在Feed系統中,有簡單資料型別的快取,有集合類資料的。還有一些個性業務的快取。比如大量的計數器場景,存在性判斷場景等。微博解決存在性判斷業務的快取層叫EXISTENCE 快取層,解決計算器場景的快取叫COUNTER快取。
EXISTENCE 快取層主要用於快取各種存在性判斷的業務,諸如是否已贊(liked)、是否已閱讀(readed)這類需求。
Feed系統內部有大量的計數場景,如使用者維度有關註數、粉絲數、feed發表數,feed維度有轉發數、評論數、贊數以及閱讀數等。前面提到,按照傳統Redis、Memcached計數快取方案,單單存每日新增的十億級的計數,就需要新佔用百G級的記憶體,成本開銷巨大。因此微博開發了計數服務元件CounterService。下麵以計數場景來管中窺豹。
提出問題
對於計數業務,經典的構建模型有兩種:1 db+cache樣式,全量計數存在db,熱資料透過cache加速;2全量存在Redis中。方案1 通用成熟,但對於一致性要求較高的計數服務,以及在海量資料和高併發訪問場景下,支援不夠友好,運維成本和硬體成本較高,微博上線初期曾使用該方案,在Redis面世後很快用新方案代替。方案2基於Redis的計數介面INCR、DECR,能很方便的實現通用的計數快取模型,再透過hash分表,master-slave部署方式,可以實現一個中小規模的計數服務。
但在面對千億級的歷史海量計數以及每天十億級的新增計數,直接使用Redis的計數模型存在嚴重的成本和效能問題。首先Redis計數作為通用的全記憶體計數模型,記憶體效率不高。儲存一個key為8位元組(long型id)、value為4位元組的計數,Redis至少需要耗費65位元組。1000億計數需要100G*65=6.5T以上的記憶體,算上一個master配3個slave的開銷,總共需要26T以上的記憶體,按單機記憶體96G計算,扣掉Redis其他記憶體管理開銷、系統佔用,需要300-400臺機器。如果算上多機房,需要的機器數會更多。其次Redis計數模型的獲取效能不高。一條微博至少需要3個計數查詢,單次feed請求如果包含15條微博,僅僅微博計數就需要45個計數查詢。
解決問題
在Feed系統的計數場景,單條feed的各種計數都有相同的key(即微博id),可以把這些計數儲存在一起,就能節省大量的key的儲存空間,讓1000億計數變成了330億條記錄;近一半的微博沒有轉、評論、贊,拋棄db+cache的方案,改用全量儲存的方案,對於沒有計數為0的微博不再儲存,如果查不到就傳回0,這樣330億條記錄只需要存160億條記錄。然後又對儲存結構做了進一步最佳化,三個計數和key一起一共只需要8+4*3=20位元組。總共只需要16G*20=320G,算上1主3從,總共也就只需要1.28T,只需要15臺左右機器即可。同時進一步透過對CounterService增加SSD擴充套件支援,按table滾動,老資料落在ssd,新資料、熱資料在記憶體,1.28T的容量幾乎可以用單臺機器來承載(當然考慮訪問效能、可用性,還是需要hash到多個快取節點,並新增主從結構)。
計數器元件的架構如圖13-14,主要特性如下:
1) 記憶體最佳化:透過預先分配的記憶體陣列Table儲存計數,並且採用 double hash 解決衝突,避免Redis 實現中的大量指標開銷。
2) Schema支援多列:一個feed id對應的多個計數可以作為一條計數記錄,還支援動態增減計數列,每列的計數記憶體使用精簡到bit;
3) 冷熱資料分離,根據時間維度,近期的熱資料放在記憶體,之前的冷資料放在磁碟,降低機器成本;
4) LRU快取:之前的冷資料如果被頻繁訪問則放到LRU快取進行加速;
5) 非同步IO執行緒訪問冷資料:冷資料的載入不影響服務的整體效能。
|
|
|
圖 13-14 基於Redis擴充套件後的計數器儲存架構 |
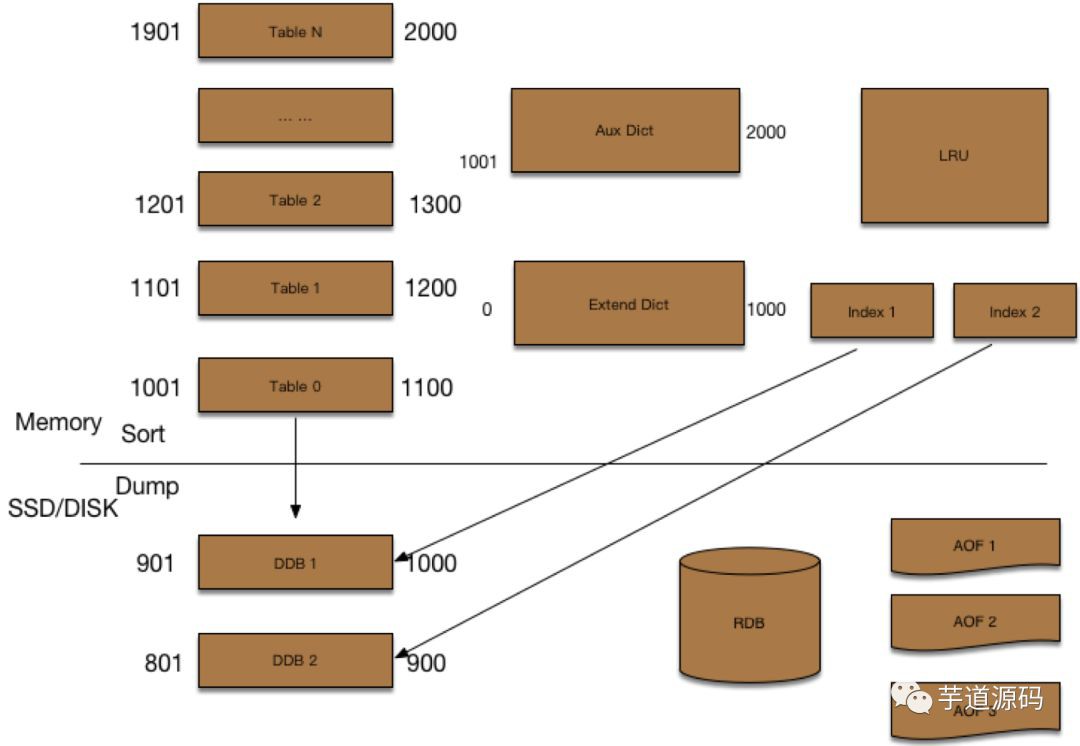
透過上述的擴充套件,記憶體佔用降為之前的5-10%以下,同時一條feed的評論/贊等多個計數、一個使用者的粉絲/關註/微博等多個計數都可以一次性獲取,讀取效能大幅提升,基本徹底解決了計數業務的成本及效能問題。
欲瞭解更多有關分散式快取方面的內容,請閱讀《深入分散式快取:從原理到實踐》一書。



京東購書,掃描二維碼:

