簡介:在您開始閱讀這篇文章之前,我得明確地告訴您,我並不是一個資料庫設計領域的大師。以下列出的 11 點是我對自己在平時專案實踐和閱讀中學習到的經驗總結出來的個人見解。我個人認為它們對我的資料庫設計提供了很大的幫助。實屬一家之言,歡迎拍磚 : )
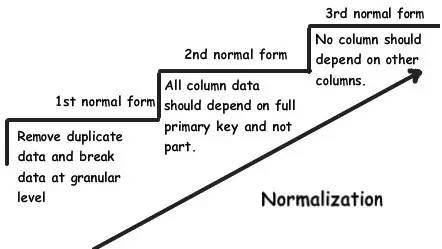
我之所以寫下這篇這麼完整的文章是因為,很多開發者一參與到資料庫設計,就會很自然地把 “三正規化” 當作銀彈一樣來使用。他們往往認為遵循這個規範就是資料庫設計的唯一標準。由於這種心態,他們往往儘管一路碰壁也會堅持把專案做下去。
大家都說標準規範是重要的指導方針並且也這麼做著,但是把它當作石頭上的一塊標記來記著(死記硬背)還是會帶來麻煩的。以下 11 點是我在資料庫設計時最優先考慮的規則。
規則 1:弄清楚將要開發的應用程式是什麼性質的(OLTP 還是 OPAP)?
當你要開始設計一個資料庫的時候,你應該首先要分析出你為之設計的應用程式是什麼型別的,它是 “事務處理型”(Transactional) 的還是 “分析型” (Analytical)的?你會發現許多開發人員採用標準化做法去設計資料庫,而不考慮標的程式是什麼型別的,這樣做出來的程式很快就會陷入效能、客戶定製化的問題當中。正如前面所說的,這裡有兩種應用程式型別, “基於事務處理” 和 “基於分析”,下麵讓我們來瞭解一下這兩種型別究竟說的是什麼意思。
事務處理型:這種型別的應用程式,你的終端使用者更關註資料的增查改刪(CRUD,Creating/Reading/Updating/Deleting)。這種型別更加官方的叫法是 “OLTP” 。
分析型:這種型別的應用程式,你的終端使用者更關註資料分析、報表、趨勢預測等等功能。這一類的資料庫的 “插入” 和 “更新” 操作相對來說是比較少的。它們主要的目的是更加快速地查詢、分析資料。這種型別更加官方的叫法是 “OLAP” 。

那麼換句話說,如果你認為插入、更新、刪除資料這些操作在你的程式中更為突出的話,那就設計一個規範化的表否則的話就去建立一個扁平的、不規範化的資料庫結構。
以下這個簡單的圖表顯示了像左邊 Names 和 Address 這樣的簡單規範化的表,怎麼透過應用不規範化結構來建立一個扁平的表結構。
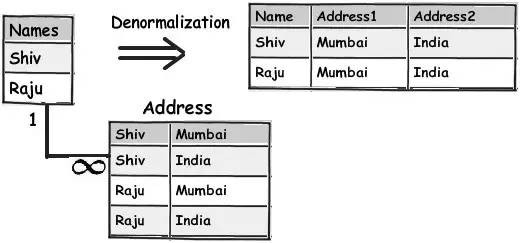
規則 2:將你的資料按照邏輯意義分成不同的塊,讓事情做起來更簡單
這個規則其實就是 “三正規化” 中的第一正規化。違反這條規則的一個標誌就是,你的查詢使用了很多字串解析函式
例如 substring、charindex 等等。若真如此,那就需要應用這條規則了。
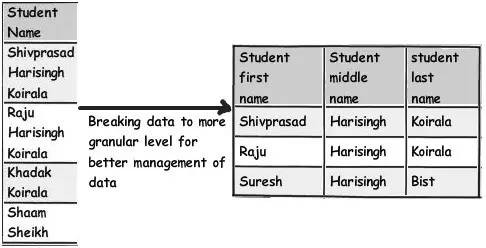
比如你看到的下麵圖片上有一個有學生名字的表,如果你想要查詢學生名字中包含“Koirala”,但不包含“Harisingh”的記錄,你可以想象一下你將會得到什麼樣的結果。
所以更好的做法是將這個欄位拆分為更深層次的邏輯分塊,以便我們的表資料寫起來更乾凈,以及最佳化查詢。
規則 3:不要過度使用 “規則 2”
開發者都是一群很可愛的生物。如果你告訴他們這是一條解決問題的正路,他們就會一直這麼做下去,做到過了頭導致了一些不必要的後果。這也可以應用於我們剛剛在前面提到的規則2。當你考慮欄位分解時,先暫停一下,並且問問你自己是否真的需要這麼做。正如所說的,分解應該是要符合邏輯的。
例如,你可以看到電話號碼這個欄位,你很少會把電話號碼的 ISD 程式碼單獨分開來操作(除非你的應用程式要求這麼做)。所以一個很明智的決定就是讓它保持原樣,否則這會帶來更多的問題。
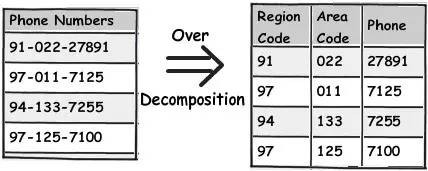
規則 4:把重覆、不統一的資料當成你最大的敵人來對待
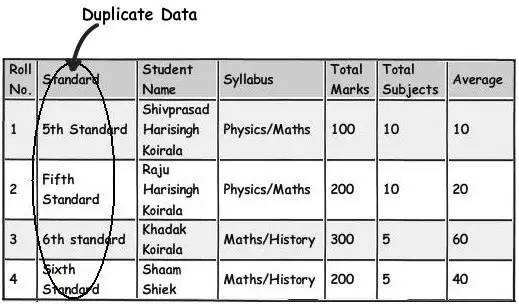
集中那些重覆的資料然後重構它們。我個人更加擔心的是這些重覆資料帶來的混亂而不是它們佔用了多少磁碟空間。
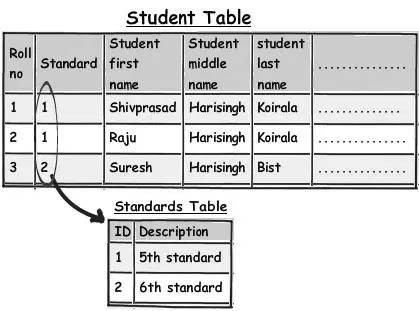
例如下麵這個圖表,你可以看到 “5th Standard” 和 “Fifth standard” 是一樣的意思,它們是重覆資料。現在你可能會說是由於那些錄入者錄入了這些重覆的資料或者是差勁的驗證程式沒有攔住,讓這些重覆的資料進入到了你的系統。現在,如果你想匯出一份將原本在使用者眼裡十分困惑的資料顯示為不同物體資料的報告,該怎麼做呢?
解決方法之一是將這些資料完整地移到另外一個主表,然後透過外來鍵取用過來。在下麵這個圖表中你可以看到我們是如何建立一個名為 “Standards”(課程級別) 的主表,然後同樣地使用簡單的外來鍵連線過去。
規則 5:當心被分隔符分割的資料,它們違反了“欄位不可再分”
前面的規則 2 即“第一正規化”說的是避免 “重覆組” 。下麵這個圖表作為其中的一個例子解釋了 “重覆組”是什麼樣子的。如果你仔細的觀察 syllabus(課程) 這個欄位,會發現在這一個欄位裡實在是填充了太多的資料了。像這些欄位就被稱為 “重覆組” 了。如果我們又得必須使用這些資料,那麼這些查詢將會十分複雜並且我也懷疑這些查詢會有效能問題。
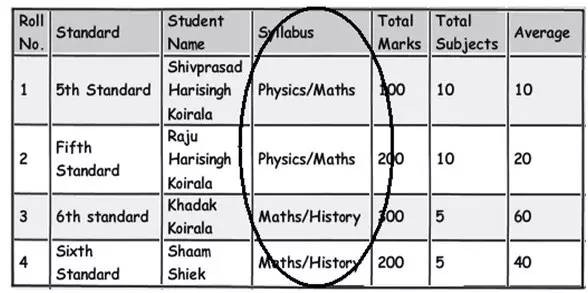
這些被塞滿了分隔符的資料列需要特別註意,並且一個較好的辦法是將這些欄位移到另外一個表中,使用外來鍵連線過去,同樣地以便於更好的管理。
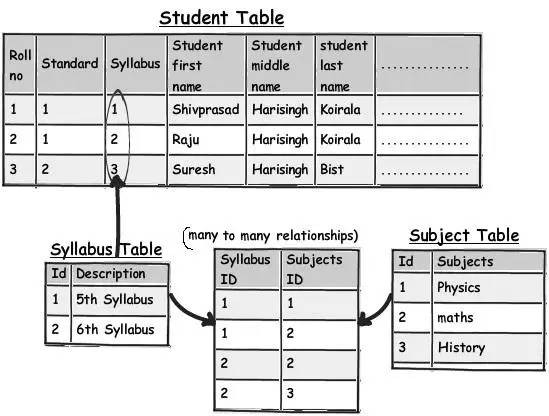
那麼,讓我們現在就應用規則2(第一正規化) “避免重覆組” 吧。你可以看到上面這個圖表,我建立了一個單獨的 syllabus(課程) 表,然後使用 “多對多” 關係將它與 subject(科目) 表關聯起來。
透過這個方法,主表(student 表)的 syllabus(課程) 欄位就不再有重覆資料和分隔符了。
規則 6:當心那些僅僅部分依賴主鍵的列
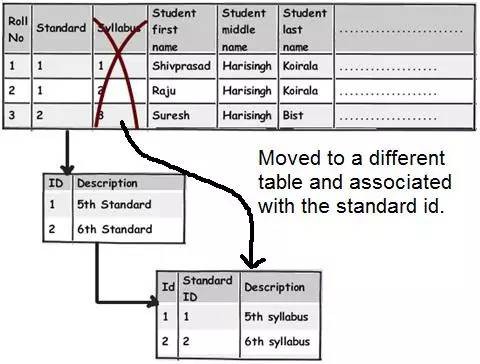
留心註意那些僅僅部分依賴主鍵的列。例如上面這個圖表,我們可以看到這個表的主鍵是 Roll No.+Standard。現在請仔細觀察 syllabus 欄位,可以看到 syllabus(課程) 欄位僅僅關聯(依賴) Standard(課程級別) 欄位而不是直接地關聯(依賴)某個學生(Roll No. 欄位)。
Syllabus(課程) 欄位關聯的是學生正在學習的哪個課程級別(Standard 欄位)而不是直接關聯到學生本身。那如果明天我們要更新教學大綱(課程)的話還要痛苦地為每個同學也修改一下,這明顯是不符合邏輯的(不正常的做法)。更有意義的做法是將這些欄位從這個表移到另外一個表,然後將它們與 Standard(課程級別)表關聯起來。
你可以看到我們是如何移動 syllabus(課程)欄位並且同樣地附上 Standard 表。
這條規則只不過是 “三正規化” 裡的 “第二正規化”:“所有欄位都必須完整地依賴主鍵而不是部分依賴”。
規則 7:仔細地選擇派生列
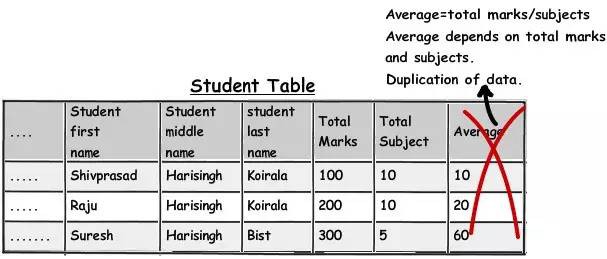
如果你正在開發一個 OLTP 型的應用程式,那強制不去使用派生欄位會是一個很好的思路,除非有迫切的效能要求,比如經常需要求和、計算的 OLAP 程式,為了效能,這些派生欄位就有必要存在了。
透過上面的這個圖表,你可以看到 Average 欄位是如何依賴 Marks 和 Subjects 欄位的。這也是冗餘的一種形式。因此對於這樣的由其他欄位得到的欄位,需要思考一下它們是否真的有必要存在。
這個規則也被稱為 “三正規化” 裡的第三條:“不應該有依賴於非主鍵的列” 。 我的個人看法是不要盲目地運用這條規則,應該要看實際情況,冗餘資料並不總是壞的。如果冗餘資料是計算出來的,看看實際情況再來決定是否應用這第三正規化。
規則 8:如果效能是關鍵,不要固執地去避免冗餘
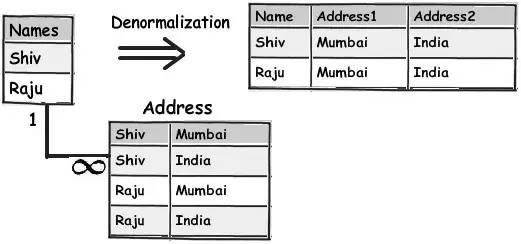
不要把 “避免冗餘” 當作是一條絕對的規則去遵循。如果對效能有迫切的需求,考慮一下打破常規。常規情況下你需要做多個表的連線操作,而在非常規的情況下這樣的多表連線是會大大地降低效能的。
規則 9:多維資料是各種不同資料的聚合
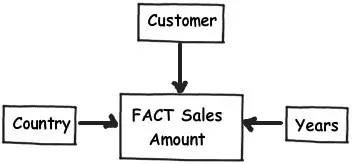
OLAP 專案主要是解決多維資料問題。比如你可以看看下麵這個圖表,你會想拿到每個國家、每個顧客、每段時期的銷售額情況。簡單的說你正在看的銷售額資料包含了三個維度的交叉。
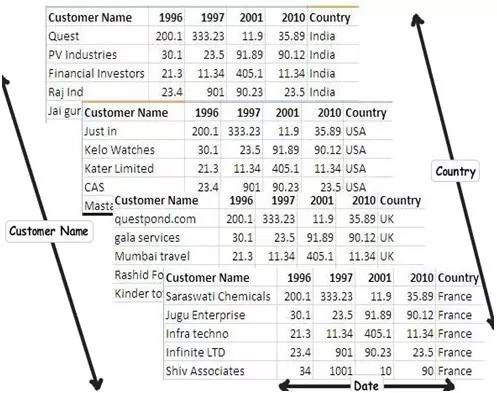
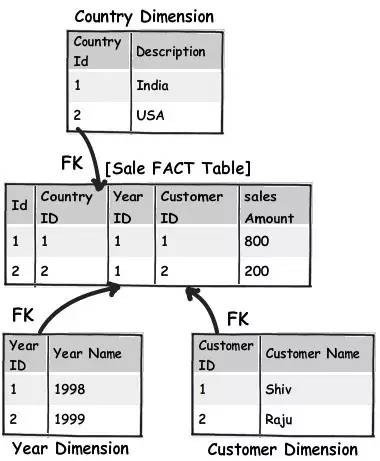
為這種情況做一個實際的設計是一個更好的辦法。簡單的說,你可以建立一個簡單的主要銷售表,它包含了銷售額欄位,透過外來鍵將其他所有不同維度的表連線起來。
規則 10:將那些具有“名值表”特點的表統一起來設計
很多次我都遇到過這種 “名值表” 。 “名值表” 意味著它有一些鍵,這些鍵被其他資料關聯著。比如下麵這個圖表,你可以看到我們有 Currency(貨幣型)和 Country(國家)這兩張表。如果你仔細觀察你會發現實際上這些表都只有鍵和值。
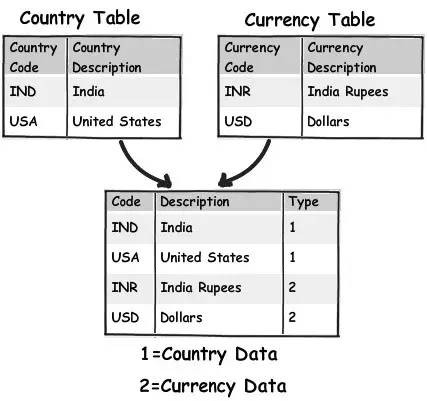
對於這種表,建立一個主要的表,透過一個 Type(型別)欄位來區分不同的資料將會更有意義。
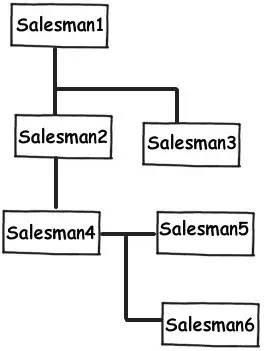
規則 11:無限分級結構的資料,取用自己的主鍵作為外來鍵
我們會經常碰到一些無限父子分級結構的資料(樹形結構?)。例如考慮一個多級銷售方案的情況,一個銷售人員之下可以有多個銷售人員。註意到都是 “銷售人員” 。也就是說資料本身都是一種。但是層級不同。這時候我們可以取用自己的主鍵作為外來鍵來表達這種層級關係,從而達成目的。
這篇文章的用意不是叫大家不要遵循正規化,而是叫大家不要盲目地遵循正規化。根據你的專案性質和需要處理的資料型別來做出正確的選擇。
英文原文:c-sharpcorner,
翻譯:oschina
譯文連結:http://www.oschina.net/question/267865_48311