中的使用者是否可訪問屬性,從而禁止了使用者態對核心空間的訪問。核心地址空間不僅為自身建立記憶體對映(例如內核的正文段,資料段等),而且還需要對使用者頁面進行操作,例如填充資料。因此,整個系統中的物理記憶體通常會對映在核心地址空間中。在Linux和OS X上,這是透過直接對映(direct-physical map)完成的,也就是說,整個物理記憶體直接對映到預定義的虛擬地址(參見上圖)。
Instead of a direct-physical map, Windows maintains a multiple so-called paged pools, non-paged pools, and thesystem cache. These pools are virtual memoryregions in the kernel address space mapping physical pages to virtual addresseswhich are either required to remain in the memory (non-paged pool) or can beremoved from the memory because a copy is already stored on the disk (pagedpool). The system cache further contains mappings of allfile-backed pages. Combined, these memory pools will typically map a largefraction of the physical memory into the kernel address space of every process.
Windows中的地址對映機制,沒有興趣瞭解。
The exploitation of memory corruption bugs often requires the knowledge ofaddresses of specific data. In order to impede such attacks, address spacelayout randomization (ASLR) has been introduced as well as nonexecutable stacksand stack canaries. In order to protect the kernel, KASLR randomizes theoffsets where drivers are located on every boot, making attacks harder as they nowrequire to guess the location of kernel data structures. However, side-channelattacks allow to detect the exact location of kernel data structures [9, 13,17] or derandomize ASLR in JavaScript [6]. A combination of a software bug andthe knowledge of these addresses can lead to privileged code execution.
利用memory corruption(指修改記憶體的內容而造成crash)bug進行攻擊往往需要知道特定資料的地址(因為我們需要修改該地址中的資料)。為了阻止這種攻擊,核心提供了地址空間佈局隨機化(ASLR)、非執行堆疊和堆疊上限溢位檢查三種手段。為了保護核心,KASLR會在驅動每次開機載入的時候將其放置在一個隨機偏移的位置,這種方法使得攻擊變得更加困難,因為攻擊者需要猜測核心資料結構的地址資訊。然而,攻擊者可以利用側通道攻擊手段獲取核心資料結構的確定位置[ 9, 13, 17 ]或者在JavaScript中對ASLR 解隨機化[ 6 ]。結合本節描述的兩種機制,我們可以發起攻擊,實現特權程式碼的執行。
3、快取攻擊(Cache Attacks)
In order to speed-up memory accesses and address translation, the CPUcontains small memory buffers, called caches, that store frequently used data.CPU caches hide slow memory access latencies by buffering frequently used datain smaller and faster internal memory. Modern CPUs have multiple levels ofcaches that are either private to its cores or shared among them. Address spacetranslation tables are also stored in memory and are also cached in the regularcaches.
為了加速記憶體訪問和地址翻譯過程,CPU內部包含了一些小的記憶體緩衝區,我們稱之為cache,用來儲存近期頻繁使用的資料,這樣,CPU cache實際上是隱藏了底層慢速記憶體的訪問延遲。現代CPU有多個層次的cache,它們要麼是屬於特定CPU core的,要麼是在多個CPU core中共享的。地址空間的頁表儲存在記憶體中,它也被快取在cache中(即TLB)。
Cache side-channel attacks exploit timing differences that are introducedby the caches. Different cache attack techniques have been proposed anddemonstrated in the past, including Evict+Time [28], Prime+Probe [28, 29], andFlush+Reload [35]. Flush+Reload attacks work on a single cache linegranularity. These attacks exploit the shared, inclusive last-level cache. Anattacker frequently flushes a targeted memory location using the clflushinstruction. By measuring the time it takes to reload thedata, the attacker determines whether data was loaded into the cache by anotherprocess in the meantime. The Flush+Reload attack has been used for attacks onvarious computations, e.g., cryptographic algorithms [35, 16, 1], web serverfunction calls [37], user input [11, 23, 31], and kernel addressing information[9].
快取側通道攻擊(Cache side-channel attack)是一種利用快取引入的時間差異而進行攻擊的方法,在訪問memory的時候,已經被cache的資料訪問會非常快,而沒有被cache的資料訪問比較慢,快取側通道攻擊就是利用了這個時間差來偷取資料的。各種各樣的快取攻擊技術已經被提出並證明有效,包括Evict+Time [28 ],Prime+Probe [28, 29 ],Flush+Reload [35 ]。Flush+Reload方法在單個快取行粒度上工作。快取側通道攻擊主要是利用共享的cache(包含的最後一級快取)進行攻擊。攻擊者經常使用CLFLUSH指令將標的記憶體位置的cache刷掉。然後讀標的記憶體的資料並測量標的記憶體中資料載入所需的時間。透過這個時間資訊,攻擊者可以獲取另一個行程是否已經將資料載入到快取中。Flush+Reload攻擊已被用於攻擊各種演演算法,例如,密碼演演算法[ 35, 16, 1],Web伺服器函式呼叫[ 37 ],使用者輸入[ 11, 23, 31 ],以及核心定址資訊[ 9 ]。
A special use case are covert channels. Here the attacker controls both,the part that induces the side effect, and the part that measures the sideeffect. This can be used to leak information from one security domain toanother, while bypassing any boundaries existing on the architectural level orabove. Both Prime+Probe and Flush+Reload have been used in high-performancecovert channels [24, 26, 10].
快取側通道攻擊一個特殊的使用場景是構建隱蔽通道(covert channel)。在這個場景中,攻擊者控制隱蔽通道的傳送端和接收端,也就是說攻擊者會透過程式觸發產生cache side effect,同時他也會去量測這個cache side effect。透過這樣的手段,資訊可以繞過體系結構級別的邊界檢查,從一個安全域洩漏到外面的世界,。Prime+Probe 和 Flush+Reload這兩種方法都已被用於構建高效能隱蔽通道[ 24, 26, 10 ]。
三、簡單示例(A toy example)
In this section, we start with a toy example, a simple code snippet, toillustrate that out-of-order execution can change the microarchitectural statein a way that leaks information. However, despite its simplicity, it is used asa basis for Section 4 and Section 5, where we show how this change in state canbe exploited for an attack.
在這一章中,我們給出一個簡單的例子,並說明瞭在亂序執行的CPU上執行示例程式碼是如何改變CPU的微架構狀態並洩露資訊的。儘管它很簡單,不過仍然可以作為第4章和第5章的基礎(在這些章節中,我們會具體展示meltdown攻擊)。
Listing 1 shows a simple code snippet first raising an (unhandled)exception and then accessing an array. The property of an exception is that thecontrol flow does not continue with the code after the exception, but jumps to anexception handler in the operating system. Regardless of whether this exceptionis raised due to a memory access, e.g., by accessing an invalid address, or dueto any other CPU exception, e.g., a division by zero, the control flowcontinues in the kernel and not with the next user space instruction.
|
1 raise_exception(); 2 // the line below is never reached 3 access(probe_array[data * 4096]); |
上面的串列顯示了一個簡單的程式碼片段:首先觸發一個異常(我們並不處理它),然後訪問probe_array陣列。異常會導致控制流不會執行異常之後的程式碼,而是跳轉到作業系統中的異常處理程式去執行。不管這個異常是由於記憶體訪問而引起的(例如訪問無效地址),或者是由於其他型別的CPU異常(例如除零),控制流都會轉到核心中繼續執行,而不是停留在使用者空間,執行對probe_array陣列的訪問。
Thus, our toy examplecannot access the array in theory, as the exception immediately traps to thekernel and terminates the application. However, due to the out-of-order execution,the CPU might have already executed the following instructions as there is nodependency on the exception. This is illustrated in Figure 3. Due to the exception,the instructions executed out of order are not retired and, thus, never havearchitectural effects.

因此,我們給出的示例程式碼在理論上不會訪問probe_array陣列,畢竟異常會立即陷入核心並終止了該應用程式。但是由於亂序執行,CPU可能已經執行了異常指令後面的那些指令,要知道異常指令和隨後的指令沒有依賴性。如上圖所示。雖然異常指令後面的那些指令被執行了,但是由於產生了異常,那些指令並沒有提交(註:instruction retire,instruction commit都是一個意思,就是指將指令執行結果體現到軟體可見的暫存器或者memory中,不過retire這個術語翻譯成中文容易引起誤會,因此本文統一把retire翻譯為提交或者不翻譯),因此從CPU 體系結構角度看沒有任何問題(也就是說軟體工程師從ISA的角度看不到這些指令的執行)。
Although the instructions executed out of order do not have any visiblearchitectural effect on registers or memory, they have microarchitectural sideeffects. During the out-of-order execution, the referenced memory is fetched intoa register and is also stored in the cache. If the out-of-order execution hasto be discarded, the register and memory contents are never committed.Nevertheless, the cached memory contents are kept in the cache. We can leveragea microarchitectural side-channel attack such as Flush+Reload [35], whichdetects whether a specific memory location is cached, to make thismicroarchitectural state visible. There are other side channels as well whichalso detect whether a specific memory location is cached, including Prime+Probe[28, 24, 26], Evict+ Reload [23], or Flush+Flush [10]. However, as Flush+ Reloadis the most accurate known cache side channel and is simple to implement, we donot consider any other side channel for this example.
雖然違反了program order,在CPU上執行了本不應該執行的指令,但是實際上從暫存器和memory上看,我們不能捕獲到任何這些指令產生的變化(也就是說沒有architecture effect)。不過,從CPU微架構的角度看確實是有副作用。在亂序執行過程中,載入記憶體值到暫存器同時也會把該值儲存在cache中。如果必須要丟棄掉亂序執行的結果,那麼暫存器和記憶體值都不會commit。但是,cache中的內容並沒有丟棄,仍然在cache中。這時候,我們就可以使用微架構側通道攻擊(microarchitectural side-channel attack)的方法,例如Flush+Reload [35],來檢測是否指定的記憶體地址被cache了,從而讓這些微架構狀態資訊變得對使用者可見。我們也有其他的方法來檢測記憶體地址是否被快取,包括:Prime+Probe [28, 24, 26],Evict+ Reload [23], 或者Flush+Flush [10]。不過Flush+ Reload是最準確的感知cache sidechannel的方法,並且實現起來非常簡單,因此在本文中我們主要介紹Flush+ Reload。
Based on the value of data in this toy example, a different partof the cache is accessed when executing the memory access out of order. As data is multiplied by 4096, data accesses to probe array are scattered over the array with adistance of 4 kB (assuming an 1 B data type for probe array). Thus, there is an injective mapping from the value of data to a memory page, i.e., there are no two different values ofdata which result in an access to the same page. Consequently, if a cache lineof a page is cached, we know the value of data. The spreading over different pages eliminates falsepositives due to the prefetcher, as the prefetcher cannot access data across pageboundaries [14].
我們再次回到上面串列中的示例程式碼。probe_array是一個按照4KB位元組組織的陣列,變化data變數的值就可以按照4K size來遍歷訪問該陣列。如果在亂序執行中訪問了data變數指定的probe_array陣列內的某個4K記憶體塊,那麼對應頁面(指的是probe_array陣列內的4K記憶體塊)的資料就會被載入到cache中。因此,透過程式掃描probe_array陣列中各個頁面的cache情況可以反推出data的數值(data數值和probe_array陣列中的頁面是一一對應的)。在Intel處理器中,prefetcher不會跨越page的邊界,因此page size之間的cache狀態是完全獨立的。而在程式中把cache的檢測分散到若干個page上主要是為了防止prefetcher帶來的誤報。
Figure 4 shows theresult of a Flush+Reload measurement iterating over all pages, after executingthe out-oforder snippet with data= 84. Although the array accessshould not have happened due to the exception, we can clearly see that theindex which would have been accessed is cached. Iterating over all pages (e.g.,in the exception handler) shows only a cache hit for page 84 This shows thateven instructions which are never actually executed, change themicroarchitectural state of the CPU. Section 4 modifies this toy example to notread a value, but to leak an inaccessible secret.

上圖是透過Flush+Reload 方法遍歷probe_array陣列中的各個page並計算該page資料的訪問時間而繪製的坐標圖。橫坐標是page index,共計256個,縱坐標是訪問時間,如果cache miss,那麼訪問時間大概是400多個cycle,如果cache hit,訪問時間大概是200個cycle以下,二者有顯著的區別。從上圖我們可以看出,雖然由於異常,probe_array陣列訪問不應該發生,不過在data=84上明顯是cache hit的,這也說明瞭在亂序執行下,本不該執行的指令也會影響CPU微架構狀態,在下麵的章節中,我們將修改示例程式碼,去竊取秘密資料。
四、Meltdown攻擊架構圖(Building block ofattack)
The toy example in Section 3 illustrated that side-effects of out-of-orderexecution can modify the microarchitectural state to leak information. Whilethe code snippet reveals the data value passed to a cache-side channel, we wantto show how this technique can be leveraged to leak otherwise inaccessiblesecrets. In this section, we want to generalize and discuss the necessarybuilding blocks to exploit out-of-order execution for an attack.
上一章中我們透過簡單的示例程式碼展示了亂序執行的副作用會修改微架構狀態,從而造成資訊洩露。透過程式碼片段我們已經看到了data變數值已經傳遞到快取側通道上,下麵我們會詳述如何利用這種技術來洩漏受保護的資料。在本章中,我們將概括並討論利用亂序執行進行攻擊所需要的元件。
The adversary targets a secret value that is kept somewhere in physicalmemory. Note that register contents are also stored in memory upon contextswitches, i.e., they are also stored in physicalmemory. As described in Section 2.2, the address space of every processtypically includes the entire user space, as well as the entire kernel space,which typically also has all physical memory (inuse) mapped. However, thesememory regions are only accessible in privileged mode (cf. Section 2.2).
攻擊者的標的是儲存在物理記憶體中的一個秘密值。註意:暫存器值也會在背景關係切換時儲存在物理記憶體中。根據2.2節所述,每個行程的地址空間通常包括整個使用者地址空間以及整個核心地址空間(使用中的物理記憶體都會對映到該空間中),雖然行程能感知到核心空間的對映。但是這些記憶體區域只能在特權樣式下訪問(參見第2.2節)。
In this work, we demonstrate leaking secrets by bypassing theprivileged-mode isolation, giving an attacker full read access to the entirekernel space including any physical memory mapped, including the physicalmemory of any other process and the kernel. Note that Kocher et al. [19] pursuean orthogonal approach, called Spectre Attacks, which trick speculativeexecuted instructions into leaking information that the victim process isauthorized to access. As a result, Spectre Attacks lack the privilegeescalation aspect of Meltdown and require tailoring to the victim process’ssoftware environment, but apply more broadly to CPUs that support speculative executionand are not stopped by KAISER.
在這項工作中,我們繞過了地址空間隔離機制,讓攻擊者可以對整個核心空間進行完整的讀訪問,這裡面就包括物理記憶體直接對映部分。而透過直接對映,攻擊者可以訪問任何其他行程和內核的物理記憶體。註意:Kocher等人[ 19 ]正在研究一種稱為幽靈(spectre)攻擊的方法,它透過推測執行(speculative execution)來洩漏標的行程的秘密資訊。因此,幽靈攻擊不涉及Meltdown攻擊中的特權提升,並且需要根據標的行程的軟體環境進行定製。不過spectre會影響更多的CPU(只要支援speculativeexecution的CPU都會受影響),另外,KAISER無法阻擋spectre攻擊。
The full Meltdownattack consists of two building blocks, as illustrated in Figure 5. The firstbuilding block of Meltdown is to make the CPU execute one or more instructionsthat would never occur in the executed path. In the toy example (cf. Section3), this is an access to an array, which would normally never be executed, as theprevious instruction always raises an exception. We call such an instruction,which is executed out of order, leaving measurable side effects, a transientinstruction. Furthermore, wecall any sequence of instructions containing at least one transient instructiona transient instruction sequence.

完整的meltdown攻擊由兩個元件構成,如上圖所示。第一個元件是使CPU執行一個或多個在正常路徑中永遠不會執行的指令。在第三章中的簡單示例程式碼中,對陣列的訪問指令按理說是不會執行,因為前面的指令總是觸發異常。我們稱這種指令為瞬態指令(transient instruction),瞬態指令在亂序執行的時候被CPU執行(正常情況下不會執行),留下可測量的副作用。此外,我們把任何包含至少一個瞬態指令的指令序列稱為瞬態指令序列。
In order to leverage transient instructions for an attack, the transientinstruction sequence must utilize a secret value that an attacker wants toleak. Section 4.1 describes building blocks to run a transient instructionsequence with a dependency on a secret value.
為了使用瞬態指令來完成攻擊,瞬態指令序列必須訪問攻擊者想要獲取的秘密值並加以利用。第4.1節將描述一段瞬態指令序列,我們會仔細看看這段指令會如何使用受保護的資料。
The second building block of Meltdown is to transfer themicroarchitectural side effect of the transient instruction sequence to anarchitectural state to further process the leaked secret. Thus, the secondbuilding described in Section 4.2 describes building blocks to transfer amicroarchitectural side effect to an architectural state using a covertchannel.
Meltdown的第二個元件主要用來檢測在瞬態指令序列執行完畢之後,在CPU微架構上產生的side effect。並將其轉換成軟體可以感知的CPU體系結構的狀態,從而將資料洩露出來。因此,在4.2節中描述的第二個元件主要是使用隱蔽通道來把CPU微架構的副作用轉換成CPU architectural state。
1、執行瞬態指令(executing transient instructions)
The first building block of Meltdown is the execution of transientinstructions. Transient instructions basically occur all the time, as the CPUcontinuously runs ahead of the current instruction to minimize the experienced latencyand thus maximize the performance (cf. Section 2.1). Transient instructionsintroduce an exploitable side channel if their operation depends on a secretvalue. We focus on addresses that are mapped within the attacker’s process, i.e., the user-accessible user spaceaddresses as well as the user-inaccessible kernel space addresses. Note thatattacks targeting code that is executed
within the context (i.e., address space) of another process are possible [19],but out of scope in this work, since all physical memory (including the memoryof other processes) can be read through the kernel address space anyway.
Meltdown的第一個元件是執行瞬態指令。其實瞬態指令是時時刻刻都在發生的,因為CPU在執行當前指令之外,往往會提前執行當前指令之後的那些指令,從而最大限度地提高CPU效能(參見第2.1節的描述)。如果瞬態指令的執行依賴於一個受保護的值,那麼它就引入一個可利用的側通道。另外需要說明的是:本文主要精力放在攻擊者的行程地址空間中,也就是說攻擊者在使用者態訪問核心地址空間的受保護的資料。實際上攻擊者行程訪問盜取其他行程地址空間的資料也是可能的(不過本文並不描述這個場景),畢竟攻擊者行程可以透過核心地址空間訪問系統中所有記憶體,而其他行程的資料也就是儲存在系統物理記憶體的某個地址上。
Accessing user-inaccessible pages, such as kernel pages, triggers anexception which generally terminates the application. If the attacker targets asecret at a user inaccessible address, the attacker has to cope with this exception.We propose two approaches: With exception handling, we catch the exception effectivelyoccurring after executing the transient instruction sequence, and with exceptionsuppression, we prevent theexception from occurring at all and instead redirect the control flow afterexecuting the transient instruction sequence. We discuss these approaches indetail in the following.
執行於使用者態時訪問特權頁面,例如核心頁面,會觸發一個異常,該異常通常終止應用程式。如果攻擊者的標的是一個核心空間地址中儲存的資料,那麼攻擊者必須處理這個異常。我們提出兩種方法:一種方法是設定異常處理函式,在發生異常的時候會呼叫該函式(這時候已經完成了瞬態指令序列的執行)。第二種方法是抑制異常的觸發,下麵我們將詳細討論這些方法。
Exception handling. A trivial approach is to fork the attacking applicationbefore accessing the invalid memory location that terminates the process, andonly access the invalid memory location in the child process. The CPU executesthe transient instruction sequence in the child process before crashing. Theparent process can then recover the secret by observing the microarchitectural state,e.g., through a side-channel.
程式自己定義異常處理函式。
一個簡單的方法是在訪問核心地址(這個操作會觸發異常並中止程式的執行)之前進行fork的操作,並只在子行程中訪問核心地址,觸發異常。在子行程crash之前,CPU已經執行了瞬態指令序列。在父行程中可以透過觀察CPU微架構狀態來盜取核心空間的資料。
It is also possible to install a signal handler that will be executed if acertain exception occurs, in this specific case a segmentation fault. Thisallows the attacker to issue the instruction sequence and prevent theapplication from crashing, reducing the overhead as no new process has to becreated.
當然,你也可以設定訊號處理函式。異常觸發後將執行該訊號處理函式(在這個場景下,異常是segmentation fault)。這種方法的好處是應用程式不會crash,不需要建立新行程,開銷比較小。
Exception suppression.
這種方法和Transactional memory相關,有興趣的同學可以自行閱讀原文。
2、構建隱蔽通道(building covert channel)
The second building block of Meltdown is the transfer of themicroarchitectural state, which was changed by the transient instructionsequence, into an architectural state (cf. Figure 5). The transient instructionsequence can be seen as the sending end of a microarchitectural covert channel.The receiving end of the covert channel receives the microarchitectural statechange and deduces the secret from the state. Note that the receiver is not partof the transient instruction sequence and can be a different thread or even adifferent process e.g., the parent process in the fork-and-crash approach.
第二個Meltdown元件主要是用來把執行瞬態指令序列後CPU微架構狀態變化的資訊轉換成相應的體系結構狀態(參考上圖)。瞬態指令序列可以認為是微架構隱蔽通道的髮端,通道的接收端用來接收微架構狀態的變化資訊,從這些狀態變化中推匯出被保護的資料。需要註意的是:接收端並不是瞬態指令序列的一部分,可以來自其他的執行緒甚至是其他的行程。例如上節我們使用fork的那個例子中,瞬態指令序列在子行程中,而接收端位於父行程中
We leverage techniques from cache attacks, as the cache state is amicroarchitectural state which can be reliably transferred into anarchitectural state using various techniques [28, 35, 10]. Specifically, we useFlush+Reload [35], as it allows to build a fast and low-noise covert channel.Thus, depending on the secret value, the transient instruction sequence (cf.Section 4.1) performs a regular memory access, e.g., as it does in the toyexample (cf. Section 3).
我們可以利用快取攻擊(cache attack)技術,透過對高速快取的狀態(是微架構狀態之一)的檢測,我們可以使用各種技術[ 28, 35, 10 ]將其穩定地轉換成CPU體系結構狀態。具體來說,我們可以使用Flush+Reload技術 [35],因為該技術允許建立一個快速的、低噪聲的隱蔽通道。然後根據保密資料,瞬態指令序列(參見第4.1節)執行常規的儲存器訪問,具體可以參考在第3節給出的那個簡單示例程式中所做的那樣。
After the transient instruction sequence accessed an accessible address, i.e., this is the sender of the covert channel;the address is cached for subsequent accesses. The receiver can then monitorwhether the address has been loaded into the cache by measuring the access timeto the address. Thus, the sender can transmit a ‘1’-bit by accessing an address which is loaded intothe monitored cache, and a ‘0’-bitby not accessing such an address.
在隱蔽通道的傳送端,瞬態指令序列會訪問一個普通記憶體地址,從而導致該地址的資料被載入到了cache(為了加速後續訪問)。然後,接收端可以透過測量記憶體地址的訪問時間來監視資料是否已載入到快取中。因此,傳送端可以透過訪問記憶體地址(會載入到cache中)傳遞bit 1的資訊,或者透過不訪問記憶體地址(不會載入到cache中)來傳送bit 0資訊。而接收端可以透過監視cache的資訊來接收這個bit 0或者bit 1的資訊。
Using multiple different cache lines, as in our toy example in Section 3,allows to transmit multiple bits at once. For every of the 256 different bytevalues, the sender accesses a different cache line. By performing aFlush+Reload attack on all of the 256 possible cache lines, the receiver canrecover a full byte instead of just one bit. However, since the Flush+Reloadattack takes much longer (typically several hundred cycles) than the transientinstruction sequence, transmitting only a single bit at once is more efficient.The attacker can simply do that by shifting and masking the secret valueaccordingly.
使用一個cacheline可以傳遞一個bit,如果使用多個不同的cacheline(類似我們在第3章中的簡單示例程式碼一樣),就可以同時傳輸多個位元。一個Byte(8-bit)有256個不同的值,針對每一個值,傳送端都會訪問不同的快取行,這樣透過對所有256個可能的快取行進行Flush+Reload攻擊,接收端可以恢復一個完整位元組而不是一個bit。不過,由於Flush+Reload攻擊所花費的時間比執行瞬態指令序列要長得多(通常是幾百個cycle),所以只傳輸一個bit是更有效的。攻擊者可以透過shift和mask來完成保密資料逐個bit的盜取。
Note that the covert channel is not limited to microarchitectural stateswhich rely on the cache. Any microarchitectural state which can be influencedby an instruction (sequence) and is observable through a side channel can beused to build the sending end of a covert channel. The sender could, forexample, issue an instruction (sequence) which occupies a certain executionport such as the ALU to send a ‘1’-bit.The receiver measures the latency when executing an instruction (sequence) onthe same execution port. A high latency implies that the sender sends a ‘1’-bit, whereas a low latency implies thatsender sends a ‘0’-bit. Theadvantage of the Flush+ Reload cache covert channel is the noise resistance andthe high transmission rate [10]. Furthermore, the leakage can be observed fromany CPU core [35], i.e., rescheduling eventsdo not significantly affect the covert channel.
需要註意的是:隱蔽通道並非總是依賴於快取。只要CPU微架構狀態會被瞬態指令序列影響,並且可以透過side channel觀察這個狀態的改變,那麼該微架構狀態就可以用來構建隱蔽通道的傳送端。例如,傳送端可以執行一條指令(該指令會佔用相關執行單元(如ALU)的埠),來傳送一個“1”這個bit。接收端可以在同一個執行單元埠上執行指令,同時測量時間延遲。高延遲意味著傳送方傳送一個“1”位,而低延遲意味著傳送方傳送一個“0”位。Flush+ Reload隱蔽通道的優點是抗噪聲和高傳輸速率[ 10 ]。此外,我們可以從任何cpu core上觀察到資料洩漏[ 35 ],即排程事件並不會顯著影響隱蔽通道。
本文未完待續
