

來源:大資料文摘
作者:seattle data guy
編譯:王夢澤、吳雙、蔣寶尚
想成為一名高階資料科學家除了擁有卓越的專業技能,你還需要其它技能來拉近和業務經理的距離。這看起來簡單,但隨著每年新技術的不斷累積,技術和業務之間的距離會繼續增大。因此,我們發現管理者和資料科學家有清晰的合作方向是非常重要的。
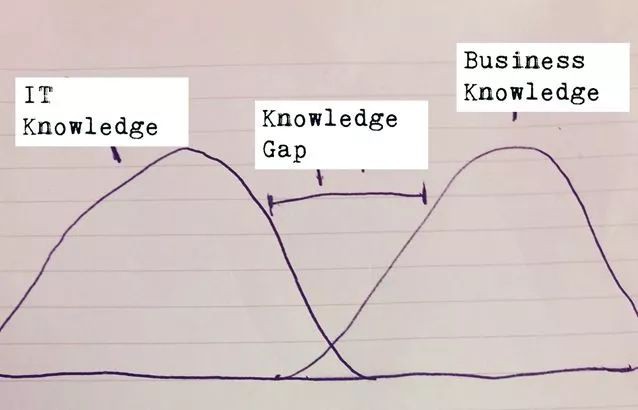
業務和IT知識都是十分專業的,然而由於技能的專業化,許多企業都出現了兩個專業間的空白。我們的任務是幫助填補它!
資料科學家必須有技術方面的扎實基本功,這包括程式設計、查詢、資料清洗等。然而隨著資料科學家的成長,他們需要更多地關註設計決策以及與管理者的溝通,這會大大增強經驗豐富的資料科學家的影響力。他們可以做出更高層次的決策,並幫助陷入困境的年輕資料科學家,而不是被困在日復一日的編碼中。更有經驗的資料科學家能利用他們的經驗來做出簡化複雜系統、最佳化資料流的設計決策,同時協助決定哪些專案最為恰當,這使得資料科學家自身及其公司都能有更大獲益。
能夠做到化繁為簡
資料科學家往往希望將他們所知道的每一種技術和演演算法都應用於每一個問題的解決方案上。相應地,這就會使系統非常複雜難以維護。
資料科學確實需要複雜抽象的模型及大量的複雜技術(從Hadoop到Tensorflow)。在這個充斥著複雜性的領域,人們會傾向於開發複雜的系統和演演算法,稍不留神就會在開發中涉及四、五種不同的技術並使新的熱門演演算法或框架。然而,像大多數涉及工程的其他領域一樣,減少複雜性往往會帶來諸多好處。

如果馮•諾依曼,埃爾溫•薛定諤和愛因斯坦可以幫助我們理解數學和物理驅動領域的複雜性,那麼我們資料科學家不能隱藏在複雜性背後。
工程師的角色就是去簡化任務。如果你曾經建造或看到過魯布•戈德堡機械(Rube Goldberg machine),你會理解什麼是用複雜方法去完成簡單任務。一些資料科學家的演演算法和資料系統看起來像是用膠帶和口香糖粘起來的老鼠夾,而不是簡潔有效的解決方案。更簡單的系統意味著隨著時間推移系統會更加容易維護,並且未來的資料科學家能夠按需新增和刪除模組。但若你使用三種不同的語言,兩個資料源,十個演演算法且沒有留下任何檔案資料,未來的工程師可能會默默詛咒你哦。
簡單的演演算法和系統也應使新增和刪減模組是容易的。因此當需要技術進行改變和更新或者需要刪除模組時,可憐的未來資料科學家不會陷入和你的程式碼一起玩疊疊樂積木遊戲(Jenga)的困境 。但會糾結於“如果刪了這段程式碼,系統會不會崩潰”。(這一糾結的根源是怕出現技術債務)
知道如何在沒有主鍵的情況下關聯匹配資料
強大的資料專家能做的重要工作之一是:將可能沒有主鍵或明顯聯絡的資料集關聯在一起。資料可以呈現人之間或業務之間的日常互動。能夠在這些資料中找出統計樣式,是資料科學家可以幫助決策者作出明智決定的重要能力。然而,你想要關聯在一起的資料並不總是位於相同的系統或有著相同粒度。
與資料打交道的人會知道,資料並不總是很好的整合在一個資料庫中。比如,財務資料與IT服務管理資料通常是分開存放的,外部的資料源往往可能並不是在同一個維度進行的聚合。這會成為一個問題,因為找出資料中的價值有時確實會需要來自其他部門或系統的資料。

資料嚙合是需要在相同的粒度級別上進行的。一種理解的方式是:將一塊大拼圖與由許多小塊資料拼圖組成的大拼圖組合起來。
例如,假如給你提供了醫療保單、信用卡和社群犯罪率的資料,想由此找出這些社會經濟因素如何影響病人,你會怎樣處理?一些資料可能是以人為單位,而另一些資料可能是街道或城市級別,而且沒有明確的方式來關聯這些資料集。最好的處理方式是什麼?這成為了一個不能忽視且必須被解決的問題。
對專案進行優先排序
作為資料科學家,你需要知道如何解釋可能不划算的專案的投資回報率(ROI)。這與良好的直接溝通有關(我們的團隊永遠不會停止討論如何溝通),也與能夠清楚表達價值並且對長短期標的進行優先排序有關(重申一遍,說起來容易做起來難)
團隊總是會有超出他們處理能力的過多的專案和專案要求。有經驗的團隊成員需要起帶頭作用來幫助決策者決定哪些專案是值得進行的。在有很大機會成功但可能不會有最高投資回報率的短期專案和很有可能會失敗但同時也會產生較大投資回報率的長期專案之間需要有一個良好的平衡。
這種情況下,決策矩陣會有助於簡化過程。
經典的決策矩陣之一是一個2*2矩陣,行和列分別為重要性和緊迫性。多數的大學商業課程中都會出現這種矩陣,它很簡單,這也是它很棒的原因。
我曾在公司和一些很聰明的人共事,但還是工作中的每個專案都被列為優先。如果你沒聽過這個說法,我會在這裡講出來:
如果每件事都被優先考慮,那麼,相當於沒有事情被排在優先。

選擇正確的專案意味著必須做出取捨。不是所有的事情都是高優的。
許多公司都存在這個問題,這就是為什麼對於資料科學家團隊中有經驗的成員,能夠清晰表達出哪些專案需要當下執行還是以後執行是非常重要的。而使用這個簡單的矩陣能帶來一定幫助。
(簡潔十分重要,使用矩陣來明確投資回報率是有幫助的)。
有了簡明直接的溝通,專案繼續向前推進,信任也隨之建立起來了。
能夠開發出穩健且最優的系統
做出能在受控環境中操作的演演算法或模型是一回事。將穩健模型整合到實時且能處理大量資料的系統又是另一回事。根據公司的不同,有時資料科學家只需開發演演算法本身,之後開發人員或機器學習工程師會負責將其轉為上線的產品。
然而還會有其他的情況,小的公司和小的團隊可能會需要資料科學家團隊來將程式碼轉為上線產品。這意味著演演算法需要能以合理的速度控制資料流量。如果演演算法要執行三個小時並且需要被實時訪問,這顯然不能在產品上使用。因此,良好的系統設計及最佳化是必要的。

隨著資料增多,越來越多的人會與系統互動,模型跟上腳步是十分重要的。
當高階資料專家的技術能力和其他能力相結合時,才能對他們自身和其公司產生最大的影響。資料科學家寶貴的經驗是非常有價值的,這些經驗能夠指導年輕的開發人員做出更好的設計決策,幫助管理者找出哪些專案會帶來最好的投資回報率,從而也放大了他們的參與對於團隊的影響。
原文連結:
https://hackernoon.com/4-must-have-skills-every-data-scientist-should-learn-8ab3f23bc325
精彩活動
推薦閱讀
2017年資料視覺化的七大趨勢!
全球100款大資料工具彙總(前50款)
Q: 你認為資料科學家還需要具備哪些能力?
歡迎留言與大家分享
請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:hzzy@hzbook.com
更多精彩文章,請在公眾號後臺點選“歷史文章”檢視

