作者:伯樂線上 – foreach_break
網址:http://blog.jobbole.com/88283/
點選“閱讀原文”可檢視本文網頁版
一、來源
Streaming Hadoop Performance Optimization at Scale, Lessons Learned at Twitter
(Data platform @Twitter)
二、觀後感
2.1 概要
此稿介紹了Twitter的核心資料類庫團隊,在使用Hadoop處理離線任務時,使用的效能分析方法,及由此發現的問題和最佳化手段,對如何使用JVM/HotSpot profile(-Xprof)分析Hadoop Job的方法呼叫開銷、Hadoop配置物件的高開銷、MapReduce階段的排序中物件序列化/反序列的高開銷問題及最佳化等給出了實際可操作的方案。
其介紹了Apache Parquet這一面向列的儲存格式,併成功應用於列投影(column project),配合predicated push-down技術,過濾不需要的列,極大提高了資料壓縮比和序列化/反序列化的效能。
純乾貨。32個zan!
2.2 最佳化總結
1) Profile!(-Xprofile)效能最佳化不能靠猜,而應靠分析!
2) 序列化開銷很大,但是Hadoop裡有許多序列化(操作)!
3) 根據特定(資料)訪問樣式,選擇不同的儲存格式(面向行還是面向列)!
4) 使用column projection。
5) 在Hadoop的MR階段,排序開銷很大,使用Raw Comparators以降低開銷。
註:此排序針對如Comparator,其會引發序列化/反序列化操作。
6) I/O並不一定就是瓶頸。必要的時候要多I/O換取更少的CPU計算。
JVM/HotSpot原生profile能力(-Xprof),其優點如下:
1) 低開銷(使用Stack sampling)。
2) 能揭示開銷最大的方法呼叫。
3) 使用標準輸出(Stdout)將結果直接寫入Task Logs。
2.3 Hadoop的配置物件

1) Hadoop的Configuration Object開銷出人意料的高。
2) Conf的操作看起來就像一個HashMap的操作。

3) 建構式:讀取+解壓+分析一個來自磁碟的XML檔案

4) get()呼叫引起正則運算式計算,變數替換。

5) 如果在迴圈中對上述等方法進行呼叫,或者每秒一次呼叫,開銷很高.某些(Hadoop)Jobs有30%的時間花在配置相關的方法上!(的確是出人意料的高開銷)

總之,沒有profile(-Xprof)技術,不可能獲取以上洞察,也不可能輕易找到最佳化的契機和方向,需要使用profile技術來獲知I/O和CPU誰才是真正的瓶頸。
2.4 中間結果的壓縮
- Xprof揭示了spill執行緒中的壓縮和解壓縮操作消耗了大量時間。
- 中間結果是臨時的。
- 使用lz4方法取代lzo level 3,減少了30%多的中間資料,使其能被更快地讀取。
- 並使得某些大型Jobs提速150%。

2.5 對記錄的序列化和反序列,會成為Hadoop Job中開銷最高的操作!

2.6 對記錄的序列化是CPU敏感的,相對比之下,I/O都不算什麼了!

2.7 如何消除或者減小序列化/反序列化引起的(CPU)開銷?
2.7.1 使用Hadoop的Raw Comparator API(來比較元素大小)
開銷分析:如下圖所示,Hadoop的MR在map和reduce階段,會反序列化map結果的keys以在此階段進行排序。

(反序列化操作)開銷很大,特別是對於複雜的、非原語的keys,而這些keys又很常用。

Hadoop提供了一個RawComparator API,用於對已序列化的(原始的)資料(位元組級)進行比較:

不幸的是,需要親手實現一個自定義的Comparator。
現在,假設資料已序列化後的位元組流,本身是易於比較的:
Scala有個很拉風的API,Scala還有一些宏可以產生這些API,以用於:
Tuples , case classes , thrift objects , primitives , Strings,等等資料結構。

怎麼拉風法呢?首先,定義一個密集且易於比較的資料序列化(位元組)格式:
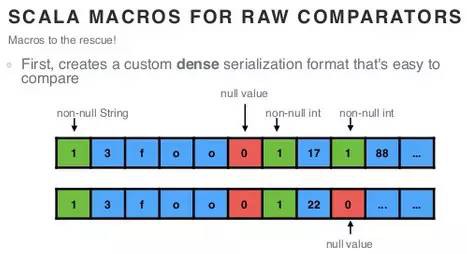
其次,生成一個用於比較的方法,以利用這種資料格式的優勢:

下圖是採用上述最佳化手段後的比較開銷對比:
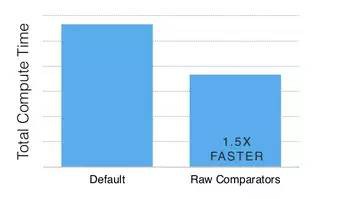
提速到150%!
接著最佳化!
2.7.2 使用column projection
不要讀取不需要的列:

1) 可使用Apache Parquet(列式檔案格式)。

2) 使用特別的反序列化手段可以在面向行的儲存中跳過一些不需要的欄位。
面向列的儲存中,一整列按順序儲存(而不是向面向行的儲存那樣,列是分開儲存的):
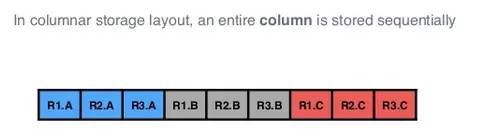
可以看到,面向列的儲存,使得同型別的欄位被順序排在一起(易於壓縮):

採用Lzo + Parquet,檔案小了2倍多!
2.7.3 Apache Parquet
1) 按列儲存,可以有效地進行列投影(column projection)。
2) 可按需從磁碟上讀取列。
3) 更重要的是:可以只反序列化需要的列!

看下效果:
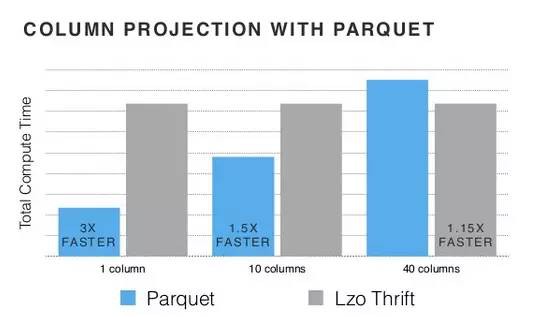
可以看到,列數越少,Parquet的威力越大,到40列時,其效率反而不如Lzo Thrift。
- 在讀取所有列的情況下,Parquet一般比面向行的儲存慢。
- Parquet是種密集格式,其讀效能和樣式中列的數目相關,空值讀取也消耗時間。
- 而面向行的格式(thrift)是稀疏的,所以其讀效能和資料的列數相關,空值讀取是不消耗時間的。

跳過不需要的欄位,如下所示:
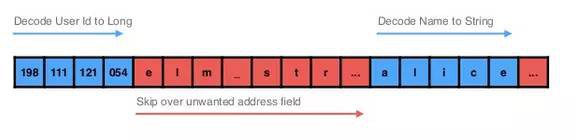
- 雖然,沒有降低I/O開銷
- 但是,可以僅將感興趣的欄位編碼進物件中
- 相對於從磁碟讀取 + 略過編碼後位元組的開銷,在解碼字串時所花的CPU時間要高的多!
看下各種列對映方案的對比:
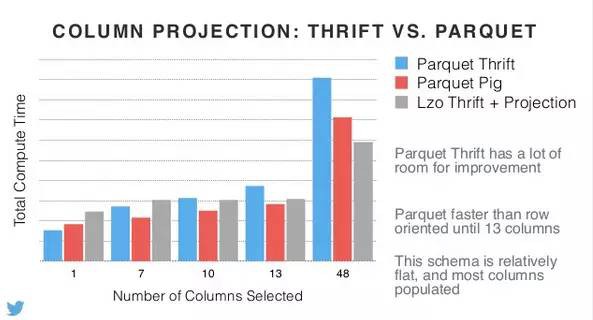
Parquet Thrift還有很多最佳化空間;Parquet在選取的列數小於13列之前,是更快的;此樣式相對平坦,且大多數列都被生成了。
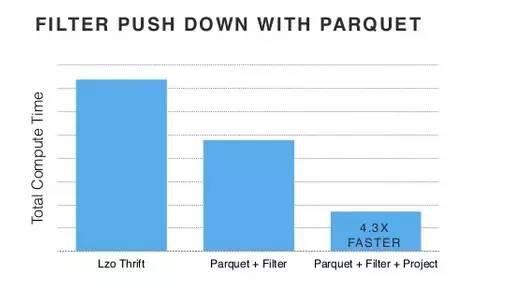
- 還可以採用Predicate Push-Down策略,使得Parquet可以跳過一些不滿足過濾條件的資料記錄。
- Parquet儲存了一些統計資訊,比如記錄的chunks,所以在某些場景下,可以透過對這些統計資訊進行讀取分析,以跳過整個資料塊(chunk)。

註:左圖為column projection,中圖為predicate push-down過濾,右圖為組合效果。可以看到很多欄位被跳過了,那絕壁可以最佳化序列化/反序列化的效率。
下圖則展示了push-down過濾 + parquet的最佳化成效:
2.8 結語
感嘆:Twitter真是一家偉大的公司!
上述最佳化手段,叢集越大、Hadoop Job越多,效果越明顯!